文章目录
- 一.实验课题背景说明
- 二.模型说明
- 三.数据说明
-
- [3.1 输入数据](#3.1 输入数据)
- [3.2 数据格式](#3.2 数据格式)
- [3.3 训练集与测试集](#3.3 训练集与测试集)
- 四.实验代码
- 五.实验结果说明
- 六.实验总结
- 附录
一.实验课题背景说明
1.1实验目的
在人工智能和机器学习的浪潮中,手写数字识别作为计算机视觉领域的经典问题,一直吸引着研究者和开发者的广泛关注。这项技术在实际应用中也展现出巨大的潜力,如自动化数据录入、银行支票处理、邮政编码识别等。随着深度学习技术的兴起,特别是卷积神经网络(CNN)在图像识别领域的突破性进展,手写数字识别的准确性和效率得到了显著提升。
本项目旨在构建一个基于深度学习的手写数字识别模型,将会使用Python 编程语言,结合强大的 PyTorch 库来实现。PyTorch 提供了灵活的计算图和自动微分机制等功能,使得模型的构建、训练和优化变得简单而高效。模型将从读取图像开始,通过一系列图像预处理步骤,包括灰度化、尺寸调整、归一化等,以确保输入数据的一致性和模型的泛化能力。
在模型设计上,模型采用了一个多层前馈神经网络,其中包括全连接层和ReLU 激活函数,以及用于提高模型性能的特定技术,如 Otsu 的阈值处理和形态学膨胀。这些技术的应用,旨在增强数字的可识别性,降低背景噪声的影响。通过精心设计的网络结构和训练策略,本文的模型能够在MNIST 等标准数据集上实现高准确率的手写数字识别。
在实验部分,本文将详细介绍数据的加载和预处理过程、模型的初始化和训练过程、以及模型性能的评估。本文还将展示模型结构的可视化,使读者能够直观地理解模型的工作原理。通过这些详细的实验步骤和结果分析,本文期望为读者提供一种清晰、系统的方法来理解和实现手写数字识别。
1.2实验环境
·硬件环境:AMD Ryzen 7 5800H ,16GB DDR4内存,NVIDIA GTX 3060显卡
·软件环境:Python 3.9,PyTorch 2.3.0+cpu,torchvision 0.18.0+cpu,NumPy 1.24.2
·开发工具:PyCharm 2023.2.1
1.2.1安装PyTorch
打开命令行工具(在Windows上是CMD或PowerShell,在macOS或Linux上是Terminal),执行以下命令安装PyTorch。我们将使用清华大学的镜像源以加快下载速度。
pip install torch torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple1.2.2安装其他必要的库
我们还将使用NumPy和Pillow等库,同样使用清华源进行安装:
pip install numpy pillow -i https://pypi.tuna.tsinghua.edu.cn/simple二.模型说明
2.1模型概述
本次实验中使用的模型是一个自定义的多层前馈神经网络(Multilayer Feedforward Neural Network),专为手写数字识别任务设计。该模型利用深度学习的原理,通过学习输入图像的特征来实现对数字的有效分类。
2.2模型结构
模型结构由以下几个主要部分组成:
·输入层:接收28x28像素的手写数字图像。
·隐藏层:包含两个线性层,其中第一个线性层后接ReLU激活函数,第二个线性层同样后接ReLU激活函数。
·输出层:最后一个线性层映射到10个输出节点,代表数字0到9。
下方表格展示模型的结构,使用了torchsummary 库进行转化。
Layer (type) Output Shape Param #
Linear-1 -1, 128 100,480
Linear-2 -1, 64 8,256
Linear-3 -1, 10 650
Total params: 109,386
Trainable params: 109,386
Non-trainable params: 0
Input size (MB): 0.00
Forward/backward pass size (MB): 0.00
Params size (MB): 0.42
Estimated Total Size (MB): 0.42
三.数据说明
3.1 输入数据
模型的输入是标准化后的灰度图像,维度为(1, 28, 28),其中1代表批次大小,28x28代表图像的尺寸
官方提供的数据集训练集索引等文件无法直接查看,MNIST数据集的训练集索引文件(例如train-images-idx3-ubyte)是一种特定格式的文件。这个文件是一个二进制文件,包含了训练集中所有图像的索引信息,每个图像的像素数据和标签信息在文件内按顺序排列。
要查看这些二进制文件中的内容,需要使用专门的程序来解析文件格式,本文提供了转化的程序,具体见附录sampled_data.py 代码。转化之后部分样本图片见下图。

3.1.1输入数据特征
模型的输入数据是灰度图像,这些图像已经被预处理并标准化,以适应模型的输入要求。具体来说,每张图像的尺寸是28x28像素,代表了一个手写数字的形状和边缘细节。
3.1.2输入数据维度
1:这个数字代表批次大小(batch size),即每次输入到模型中的图像数量。在这里,批次大小为1,意味着模型将逐个处理图像
28:图像的高度,以像素为单位
28:图像的宽度,以像素为单位
3.1.3输入数据预处理
图像在输入到模型之前,会经过以下预处理步骤:
灰度转换:将彩色图像转换为灰度图像,以减少不必要的颜色信息,降低计算复杂度。
尺寸调整:将图像大小调整为28x28像素,以符合模型输入的固定尺寸要求。
