本章回答以下问题:
- 什么是 Clos 拓扑,它与"接入 - 汇聚 - 核心"拓扑有何不同?
- Clos 拓扑的特征是什么?
- Clos 拓扑对数据中心网络的影响是什么?
Clos拓扑
云原生数据中心基础设施的先行者们想要构建一种支持大规模水平扩展网络。
基本的Clos拓扑如图2-1所示,一层称为spine(主干交换机),一层称为leaf(叶子交换机)
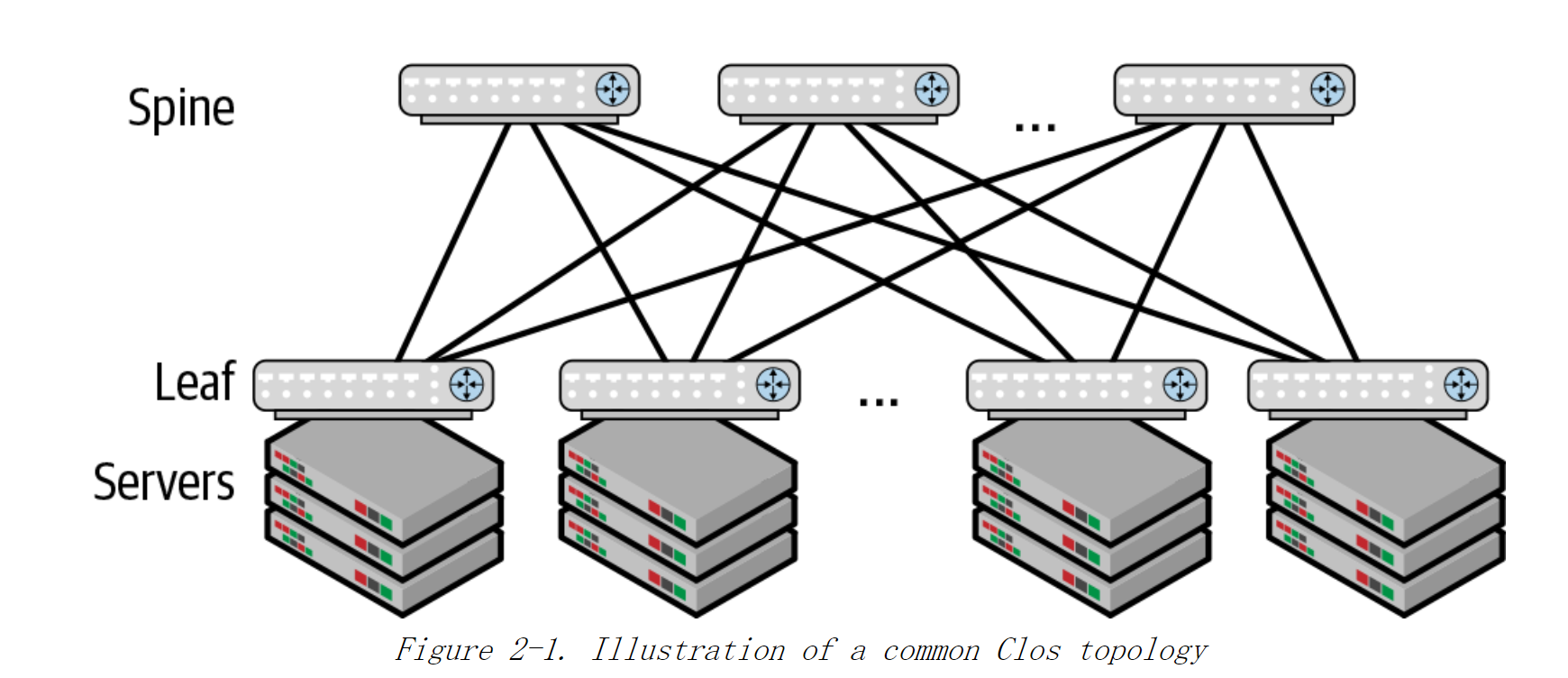
因此该布局也通常被称为 leaf - spine拓扑。
- 每个leaf交换机同时连接到每个spine交换机上。
- leaf交换机之间没有直接连接,而是通过spine交换机进行相互连接。
- 服务器通过leaf交换机连接到网络。
在部署网络时,通常的做法是将服务器和leaf交换机放在同一个机架,并将leaf交换机放在机架的顶部。因此,leaf交换机通常称为架顶交换机(TOR)
因为在任何两台服务器之间都有两条以上的路径,这种拓扑产生了一个高容量的网络。该网络拓扑中添加了更多的 spine 交换机,因此增加了 leaf 交换机之间的可用带宽。
spine交换机只有一个目的:连接不同的leaf交换机。
- 服务器不会直连到 Spine。
- Spine 也不承担其他的功能。因此 Spine 与"接入 - 汇聚 - 核心"类型网络中的汇聚交换机功能并不相同
Clos 拓扑中,所有功能都下沉到了网络边缘的leaf 交换机和服务器节点上,网络中心的 spine 交换机除连接 leaf 交换机之外并不提供任何其他的网络功能。
由于具有水平扩展的架构,Clos 网络可以用一种非常一致的方式进行扩展。 通过添加更多的 leaf交换机和服务器节点,可以增加网络支撑的工作负荷。spine 交换机只用于扩展边缘节点之间的可用带宽。
相比之下,在"接入 - 汇聚 - 核心"类型的网络中网络的扩展是通过增强汇聚交换机的CPU来实现的,这样的架构称为垂直扩展架构。
图2-2 经典的三阶段Clos 拓扑

使用同类设备
通过这种拓扑,Charles Clos 使得构建非常大型的电信级网络变得更经济,因为可以使用相对较小的交换机来构建网络。 以类似的方式,采用 Clos 拓扑结构,我们可以使用简单的盒式交换机 (这种交换机的功能是固化的,出厂后不能通过扩展模块进行升级)来构建非常大型的分组交换网络。
路由作为基本的互连模式
"接入 - 汇聚 - 核心" 网络的一个基本限制是只能支持两个汇聚交换机。
Q: Clos 拓扑如何才能支持两个以上的 Spine 交换机?
A: 在Clos 拓扑中没有使用生成树协议 (STP) 作为交换机之间的互连控制协议。在 Clos 网络中:
- 仅在网络边缘 (即在单个机架内) 直接支持桥接。
- 跨机架的桥接,使用例如虚拟可扩展局域网 (VXLAN)的网络虚拟化解决方案。(重点掌握)
Q: 那路由方式(routing)到底是如何支持多台 Spine 的呢?
A: 通过 ECMP (Equal-Cost Multipath,等价多路径)路由实现。现在几乎每种数据转发芯片都支持IP路由,并且 IP路由和桥接的成本,延迟和带宽几乎相同,消除了对IP路由速度较慢的担忧。ECMP 允许沿着多个等价路径中的任何一个路经转发数据包。例如,在图 2-1 中,一个leaf交换机可以使用任意 spine 交换机连接到任何一个其他 leaf 交换机,并且连接到任何一个 leaf 交换机的代价是相同的。
