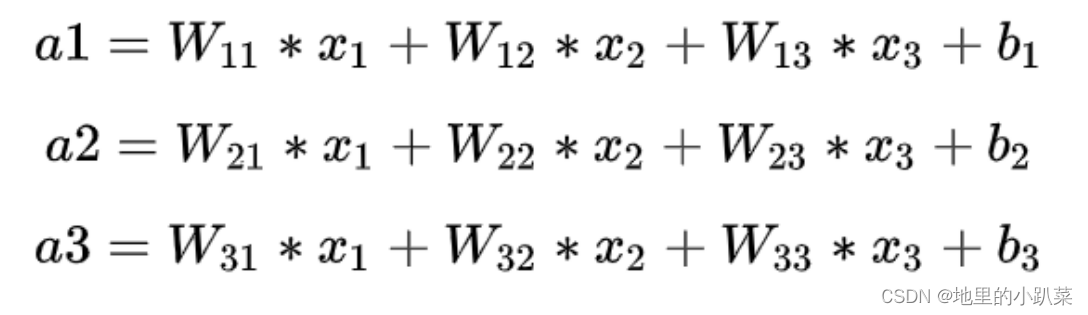目录
[2.卷积核个数 等于 输出通道个数](#2.卷积核个数 等于 输出通道个数)
[编辑 十一、pooling--池化](#编辑 十一、pooling--池化)
一、图片数据如何输入?(掌握知识)
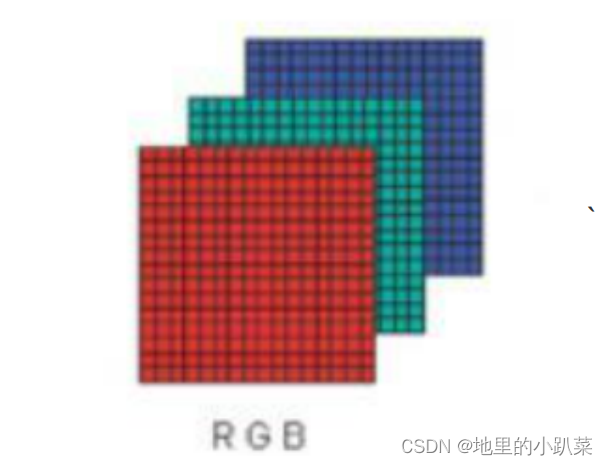
彩色图像有RGB三个颜色通道,分别是红、绿、蓝三个通道,这三个通道 的像素可以用二维数组来表示,其中像素值由0到255的数字来表示。比如一张 160x60的彩色图片,可以用160 * 60 *3 的数组表示。
二、什么是卷积?(掌握知识)
卷积过程是使用一个卷积核(如图中的Filter),在每层像素矩阵上不断按 步长扫描下去,每次扫到的数值会和卷积核中对应位置的数进行相乘,然后相 加求和,得到的值将会生成一个新的矩阵。卷积核相当于卷积操作中的一个过 滤器,用于提取我们图像的特征,特征提取完后会得到一个特征图。卷积核的 大小一般选择3x3和5x5,比较常用的是3x3,训练效果会更好。卷积核里面的 每个值就是我们需要训练模型过程中的神经元参数(权重),开始会有随机的初始值,当训练网络时,网络会通过后向传播不断更新这些参数值,知道寻找 到最佳的参数值。对于如何判断参数值的最佳,则是通过loss损失函数来评估。
