一、概念
1.K-近邻算法:也叫KNN 分类 算法,其中的N是 邻近邻居NearestNeighbor的首字母。
(1)其中K是特征值,就是选择离某个预测的值(例如预测的是苹果,就找个苹果)最近的几个值,邻近的意思也很简单,就是距离上最近,距离测算主要分两种。
实际情况就是点的x,y这些值就是这个点的特征,一样的事物最后在坐标轴上位置离得很近,而你把预测值放进去,它离哪个近,可不就是哪个玩意嘛。
如果有几个类挨得特别近,就根据少数服从多数的投票法则,洒洒水啦~
(2)欧氏距离和曼哈顿距离:
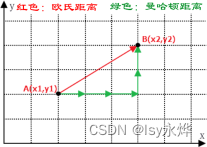
2.K值大小的影响:
(1)K过小:造成过拟合,因为样本过少,所以看山是山。
(2)K过大:造成欠拟合,因为样本过多,假设判断的是人种,那么多都是人,那猿猴也有人的特征,很容易就也被归类到人里面了。
3.离差标准化(了解即可):
当x,z都是两位数的时候,加入y是五位数,那此时y对距离的影响达到了非常大,所以要对其进行标准化,有三种:

4.简单说一下代码:

二、习题
单选题:
2、关于k-近邻算法说法错误的是( D)
A k-近邻算法是机器学习
B k-近邻算法是监督学习
C k代表最近的K个样本
D k的选择对分类结果没有影响
3、关于k-近邻算法说法错误的是( B)
A k-近邻算法可以用来解决回归问题
B 随着k值的增大,决策边界会越来越复杂
C 一般使用投票法进行分类任务
D 距离计算方法不同,效果也可能有显著差别
多选题:
- K-近邻算法的基本要素包括(ABD )。
A、距离度量 B、K值选择 C、样本大小 D、分类决策规则
判断题:
- 最近邻算法中,样本的预测结果只由训练集中与其距离最近的那个样本决定。( )
PS:老师的答案是对,但是我搜的是错的。。。。