因此,基本上来说,Clos 拓扑使用了路由而不再是桥接来作为主要的数据包转发模式。
Clos拓扑中的收敛比
在分组交换网络中,交换机的收敛比被定义为下行链路和上行链路带宽之比。
在leaf交换机层面,下行链路是面向服务器节点的连接,而上行链路是面向spine交换机的连接。
1:1的收敛比意味着下行总带宽等于上行总带宽。
大部分数据中心都会确保Clos网络中的高层具有1:1的收敛比。在三层或四层Clos网络中,可能只在leaf级别不是1:1的收敛比。
采用1:1的收敛比的网络也被称为非阻塞网络
假设spine和leaf都是n端口交换机且所有的n个端口都具有相同的带宽,并采用
1:1的超额订阅比,则图2-1中的Clos拓扑可连接的最大服务器数量为 n 2 / 2 n^2/2 n2/2推导如下:
leaf上端口数量为 n / 2 n/2 n/2,spine数量为 n / 2 n/2 n/2,leaf最大数量 = n × n / 2 n / 2 = n \frac{n \times n/2}{n/2}=n n/2n×n/2=n
可连接的最大服务器数量= n × n / 2 = n 2 / 2 n \times n/2 = n^2/2 n×n/2=n2/2
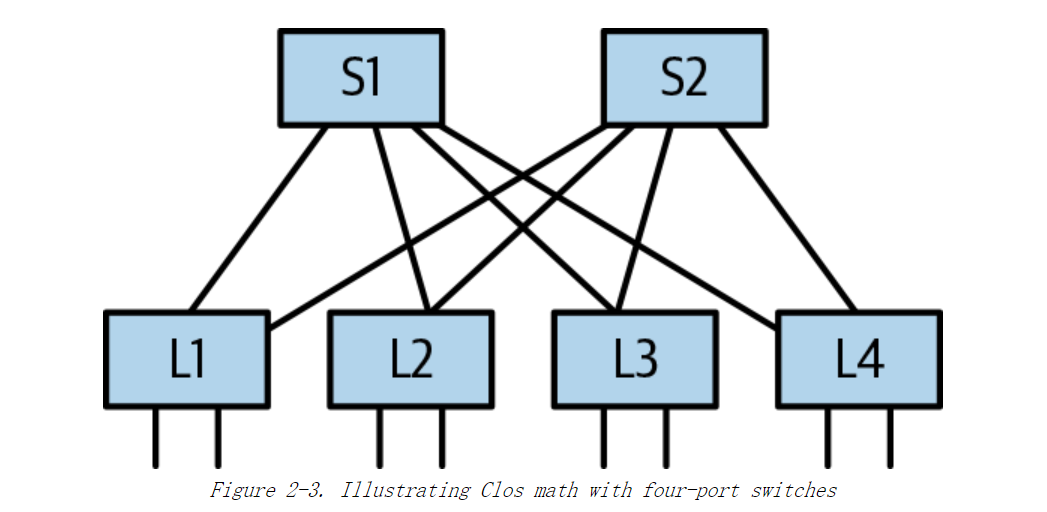
假设图2-3中所有交换机都是四端口交换机,leaf交换机L1到L4各有两个连接到服务器的端口,以及和每个spine交换机连接的一个端口,可连接的服务器总数为 4 × 4 / 2 = 8 4 \times 4 /2 = 8 4×4/2=8。如果使用 64 端口交换机,则可连接的服务器总数为 6 4 2 / 2 = 2048 64^2/2 = 2048 642/2=2048台。
在一个使用n端口交换机的完全展开的二层Clos拓扑中,一共需要 n + n / 2 n + n/2 n+n/2台交换机。
尽管 2048 台服务器足以满足大多数中小型企业的需求,但这种设计号称能支持成万甚至数十万台服务器,如何才能实现呢? 书中将在"扩展 Clos 拓扑"中进行说明。
需要补充的是,采用 1:1 收敛比的网络也称为非阻塞网络 (从技术上讲,它实际上是非竞争性的),因为理论上从一个下行链路到一个上行链路的流量不需要与来自其他下行链路的流量进行竞争。**但是,即使超额订阅比为 1:1,Clos 拓扑在技术上也只能是可重排的无阻塞,而不是完全无阻塞。**在某些流量模式下,流的哈希算法可能导致来自不同下行链路的数据包使用相同的上行链路(如"流和拥塞"中所述) 。如果可以对使用同一上行链路的来自不同下行链路的流重新排列,以使这些流使用不同上行链路,则可以使网络再次畅通无阻。因此,这被称为可重排的非阻寒。
流和拥塞
当到目的地的下一跳节点超过一个时,路由器可以随机选择一个节点来转发教据包,或者选择一个节点以确保属于同一个流的所有数据包都使用相同的下一个节点。一个流大致定义为一组相关的数据包。
最常见的是TCP或UDP的流定义,对这两种协议,一个流定义为源IP地址、目标IP地址、4层协议类型 (TCP或UDP) 、源端口和目标端口组成的五元组。 其他协议的数据包对于流也有相应的定义。