如下图所示,卷积的过程是通过滑动窗口从上到下,从左到右对输入特征 图进行遍历,每次遍历的结果为相应位置元素的加权求和:
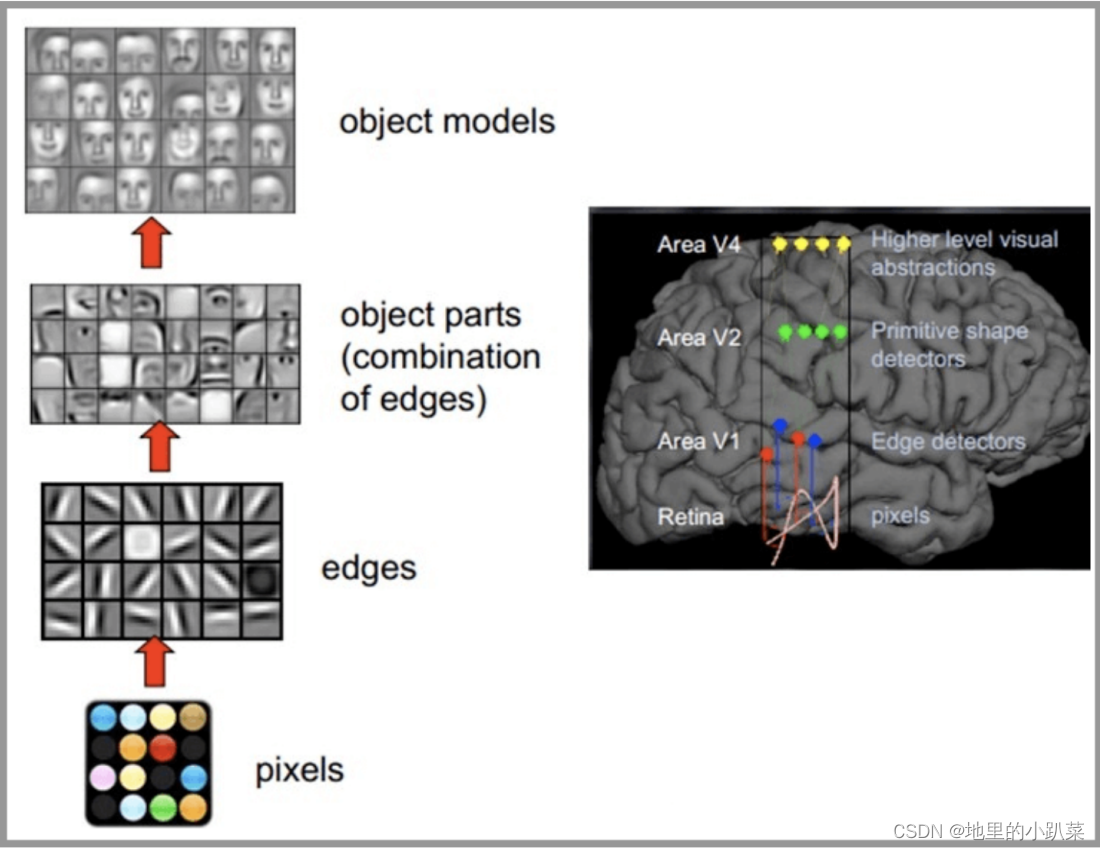
CNN网络受人类视觉神经系统的启发,人类的视觉原理:从原始信号摄入 开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘 和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一 步抽象(大脑进一步判定该物体是只人脸)。下面是人脑进行人脸识别的一个 示例:
CNN网络主要有三部分构成:卷积层、池化层和全连接层构成,其中卷积 层负责提取图像中的局部特征;池化层用来大幅降低参数量级(降维);全连接层 类似人工神经网络的部分,用来输出想要的结果。

整个CNN网络结构如下图所示:

三、卷积层
卷积层是卷积神经网络中的核心模块,卷积层的目的是提取输入特征图的 特征,如下图所示,卷积核可以提取图像中的边缘信息。

四、卷积的计算方法
那卷积是怎么进行计算的呢?
