一、研究背景和意义
随着汽车保有量的不断增加,交通事故已成为全球范围内的重大公共安全问题。每年因交通事故造成的人员伤亡和财产损失给社会带来了巨大的负担。为了提高驾驶安全,减少交通事故的发生,许多研究致力于探索影响驾驶安全的因素,并开发相应的预测模型。
机器学习作为一种强大的数据分析工具,在驾驶安全领域得到了广泛的应用。通过对大量驾驶安全数据的学习和分析,机器学习算法可以自动发现数据中的模式和规律,并建立预测模型,以预测驾驶员的行为和事故风险。
研究意义:
- 提高驾驶安全:通过预测驾驶员的行为和事故风险,提前采取相应的措施,如发出警告、调整驾驶策略等,可以有效地减少交通事故的发生,提高驾驶安全。
- 优化交通管理:驾驶安全预测模型可以为交通管理部门提供决策支持,帮助他们优化交通流量、改善道路设施、加强交通安全宣传等,从而提高整个交通系统的安全性和效率。
- 推动智能驾驶技术的发展:驾驶安全预测是智能驾驶技术的重要组成部分。通过对驾驶安全数据的分析和预测,可以为智能驾驶系统提供实时的驾驶建议和决策支持,推动智能驾驶技术的发展和应用。
- 降低保险成本:保险公司可以利用驾驶安全预测模型来评估驾驶员的风险水平,从而制定个性化的保险费率,降低保险成本。
- 促进社会和谐发展:交通事故不仅给个人和家庭带来了巨大的痛苦和损失,也对社会的和谐发展造成了负面影响。通过提高驾驶安全,减少交通事故的发生,可以促进社会的和谐发展。
综上所述,使用机器学习方法对驾驶安全数据进行预测具有重要的研究背景和意义。它不仅可以提高驾驶安全,减少交通事故的发生,还可以为交通管理、智能驾驶技术、保险等领域提供有益的支持,促进社会的和谐发展。
二、实证分析
首先读取数据集