识别一个流的主要原因是为了确保与该流相关的协议正常运行。如果节点使用不同的网络路径转发相同流的多个数据包,则这些数据包可能以与发送顺序不同的顺序到达目的地。这种无序交付会严重影响协议的性能,进而影响使用该协议的应用程序的性能。但在另一方面,确保最大化利用所有可用网络带宽也很重要,即尽量使用所有可以到达目标的网络路径。每个网络节点都会基于这两点进行平衡,以做出转发决策。
为确保一个流的所有数据包都采用相同的下一跳 ,路由器 (硬件或软件) 使用了基于流的哈希算法。这意味着路由器会根据数据包的头信息和一些其他信息,例如来源的交换机端口,为每个数据包计算一个哈希值。然后使用该哈希值的某些固定字节对可用下一跳节点个数取模,以计算该数据包使用的下一跳节点 。这种计算流的下一跳的方法使路由器能够确保一个流的所有数据包都采用相同路径进行转发,而无需在路由器中为每一个流单独保存状态。
需要理解的一个重要因素是,虽然对流进行哈希可以保证流在链路上均匀分布,但对应到数据包的分配并不均匀,这是因为不同的流中有不同数量的数据包。这意味着尽管网络中的流均匀分布,但总带宽的利用并不均匀。这种情况导致了链路拥塞,特别是在某些流中包含的数据包远超过合理数量的情况下。包含较多数据包的流称为大象流,而数据包相对较少的流称为老鼠流。网络表现出经典的重尾分布形态,一部分流占用了绝大部分的网络带宽。当多个大象流被分配在同一链路上时,将引起网络拥塞,并影响该链路上的老鼠流。这就是所谓的象 - 鼠(elephant-mice) 问题。
即使没有象 - 鼠问题,在某些特定的流量模式下,流哈希算法也可能导致某些链路相对于其他链路更偏向于被用于转发。这种不平衡的上行链路利用率被称为流量极化。大多数数据转发芯片都有更改其哈希算法参数的功能,以缓解或消除流量极化。
互连链路速率
常见的Clos模型部署在服务器链路使用一种速率,而交换机间链路(ISL, inter-switch link)则使用更高的速率。使用高速上行链路的主要原因是,可以使用更少的spine交换机来支持相同的收敛比。
目前为止,只有极少数大型数据中心运营商在网络中使用等速上行链路。
这样的好处是:
-
即使使用端口较少的交换机,也可以构建很大的网络。(最主要的原因)
-
更好的负载均衡。
根据上一节中的示例,使用较低速率的交换机意味着该网络中可以使用 54 个10GbE的10端 spine 交换机,而不是16个40GbE的32端口交换机(32个 40GbE 端口中的一半)。由于下一跳数量由 16 个增加到 54个,大大降低了象 - 鼠问题的风险。
-
更多的交换机意味着在链路或 spine 交换机发生故障时,受到影响的故障域更小
一些现实的限制
前面部分的数字是根据理论计算出来的,并不完全符合实际情况。实际与理论不符的原因与 Clos 拓扑无关,而是与设备散热,机架大小标准,服务器摆放和交换芯片技术等的技术限制有 关。
最常见的是每个机架上20台或40台服务器

以图2-4 左为例,假设每个机架上有40台服务器,使用一个有64个10GbE端口的交换机连接这写服务器,在交换机上还有24个空闲端口。
如果仅将其中20个用于上行链路,这上行链路带宽为200GbE,收敛比为 400 : 200 = 2 : 1 400:200 = 2:1 400:200=2:1