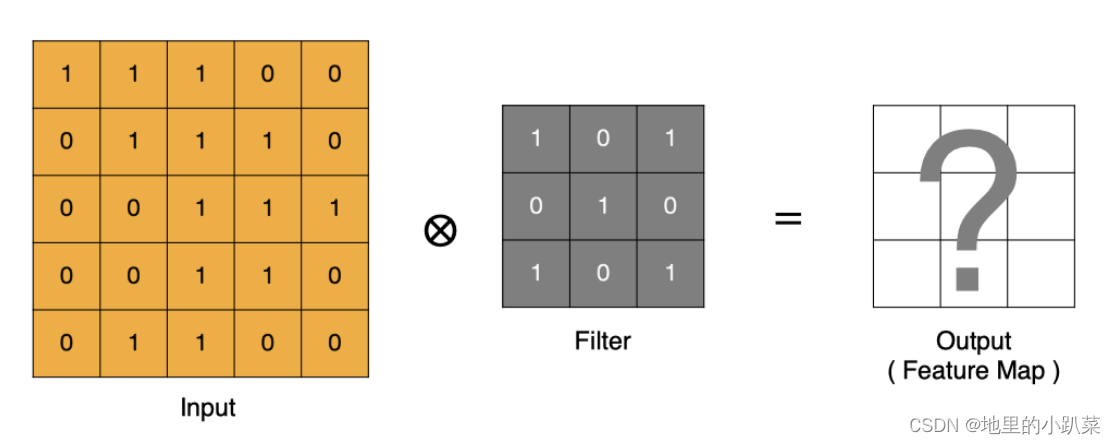 卷积运算本质上就是在滤波器和输入数据的局部区域间做点积。
卷积运算本质上就是在滤波器和输入数据的局部区域间做点积。

左上角的点计算方法:

同理可以计算其他各点,得到最终的卷积结果,
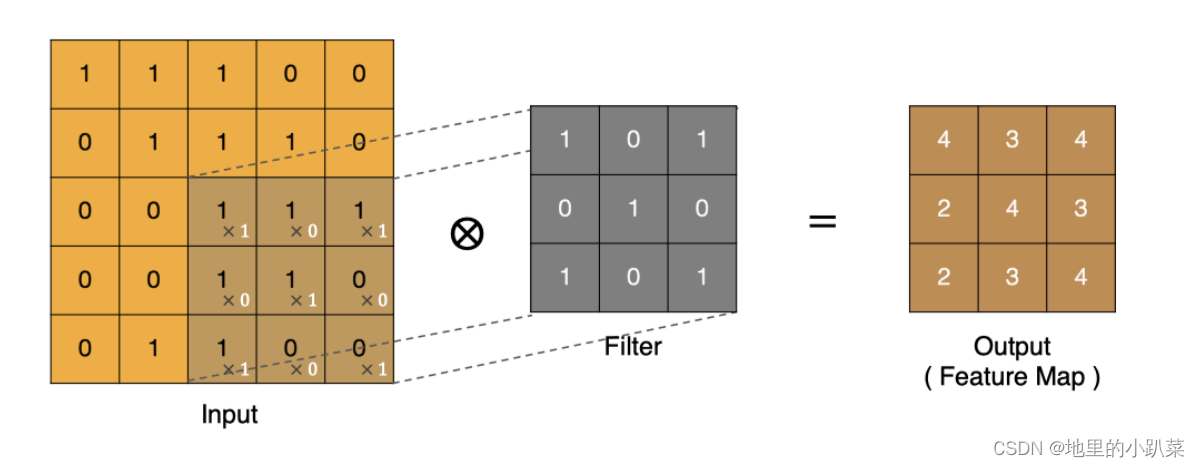 最后一点的计算方法是:
最后一点的计算方法是:
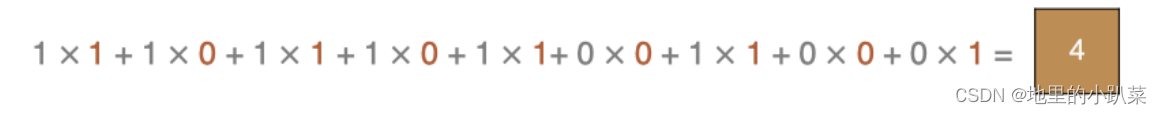
五、padding填充
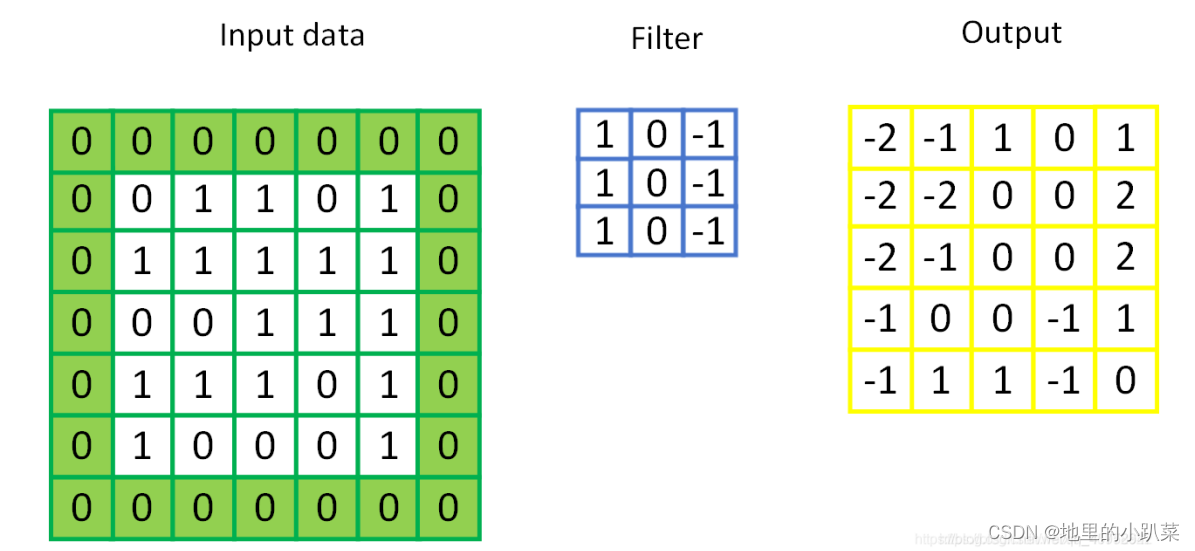