python
#####导入基础的数据处理包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
python
# Load the dataset
df = pd.read_csv("train.csv")查看数据集前五行
python
###查看数据
df.head()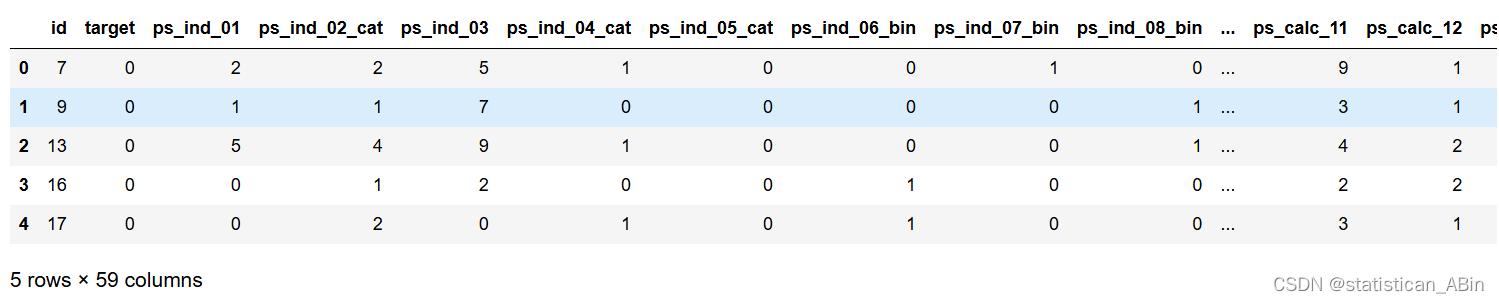
可以发现每个样本有59个特征
接下来查看数据类型
python
df.shape
发现数据量为595212*59,数据量挺大,这可能对最终的模型计算产生一些阻碍。接下来查看数据类型
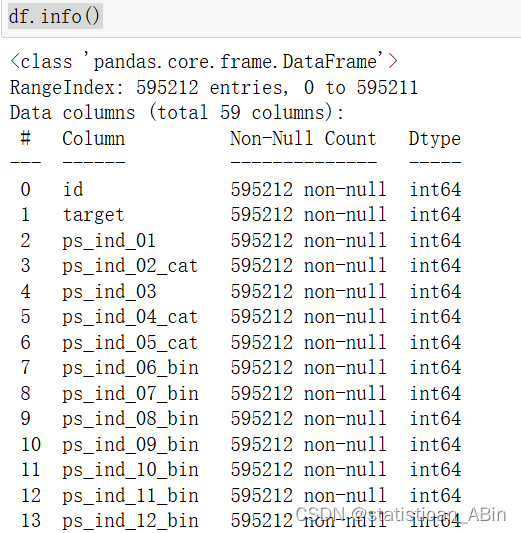
接下来进行数据预处理,对其他行列进行处理,首先若是一行全为空值就删除
python
###对列进列进行处理。如果有一列的值全部一样,也就是取值唯一的特征变量就可以删除了,因为每个样本没啥区别,对模型就没啥用
#取值唯一的变量删除
for col in df.columns:
if len(df[col].value_counts())==1:
print(col)
df.drop(col,axis=1,inplace=True)
#缺失到一定比例就删除
miss_ratio=0.15
for col in df.columns:
if df[col].isnull().sum()>df.shape[0]*miss_ratio:
print(col)
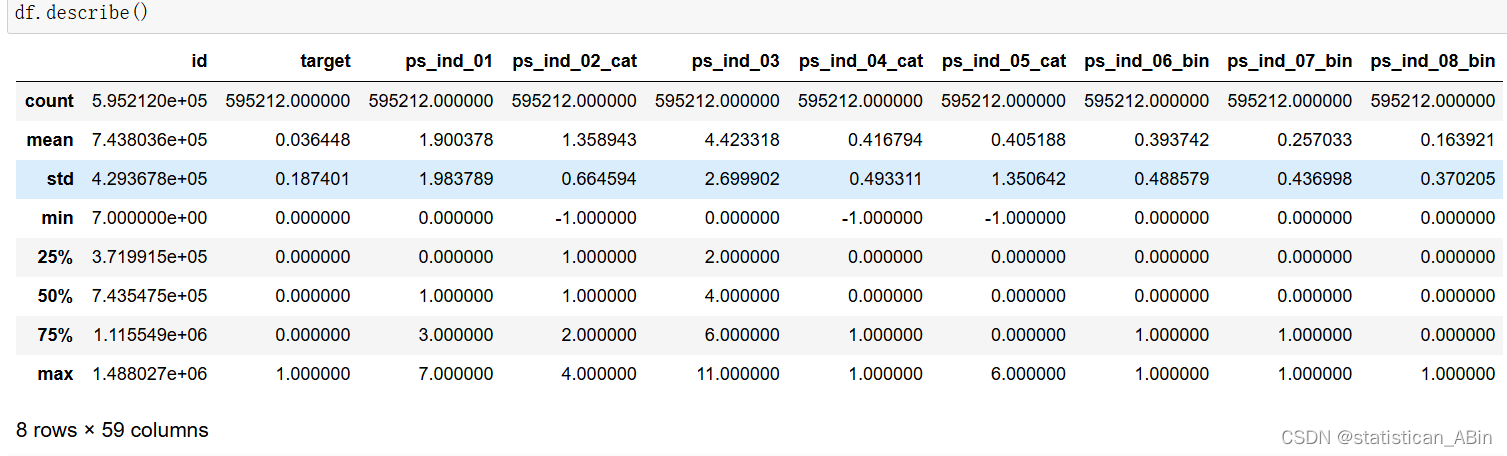
df.drop(col,axis=1,inplace=True)统计性描述