在二层Clos网络中,可以连接 64 × 40 = 2560 64 \times 40 = 2560 64×40=2560个服务器,大于理论上的2048台服务器( 64 × 64 / 2 64 \times 64 /2 64×64/2)
假设spine和leaf都是64端口的设备,因为spine要连接到每一台leaf,因此leaf最多64台,spine为20台
以图2-4 右为例,将24个10GbE端口合并为6个40GbE端口组成一个4-spine交换机网络,则收敛比为 400 : 160 = 2.5 : 1 400:160 = 2.5:1 400:160=2.5:1
由于大部分企业中的服务器不支持40GbE或100GbE的端口,因此一些40GbE或100GbE的端口会被拆分为10GbE或25GbE的端口,并使用这些端口连接到服务器。假设面向服务器的连接速率为25GbE,每个机架不超过40台服务器,则需要10个100GbE的连接服务器的端口(10 x 100 = 25 x 40),对于1:1的收敛比,需要10个100GbE的连接spine的端口,一共使用leaf上的20个端口,会导致交换机上有很多未使用的端口。因此,有些资源少的组织会部署双连接服务器,以利用40个面向服务器的端口。
简而言之,尽管数据中心运营商希望使用端口数量较多的交换机来构建更大的网络,但他们也想在 leaf 节点使用端口数量较少的交换机。为了满足这些需求,交换机设备供应商通常会提供两种(如果不是更多的话)交换机设备类型,一种用于spine节点,一种用于 leaf 节点。
细粒度的故障域
如果有2个以上的spine交换机,则单个链路或spine节点的故障不会造成灾难性的后果。
对于有16台spine交换机的网络,单个spine节点或链路故障只会导致总带宽减少 1 / 16 1/16 1/16。
考虑一个具有n台spine交换机( S 1 − S N S_1-S_N S1−SN)和m台leaf交换机( L 1 − L M L_1-L_M L1−LM)的网络拓扑。
假设当L1和S1之间的链路发生故障时,所有其他leaf交换机将停止采用从S1来到L1。对于已经到达S1,但需要发送到L1的流量,可以通过L2和S2发送到L1。
尽管在leaf和spine之间跳转的流量会导致这些leaf交换机的链接发生拥塞,但是与STP不同,路由协议将故障链路的影响仅限制在连接到该链路的节点上。
拓展Clos拓扑
本节中,假设每层之间的收敛比都为
1:1,只有最底层除外。

图2-5(b)中,使用四端口交换机构建了一个可以连接16台服务器的三层Clos网络。
将原本二层Clos网络中的leaf交换机下再接入一层交换机,将虚线框看作一个二层交换机。
作者称之为虚拟机箱模型
One way to build a three-tier Clos topology is to take the two-tier Clos topology of Figure 2-5(a) but instead of attaching servers directly to the leaves, create another tier by attaching another row of switches.