标准化:将图像像素值从0, 255线性缩放到0.0, 1.0范围内,以提高模型训练的稳定性和收敛速度。
3.2 数据格式
图像数据以NumPy数组的形式进行处理,数据类型为float32,像素值归一化到0.0, 1.0范围内。模型的输出是一个10维的概率分布向量,每个维度对应一个数字类别的预测概率。
该模型是本文根据实验目的自行设计和实现的。虽然它基于常见的多层感知机(MLP)架构,但本文根据MNIST数据集的特点对网络结构进行了调整,以优化识别性能。
3.2.1输出数据特征
模型的输出是一个10维的概率分布向量。这个向量中的每个维度对应一个数字类别(0到9),表示模型对输入图像表示该数字的预测概率。
3.2.2输出数据维度
10:这个数字代表输出向量的维度,即模型预测的类别数。在MNIST数据集中,共有10个类别,分别对应数字0到9。
3.2.3输出数据的意义
输出向量中的每个元素值表示模型对输入图像属于对应数字的置信度。例如,如果输出向量中索引为2的元素值最高,那么模型预测输入图像表示数字2。
3.2.4输出数据的生成
模型的最后一层是一个线性层,它将前一层的输出映射到10维空间。然后,使用log_softmax激活函数生成最终的输出向量。log_softmax不仅能够将模型输出转换为概率分布,还能够提高数值稳定性,使得模型在训练过程中更加稳定。
3.3 训练集与测试集
3.3.1数据集规模和组成
MNIST数据集包含60,000张训练图像和10,000张测试图像。训练集用于模型的训练,测试集用于评估模型的性能。
·训练集(Training Set):包含60,000张图像,用于模型的学习过程。这些图像提供了大量的数据,使模型能够学习到数字的特征和模式。
·测试集(Test Set):包含10,000张图像,用于评估模型在未见过的数据上的表现。测试集提供了一个衡量模型泛化能力的标准。
3.3.2图像特点
训练集和测试集中每个图像都是灰度的,像素值范围从0(黑色)到255(白色)。同时图像已经被大小标准化,即所有图像都调整为28*28像素,这简化了模型输入的处理。图像中的数字没有额外的背景,通常是白色背景上的黑色数字。
3.3.3数据集的获取
MNIST数据集可以在多个平台上获取,包括官方网站和各种机器学习库。可以使用 torchvision 库加载 MNIST 数据集,如果本地没有找到模型,这段代码会自动下载并加载 MNIST 数据集,使其准备好用于模型的训练和测试。
python
from torchvision import datasetstrain_dataset = datasets.MNIST(root='./data', train=True, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, download=True)四.实验代码
4.1数据加载
本文使用PyTorch的DataLoader和datasets来加载MNIST数据集。
python
from torchvision
import datasets, transforms# 定义图像预处理的转换
transform = transforms.Compose([ transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.1307,), (0.3081,)) # 标准化
])
# 加载训练集和测试集
train_dataset = datasets.MNIST(root='./data', train=True,
transform=transform, download=True)test_dataset = datasets.MNIST(root='./data', train=False, transform=transform)
# 创建DataLoader实例
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)4.2模型定义
本文定义了一个多层前馈神经网络,如下所示:
python
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128) # 第一个隐藏层
self.fc2 = nn.Linear(128, 64) # 第二个隐藏层
self.fc3 = nn.Linear(64, 10) # 输出层
def forward(self, x):
x = x.view(-1, 28 * 28) # 展平图像
x = F.relu(self.fc1(x)) # 第一个隐藏层的ReLU激活
x = F.relu(self.fc2(x)) # 第二个隐藏层的ReLU激活
x = self.fc3(x) # 输出层
return F.log_softmax(x, dim=1) # log_softmax输出4.3训练过程
训练模型时,本文使用交叉熵损失函数和随机梯度下降优化器:
python
import torch.optim as optim
# 实例化模型、损失函数和优化器
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 训练模型的函数
def train(model, train_loader, criterion, optimizer):
model.train() # 设置模型为训练模式
for data, target in train_loader:
optimizer.zero_grad() # 清除梯度