观察缺失值可视化
python
import missingno as msno
msno.matrix(df)
python
grouped = df.groupby('ps_calc_20_bin').mean()
grouped 
接下来画出特征的直方图
python
df.hist(bins=50, figsize=(20,15))
plt.show()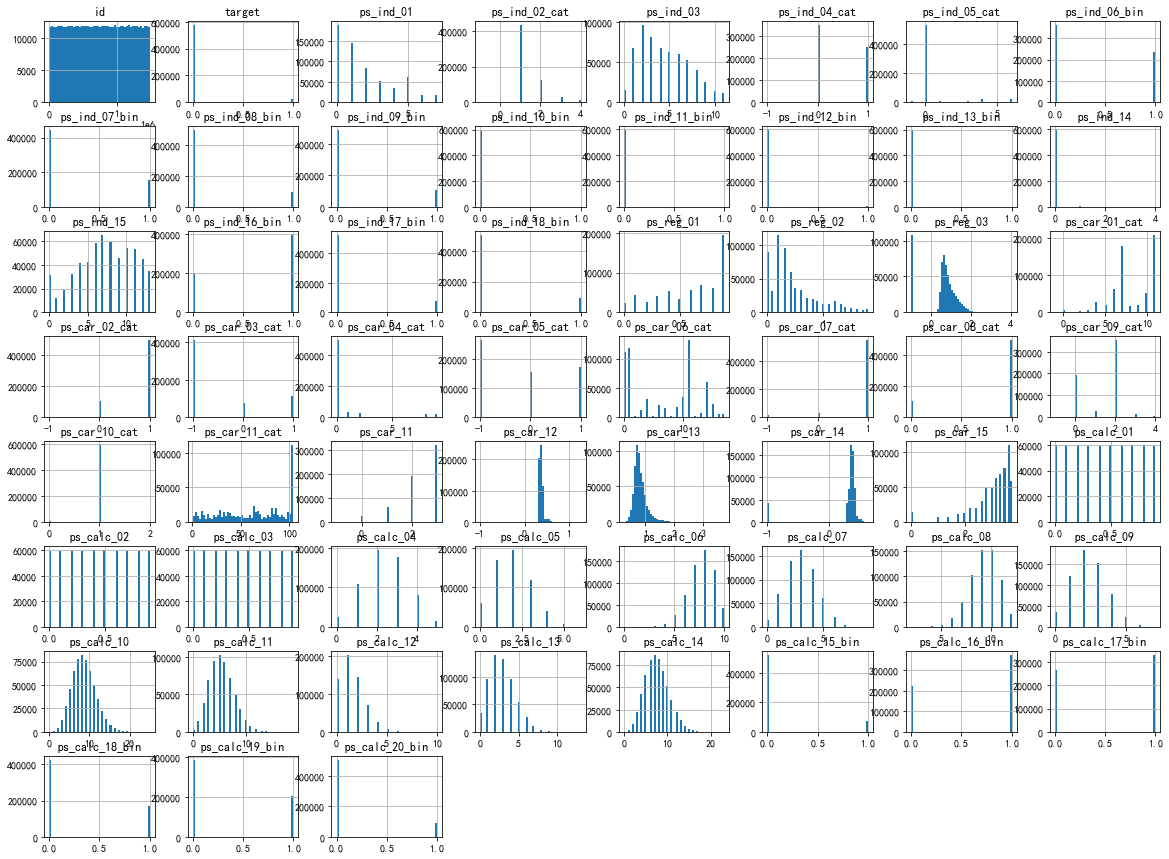
查看特征变量的箱线图分布
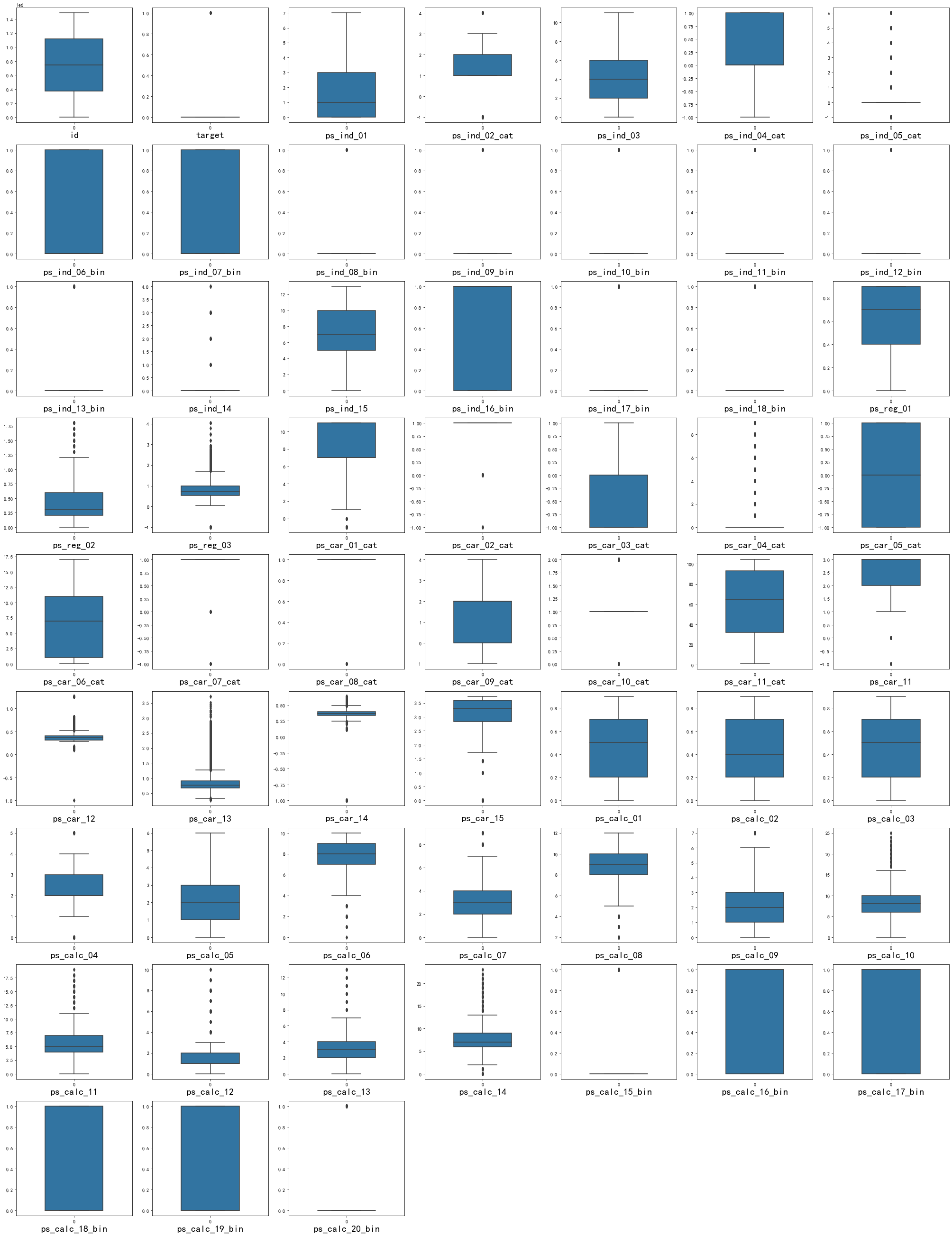
接下来采用了斯皮尔曼相关系数计算,画出热力图。在训练集上带上了y
python
corr = plt.subplots(figsize = (20,16),dpi=128)
corr= sns.heatmap(df.corr(method='spearman'),annot=True,square=True)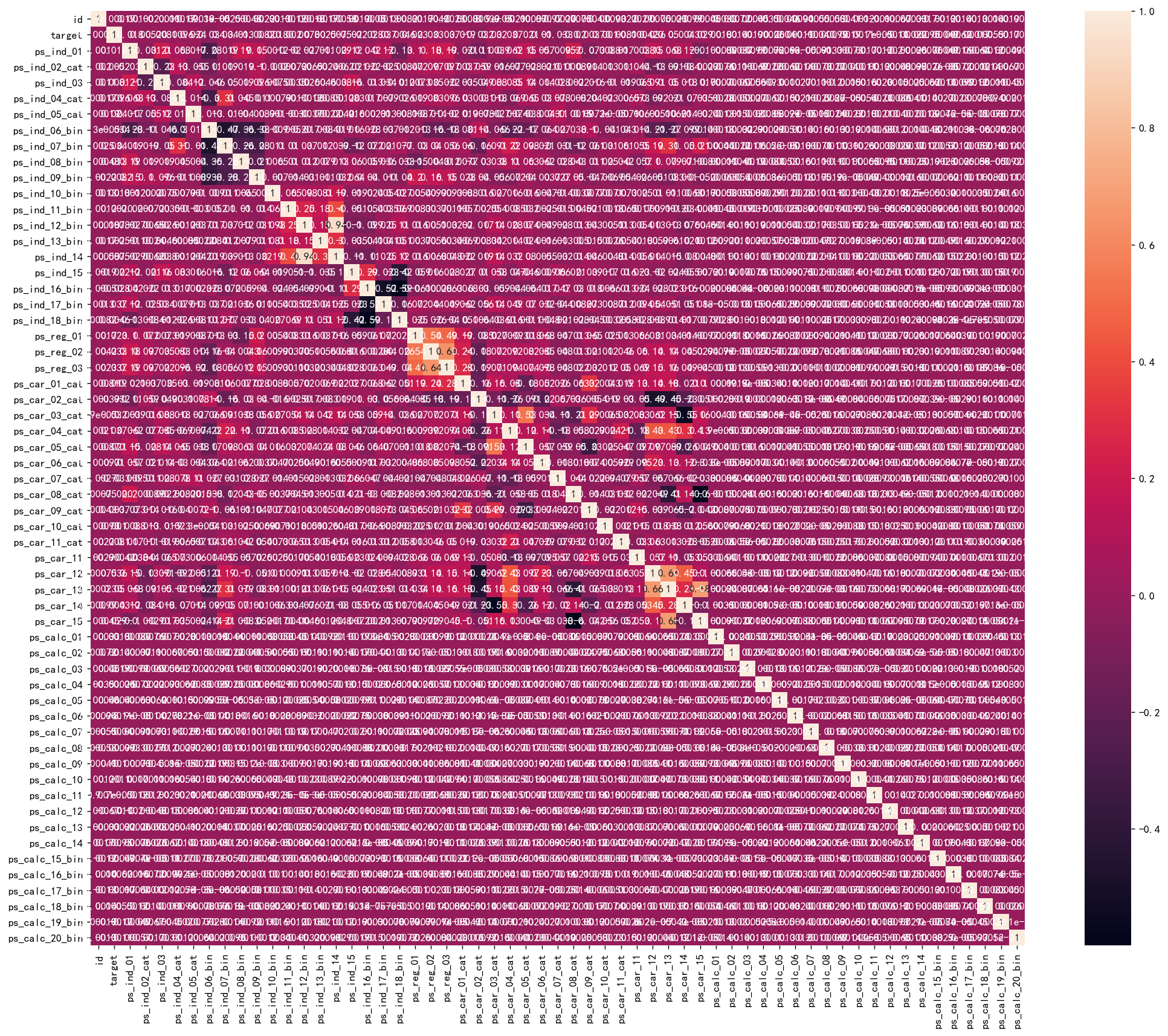
响应变量分布
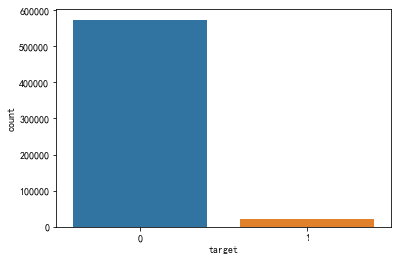
由于数据集样本不平衡,要处理一下
python
no_target = df_copy.drop(index = target.index)
no_target = no_target.sample(n = 21694)
balanced = pd.concat([no_target, target])
balanced['target'].value_counts()
