文章目录
概要
Hive是基于Hadoop的数据仓库工具。可以用于存储在Hadoop集群中的HDFS文件数据集进行数据整理、特殊查询和分析处理。Hive提供了类似于关系型数据库SQL语言的HiveQL工具,通过HQL(HiveQL)可以快速实现简单的MapReduce统计。
整体架构流程
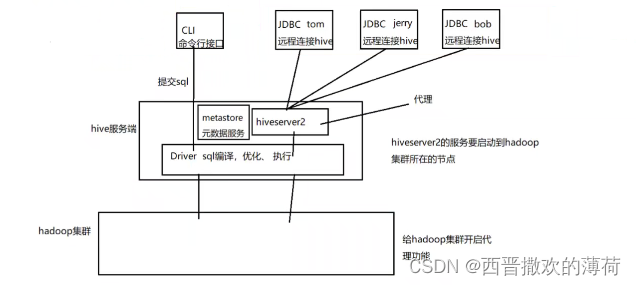
Hive服务端组件:
- Driver组件:该组件包括Complier(编译)、Optimizer(优化)和Executor(执行),它的作用是将HiveQL(类SQL)语句进行解析、编译优化、生成执行计划,然后调用底层的MapReduce计算框架。
- Metastore组件:元数据服务组件,这个组件用于存储Hive的元数据,Hive的元数据存储在关系数据库里,Hive支持的关系数据库有Derby和Mysql,它的作用是客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。
- HiveServer2服务:用来进行可扩展且跨语言的服务的开发,Hive集成了该服务,能让不同的编程语言调用Hive的接口,还可做权限管理。
客户端组件:
- CLI:Command Line Interface,命令行接口。
- JDBC/ODBC:Hive架构的JDBC和ODBC接口是建立在HiveServer2客户端之上。
- WEBGUI:Hive客户端提供了一种通过网页的方式访问Hive所提供的服务。这个接口对应Hive的HWI组件,使用前要启动HWI服务。
Hive数据库操作
- 创建数据库
CREATE DATABASE IF NOT EXISTS database_name
COMMENT database_comment
LOCATION hdfs_path
WITH DBPROPERTIES (property_name=property_value, ...);
其中:WITH DBPROPERTIES ,用来指定数据属性数据。
powershell
--创建带有属性的数据库
create database testdb WITH DBPROPERTIES ('creator' = 'tp', 'date' = '2024-06-12');
--显示创建语句
show create database testdb;
--显示所有数据库
show databases;- 删除数据库
DROP DATABASE IF EXISTS database_name RESTRICT\|CASCADE;
注:
- RESTRICT:严格模式,若数据库不为空,则会删除失败,默认为该模式。
- CASCADE:级联模式,若数据库不为空,则会将库中的表一并删除。
建表语法
powershell
-- EXTERNAL 代表外部表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
-- 分区表设置 分区的字段和类型
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
-- 桶表设置 按照什么字段进行分桶
[CLUSTERED BY (col_name, col_name, ...)
-- 桶内的文件 是按照 什么字段排序 分多少个桶
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
-- 分隔符 + 序列化反序列化
[ROW FORMAT row_format]
-- 输入输出格式
[STORED AS file_format]
-- 表所对应的hdfs目录
[LOCATION hdfs_path] 表分类
- 内部表
内部表又称受控表,当删除内部表的时候,存储在文件系统上的数据(例
如HDFS上的数据)和元数据都会被删除。先有内部表,再向表中插入数据
powershell
--创建inner_test表(内部表)
CREATE TABLE inner_test(word string, num int); 删除内部表,表对应的hdfs目录也一并删除
powershell
-- 创建emp职工表(内部表)
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';- 外部表
创建外部表需要使用EXTERNAL关键字,当删除外部表的时候,只删除元
数据,不删除数据。
使用场景,例如:某个公司的原始日志数据存放在一个目录中,多个部
门对这些原始数据进行分析,那么创建外部表就是比较好的选择了,因为即
使删除了外部表,原始数据并不会被删除。
- 分区表
分区表是为了防止暴力扫描全表,提高查询效率。分区字段在源文件中是
不存在的,需要在添加数据的时候手动指定。
每一个分区对应一个目录。通过partitioned by来在创建分区表的时候添
加分区字段。分区表可以是内部表,也可以是外部表。
使用场景:可以通过分区表,将每天搜集的数据进行区分,查询统计的时
候通过指定分区,提高查询效率。
- 分桶表
桶是比表或分区更为细粒度的数据范围划分。针对某一列进行桶的组织,对列值哈希,然后除以桶的个数求余,决定将该条记录存放到哪个桶中。