The model in Figure 2-5(b) is a three-tier model popularized by Facebook. I call this the virtual chassis model because some vendors build a single large chassis-based switch that houses the two layers represented by the dashed box (see "A Different Kind of Chassis for Clos" for more details).
图2-5(c)中,将二层Clos拓扑中的spine交换机拿出两个端口,并将它们连接到另一层交换机(SS1-SS4)
该模型通常称为pod或集群模型。
虚线中的交换机原来属于二层Clos交换拓扑,现在将这些交换机每4个组成一个单元,通常称为pod或集群。
连接这些pod的新的一层交换机在本书中称为"超级spine交换机"
The new layer of switches that connects the pods is called by different names: some refer to this tier as super-spine switches or inter-pod spine switches, whereas others just relabel the three tiers in which the spine becomes the top-most tier, and what we called spine-leaf in the two-tier Clos topology becomes leaf-ToR in the three-tier Clos topology. In this book, we follow the leaf, spine, super-spine terminology.
类似二层Clos的公式,由n端口交换机组成的三层Clos网络可以支持的服务器数量为 n 3 / 4 n^3/4 n3/4。
对于64端口交换机,可与支持的服务器总数为 6 4 3 / 4 = 65536 64^3/4=65536 643/4=65536
该公式对以上两种建立Clos网络的方式均成立
一个完全展开的三层Clos拓扑中所需的交换机总数为: n + ( n 2 ) n+(n^2) n+(n2)
以Pod模型为例,每个Pod中的spine交换机的数量为端口数的一半 n/2(虚线框中的S11、S12)
每个spine交换机支持的leaf交换机数量也为 n/2(虚线框中的L11、L12)
因此每个Pod中有n个交换机
超级交换机的数量 = 交换机端口数量n
最多连接n个Pod,即每一个超级交换机都挂接到一个由n个Spine交换机组成的网络中
两种三层模型的比较
这两种模型在流量上的均匀程度有所不同
虚拟机箱模型整个网络的通信延迟更为一致
pod模型,pod内和跨pod的服务器通信存在两种截然不同的延迟。
提供云服务并需要本地化客户实力的数据中心运营商更倾向于使用pod模型。
在pod模型中,如果大多数流量都在pod内部,则开始构建网络时可以之部署较少的超级交换机。
Clos网络的最佳实践
交换机之间不使用多链路

图2-6(b)中,如果L2到S1之间的一条链路发生故障,从L1的角度来看,它仍然能看到通往L2的两条等价路径,导致它想S1和S2发送相同数量的去往L2的流量,然而,S1的带宽实际只有S2的half,这导致一些随机的流遭受分组丢失增加或等待时间延长。
如果将两条链路绑定在一起,则不同的路由协议也不能很好的支持。
If the two links are treated as a bond, the behavior is different with different routing protocols. In Border Gateway Protocol (BGP), we can use a feature called link bandwidth extended community to send proportional traffic to S1 and S2, but the way to make this work in the presence of multiple links and link failures is not commonly supported. Using Open Shortest Path First (OSPF) or Intermediate System to Intermediate System (IS-IS), the link failure would result in a drop in cost of the link, and L1 would simply stop using S1 as a path to L2. So OSPF and IS-IS cannot handle this, either.