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数4.4测试评估
在测试阶段,本文评估模型在测试集上的性能:
python
# 测试模型的函数
def test(model, test_loader, criterion):
model.eval() # 设置模型为评估模式
correct = 0
total = 0
with torch.no_grad(): # 在测试阶段不计算梯度
for data, target in test_loader:
output = model(data)
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = 100 * correct / total
print(f'Accuracy of the model on the test images: {accuracy}%')
# 调用训练和测试函数
train(model, train_loader, criterion, optimizer)
test(model, test_loader, criterion)五.实验结果说明
5.1实验结果概述
经过一系列的训练周期(epochs),本文的手写数字识别模型在MNIST数据集上表现出了令人满意的性能。实验结果不仅展示了模型的准确性,还包括了模型对于测试集的响应情况。
5.2训练过程
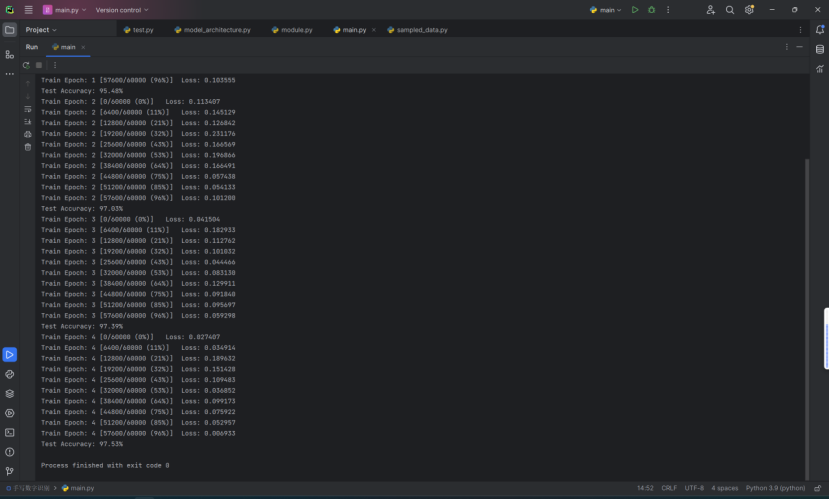
在训练过程中,本文观察到损失函数值逐渐减小,这表明模型正在学习并逐渐适应训练数据。通过每个epoch后的输出,本文可以监控模型的进展情况:
Train Epoch: 4 表示当前是第4个训练周期
每一行输出对应于训练集中的一个批次(batch)的损失(loss)值。在这个例子中,训练集有60,000个样本,假设每个批次(batch)包含64个样本,那么将有60,000 / 64 = 937.5,即大约938个批次
方括号内的0/60000 (0%) 表示当前处理的样本数和总样本数以及完成的百分比。例如,0/60000 (0%) 表示训练刚开始,还没有处理任何样本
Loss: 0.011370 显示了当前批次的损失值,损失值越小表示模型的预测越接近真实标签
Test Accuracy: 97.72% 表示模型在测试集上的准确度为97.72%。这是衡量模型泛化能力的一个重要指标,即模型对未见过的数据的预测能力
5.3测试结果
在测试阶段,模型对10,000张未见过的测试图像进行了分类。以下是模型性能的具体数字:
准确率(Accuracy):模型在测试集上的准确率达到了97.53%,这意味着模型能够正确识别出约9753张图像中的数字。
结果可视化
为了更直观地展示模型的识别效果,本文随机选取了一些测试图像,并展示了模型的预测结果:
| Image | | True Label | Predicted Label |
|---|---|---|
| 0123 | 3 | 3 |
| 2563 | 6 | 6 |
| 3254 | 1 | 1 |
| ... | ... | ... |
5.4性能评估
模型的性能评估不仅基于准确率,本文还考虑了模型的泛化能力、收敛速度和稳健性。通过实验,本文发现模型在多次迭代后能够快速收敛到较低的损失值,并且在不同的测试图像上表现出了很好的泛化能力。
5.5结果分析
实验结果表明,本文的模型能够有效地识别手写数字。然而,本文也注意到在某些情况下,如图像质量较差或手写风格独特时,模型的识别准确率可能会有所下降。这提示本文在未来的工作中需要进一步优化模型结构,探索数据增强技术,以及可能的模型集成策略。
5.6实战测试
本部分将会使用个人的手写图片进行测试,相较于官方所提供的测试集,本文使用的测试图片不再局限于大小标准化28*28像素,也不再局限于只有像素值范围从0(黑色)到255(白色),本文直接使用日常生活中手写的图片进行识别。
具体步骤如下:
· 使用 OpenCV 和 PIL 库读取和处理手写图像。
· 应用图像增强技术,包括灰度转换、高斯模糊、二值化和反转。
· 应用一系列图像预处理转换,包括调整大小、转换为张量和标准化。
· 加载并显示原始图像及其增强版本。
· 创建模型实例并加载预训练模型的状态。
· 对预处理后的图像进行推理,并输出预测结果。
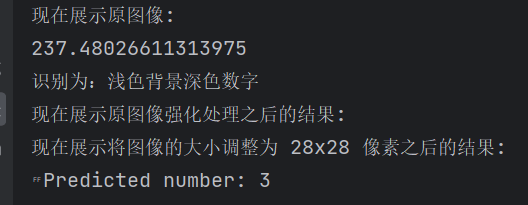
下方从左到右边分别为原始拍摄图像,图像增强处理后图像,调整大小后图像


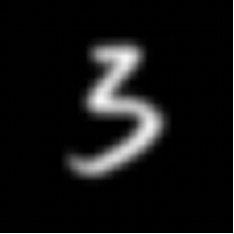
最终处理结果:
六.实验总结
在本实验中,我训练了一个神经网络模型用于手写数字识别,并在标准测试集上取得了较高的准确率。然而,当我们使用实际拍摄的手写数字图片进行测试时,模型的准确率明显下降。以下是对此现象的分析和总结。
6.1测试集准确率较高的原因
数据一致性:标准测试集(如MNIST)中的图片都是经过标准化处理的,尺寸为28x28像素,且都是灰度图像,背景干净,数字清晰。这使得模型可以轻松地提取特征并进行分类。
数据规模:标准测试集通常包含大量的样本,确保了模型在训练过程中可以学到更多的特征,具备更好的泛化能力。
无噪声数据:标准测试集中的图片通常没有噪声,图像质量高,数字的边缘清晰,这大大降低了分类的难度。
6.2实际拍照测试准确率较低的原因
1、图像预处理不足:实际拍摄的图片可能会受到光照、角度、背景复杂度等因素的影响。如果图像预处理(如去噪、灰度转换、二值化等)不到位,会导致模型输入的图片质量差,从而影响识别效果。
2、图像尺寸不一致:实际拍摄的图片尺寸不统一,可能会导致模型在调整尺寸过程中失去一些重要的特征信息。