balanced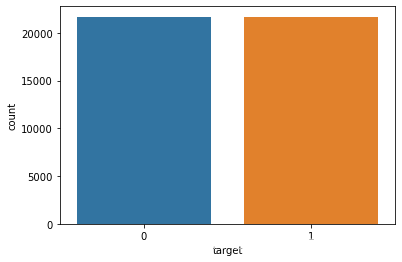
平衡了
可视化响应变量分布

开始机器学习 准备模型
python
# Split the dataset into training and test sets
X = df1.drop(['id'], axis=1) ####我们这里target已经没有了
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
python
from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors=10)
model.fit(X_train_s, y_train)
model.score(X_test_s, y_test)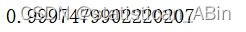
python
from sklearn.ensemble import RandomForestClassifier
model= RandomForestClassifier(n_estimators=1000, max_features='sqrt',random_state=10)
model.fit(X_train_s, y_train)
model.score(X_test_s, y_test)
python
from sklearn.ensemble import AdaBoostClassifier
model0 = AdaBoostClassifier(n_estimators=100,random_state=77)
model0.fit(X_train_s, y_train)
model0.score(X_test_s, y_test)到此,完成了模型的预测和比较。。。
三、小结
在这个案例中,我运用了机器学习的方法,包括KNN,自适应提升和随机森林等等,对驾驶安全进行了预测。然而,由于数据量很 大导致样本不平衡,最终结果很一般,甚至出现了过拟合的情况。在解决这个问题的过程中,我采用了以下的方法: 数据清洗和特征选择 在机器学习的过程中,数据质量和特征选择都是非常重要的。在本案例中,我通过数据清洗和特征选择的方式,剔除了一些噪声 和冗余的数据,以及一些无关或者不必要的特征。这可以提高数据的质量,提高模型的准确性。 数据预处理 在处理数据时,我注意到数据量很大,且样本不平衡,这对于机器学习算法的效果产生了很大的影响。因此,我采用了一些数据 预处理的方法,包括数据平衡和数据规范化。数据平衡可以通过欠采样和过采样的方式来实现。而数据规范化则可以通过归一化 和标准化等方式来实现,以确保不同特征的数值范围一致。
模型选择和调优:在本案例中,我尝试了多种机器学习算法,包括KNN,自适应提升和随机森林等等。然而,由于数据量很大且样本不平衡,模型 表现并不理想,存在过拟合的情况。因此,后续可以采用模型调优的方式来提高模型的准确性和泛化能力。 结果分析和优化 在完成机器学习任务后,我对结果进行了分析和优化。例如,我发现在预测少数类别时,模型表现并不理想,因此需要进一步加强 对少数类别的学习。 综上所述,在本案例中,我通过数据清洗和特征选择、数据预处理、模型选择和调优以及结果分析和优化等方法,一定程度上完 成了机器学习的过程,后续的对于样本处理以及过拟合的问题还需进一步研究。