因此,不要考虑使用多个链路增加带宽,而是通过增加其他的spine和leaf节点来增加带宽,并使这些节点的链路数量保持一致。
spine交换机只用于连接
保留细粒度的故障域,降低发生拥塞的风险。
不使用框式交换机作为spine交换机
框式交换机是一种模块化的硬件,其内部有多个交换线卡以及一个或多个主控板卡。一个交换线卡上有多个交换端口。机箱内所有的交换线卡均通过一个专用背板或交叉连接。这种内部交叉连接的一个常用称呼是 crossbar。"接入 - 汇聚 - 核心"网络中的汇聚交换机通常是这框式交换机。
当框式交换机发生故障时,其故障原因更复杂,从而使故障定位变得更加困难。
使用框式交换机的另一个顾虑是,它使原本简单的资产管理变得复杂。
应当使用盒式交换机。
主机连接模式(Host Attach Models)
在现代数据中心中,带有一个或两个网卡的主机最为常见。
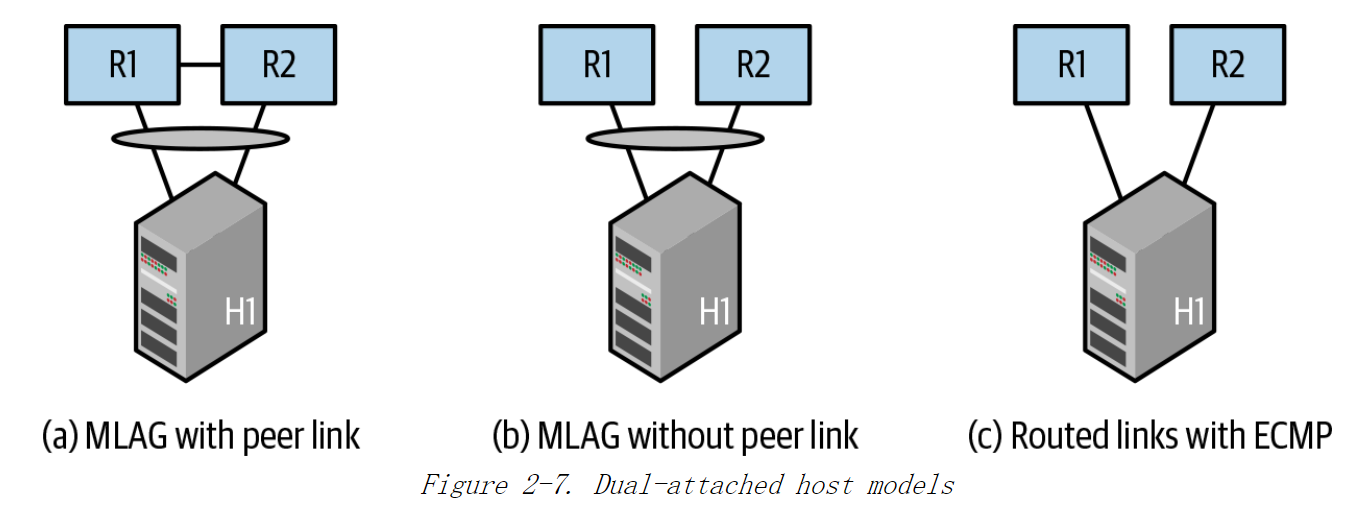
服务器要么通过单个连接点连接到一个leaf交换机上,也可以是如图2-7所示的双连接,两个网卡分别连接到两个不同的leaf交换机上。使用双连接的主要原因是,如果一个leaf交换机因计划维护或故障而下线,运营商甚至无法承受影响一个服务器机架的损失。这种情况通常发生在较小的数据中心。
当主机为双连接时,一些运营商选择仅在主备模式下使用;也就是说,一次只有一个链接处于活动状态。在这种情况下,运营商只关心确保链路故障不会切断服务器与网络的连接。但大多数运营商更喜欢同时使用这两个链路。在这种情况下,有三种可能的模型:
1)最常见的方式是将主机上的两个连接进行绑定(也称为port-channel或链路聚合)。如图2-7(a)所示。
从主机端来看,它看起来像一个标准的IEEE 802.3ad协议定义的链路绑定。
在交换机方面,最常见的方法是使用通常称为MLAG的供应商专有协议。该协议可以让主机认为它通过绑定(或port-channel)连接到单台交换机。
2)当MLAG与以太网VPN(EVPN)等网络虚拟化技术结合使用时,连接主机的两个leaf交换机之间可能不存在连接,如图2-7(b)所示。
3)主机通过路由使得其在对外转发流量时同时使用这两个连接。如图2-7(c)所示。