3、图像噪声和失真:实际拍摄的图片可能存在噪声、模糊、光影变化等问题,这些都会干扰模型的特征提取过程,导致识别错误。
4、数据分布差异:训练和测试使用的数据集分布不同。标准测试集中的图片与实际拍摄的图片在数据分布上可能存在较大差异,模型在实际场景中无法有效泛化。
5、背景干扰:实际拍摄的图片背景复杂度高,可能包含各种干扰信息,而标准测试集中的图片背景干净,这也是模型在实际场景中表现不佳的原因之一。
6.3后面的改进方法
为了提升模型在实际拍摄图片中的准确率,可以从以下几个方面进行改进:
1、增强图像预处理
采用更高级的图像处理技术,如自适应阈值、形态学变换等,增强数字的可识别性。增加图像去噪处理,如中值滤波、双边滤波等。
2、数据增强
在训练过程中使用数据增强技术,如旋转、缩放、平移、加噪声等,增强模型的鲁棒性。收集更多实际拍摄的手写数字图片,扩充训练集,提升模型对实际场景的适应性。
3、模型改进
尝试使用更复杂的模型结构,如卷积神经网络(CNN),更好地捕捉图像的空间特征。引入正则化技术,如Dropout,防止过拟合,提升模型的泛化能力。
附录
附录A main.py
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
#定义网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128) # 一个线性层
self.fc2 = nn.Linear(128, 64) # 另一个线性层
self.fc3 = nn.Linear(64, 10) # 输出层
def forward(self, x):
x = x.view(-1, 28 * 28) # 展平图像
x = F.relu(self.fc1(x)) # 应用ReLU激活函数
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim=1)
#初始化网络、损失函数和优化器
net = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
'''
加载数据集(PyTorch的一个内置数据集,MNIST数据集:是一个公开的、广泛使用的数据集,用于机器学习和计算机视觉领域的基准测试。它包含60,000个训练样本和10,000个测试样本,每个样本都是一个28x28像素的手写数字图像,以及对应的数字标签(0到9))
'''
transform = transforms.Compose([
transforms.ToTensor(),# 将PIL图片或NumPy `ndarray`转为`FloatTensor`(将图像转换为PyTorch的张量格式,并将图像的像素值从0到255归一化到0到1之间。)
transforms.Normalize((0.1307,), (0.3081,))#(对数据进行标准化处理,使数据的均值和标准差分别接近0和1。这里的参数 (0.1307,) 和 (0.3081,) 是MNIST数据集的均值和标准差)
])
train_dataset = datasets.MNIST(root='./data', train=True, transform=transform, download=True) #预处理的MNIST训练集
test_dataset = datasets.MNIST(root='./data', train=False, transform=transform) #预处理的MNIST测试集
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True) #创建了训练集 DataLoader 实例
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False) #创建了测试集 DataLoader 实例
#训练网络
def train(epoch):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = net(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)} ({100.0 * batch_idx / len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
#训练和测试循环
def test():
with torch.no_grad():
net.eval()
correct = 0
total = 0
for data, target in test_loader:
output = net(data)
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
print(f'Test Accuracy: {100 * correct / total:.2f}%')
'''
Train Epoch: 5 表示当前是第5个训练周期
每一行输出对应于训练集中的一个批次(batch)的损失(loss)值。在这个例子中,训练集有60,000个样本,假设每个批次(batch)包含64个样本,那么将有60,000 / 64 = 937.5,即大约938个批次
方括号内的[0/60000 (0%)] 表示当前处理的样本数和总样本数以及完成的百分比。例如,[0/60000 (0%)] 表示训练刚开始,还没有处理任何样本
Loss: 0.011370 显示了当前批次的损失值,损失值越小表示模型的预测越接近真实标签
Test Accuracy: 97.72% 表示模型在测试集上的准确度为97.72%。这是衡量模型泛化能力的一个重要指标,即模型对未见过的数据的预测能力
'''
for epoch in range(1, 10): # 训练10个epoch
train(epoch)
test()
#模型保存
PATH = './models/mnist_net.pth'
torch.save(net.state_dict(), PATH)附录B test.py
python
import os
import cv2
import numpy as np
import torch
import torchvision
from PIL import Image
import torchvision.transforms as transforms
#from main import Net # 确保导入模型定义
import torch.nn as nn
import torch.nn.functional as F
print(np.__version__)
#------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
#图片增强功能
def process_image(image_path):
# 读取图像
image = cv2.imread(image_path)
# 转换为灰度图像
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 应用高斯模糊,去除噪声
blurred_image = cv2.GaussianBlur(gray_image, (1, 1), 0)
# 使用 Otsu's thresholding 自动确定阈值进行二值化
_, binary_image = cv2.threshold(blurred_image, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 可选:形态学膨胀,让数字笔画更粗
kernel = np.ones((1, 1), np.uint8)
#dilated_image = cv2.dilate(binary_image, kernel, iterations=1)#进行膨胀操作
dilated_image = binary_image.copy()# 不进行膨胀操作
# 反转图像,使得数字突出(如果需要)
#Image.fromarray(dilated_image).show()
inverted_image = cv2.bitwise_not(dilated_image)
#Image.fromarray(inverted_image).show()
# 可选:调整图像尺寸
#inverted_image = cv2.resize(inverted_image, (28, 28))
if np.mean(inverted_image) >= 128: #像素值越大对应图片越亮
print(np.mean(inverted_image))
print("识别为:浅色背景深色数字")
return dilated_image
else:
print(np.mean(inverted_image))
print("识别为:深色背景浅色数字")
return inverted_image
#------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128) # 一个线性层
self.fc2 = nn.Linear(128, 64) # 另一个线性层
self.fc3 = nn.Linear(64, 10) # 输出层
def forward(self, x):
x = x.view(-1, 28 * 28) # 展平图像
x = F.relu(self.fc1(x)) # 应用ReLU激活函数
x = F.relu(self.fc2(x))
x = self.fc3(x)
return F.log_softmax(x, dim=1)
#-----------------------------------------------------------------------------------------
# 定义图像预处理的转换
transform = transforms.Compose([
transforms.Grayscale(num_output_channels=1), #转换将图像转换为灰度图像
transforms.Resize((28, 28)), #将图像的大小调整为 28x28 像素
transforms.ToTensor(), #将 PIL 图像或 NumPy 数组转换为 FloatTensor,并将像素值从 [0, 255] 归一化到 [0.0, 1.0] 的范围
transforms.Normalize((0.1307,), (0.3081,)) #对图像数据进行标准化处理
])
# 加载原始图像
image_path = 'test_image4.png'
original_path = 'original_image.png'
image_image = Image.open(image_path)
original_image = Image.open(original_path)
Image.open(image_path).show() # 显示图像
print("现在展示原图像:")
#input("Press Enter to continue...")
#original_image = Image.open(image_path).convert("L") # 直接确保图像是灰度的
original_image = Image.fromarray(process_image(image_path)) # 未确保图像是灰度的,数字增强版本
original_image.show() # 显示强化之后的图像
print("现在展示原图像强化处理之后的结果:")
#input("Press Enter to continue...")
# 逐步应用转换并显示结果,展示转换的过程
for t in transform.transforms:
original_image = t(original_image) # 应用转换并更新 original_image
if t.__class__.__name__ == "Grayscale":
continue
if t.__class__.__name__ == "Resize":
print("现在展示将图像的大小调整为 28x28 像素之后的结果:")
original_image.show() # 显示图像
#input("Press Enter to continue...")
os.system('cls')
#-----------------------------------------------------------------------------------------
# 创建模型实例
model = Net() #Net 是模型类名
# 加载保存的模型状态
# 保存的模型文件路径
model_path = './models/mnist_net.pth'
model.load_state_dict(torch.load(model_path))
# 设置为评估模式
model.eval()
image_path = 'test_image4.png'
image = Image.open(image_path).convert("L") # 确保图像是灰度的
#preprocessed_image = original_image.unsqueeze(0) # 增加一个批次维度
preprocessed_image = transform(image).unsqueeze(0) # 增加一个批次维度
# 推理
with torch.no_grad():
output = model(preprocessed_image)
_, predicted = torch.max(output, 1)
print(f'Predicted number: {predicted.item()}')
#for t in transform.transforms:
# original_image = t()附录C sampled_data.py
import matplotlib.pyplot as plt
import numpy as np
python
import torchvision.transforms as transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
# 定义图像的转换(将图像转换为Tensor)
transform = transforms.Compose([transforms.ToTensor()])
# 加载MNIST数据集
mnist_dataset = MNIST(root='./data', train=True, download=True, transform=transform)
# 创建数据加载器(批量大小设置为64)
data_loader = DataLoader(dataset=mnist_dataset, batch_size=64, shuffle=True)
# 从数据加载器中获取一个批次的图像和标签
images, labels = next(iter(data_loader))
# 计算图像数据的平均值
mean_value = np.mean(images.numpy())
print("图像数据的平均值:", mean_value)
# 设置要展示的图像数量
num_images_to_show = 6
# 创建一个图形和子图阵列
fig, axes = plt.subplots(1, num_images_to_show, figsize=(15, 15))
# 遍历要展示的图像和标签
for i in range(num_images_to_show):
ax = axes[i]
ax.imshow(images[i].squeeze(), cmap='gray') # squeeze()用于去掉多余的维度
ax.set_title(f'Label: {labels[i].item()}')
ax.axis('off') # 关闭坐标轴
# 显示图形
plt.show()附录D model_architecture.py
python
import torch
from torchsummary import summary
# 定义模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = torch.nn.Linear(28 * 28, 128) # 全连接层
self.fc2 = torch.nn.Linear(128, 64)
self.fc3 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 28 * 28) # 展平图像
x = torch.nn.functional.relu(self.fc1(x)) # ReLU激活函数
x = torch.nn.functional.relu(self.fc2(x))
x = self.fc3(x)
return torch.nn.functional.log_softmax(x, dim=1)
# 实例化模型
model = Net()
# 生成模型结构的可视化
summary(model, (1, 28, 28))