在上述卷积过程中,特征图比原始图减小了很多,我们可以在原图像的周围进行padding,来保证在卷积过程中特征图大小不变。在进行卷积操作的过程中,处于中间位置的数值容易被进行多次的提取,但是边界数值的特征提取次数相对较少,为了能更好的把边界数值也利用上,所以给原始数据矩阵的四周都补上一层0,这就是padding操作。
在进行卷积操作之后维度会变少,得到的矩阵比原矩阵要小,不方便计算,原矩阵加上一层0的padding操作可以很好的解决该问题,卷积出来的矩阵和原矩阵尺寸一致。
为避免经过多次卷积后矩阵变得太小,可以再矩阵周围填充一圈零来保证卷积后的矩阵跟原矩阵大小一样。
如下图,用输入数据中用绿色填充的部分就是补零填充,再进卷积运算即可得到与原数据一样的大小的输出。
六、stride
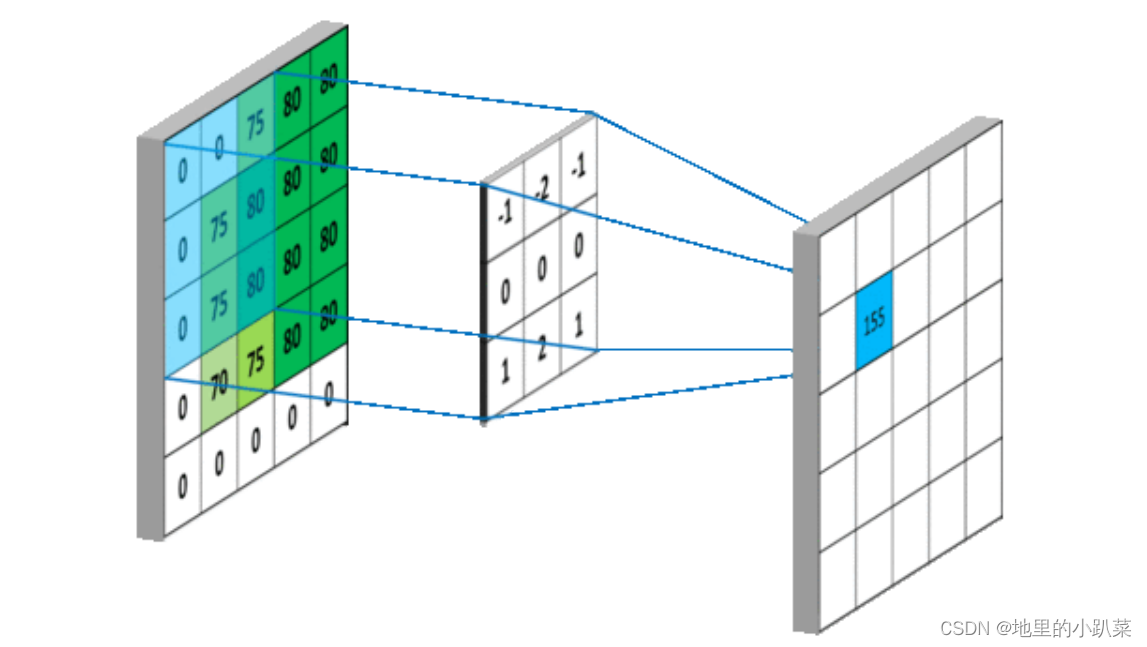
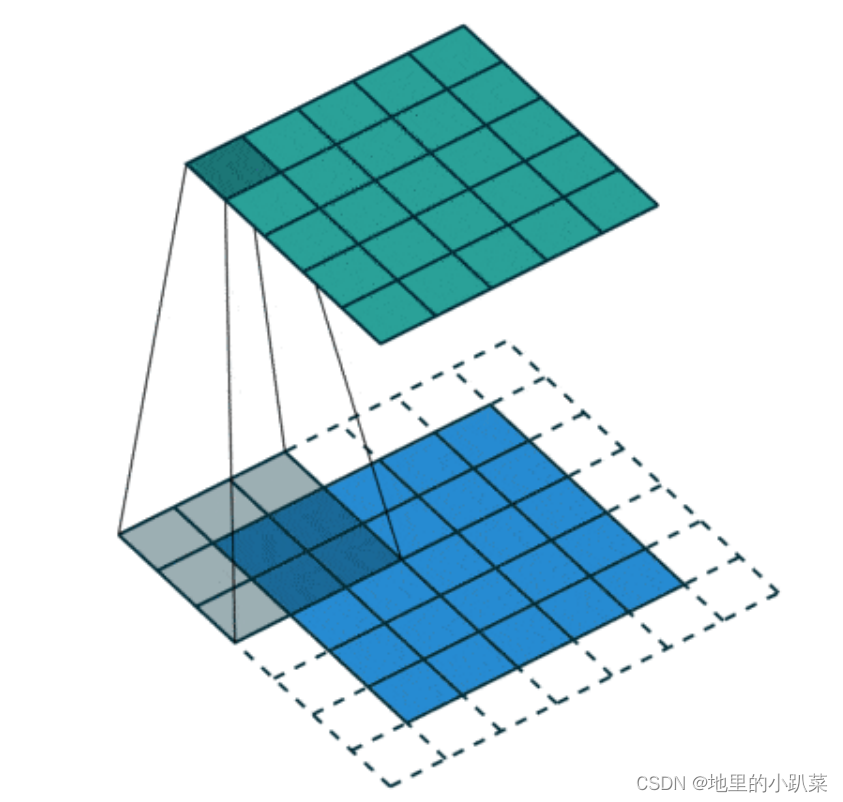
我们将每次滑动元素的数量称为步幅(stride)。下图展现的是垂直步幅为3,水平步幅为2的二维互相关运算.
按照步长为1来移动卷积核,计算特征图如下所示:

如果我们把stride增大,比如设为2,也是可以提取特征图的,如下图所示:

七、单通道卷积
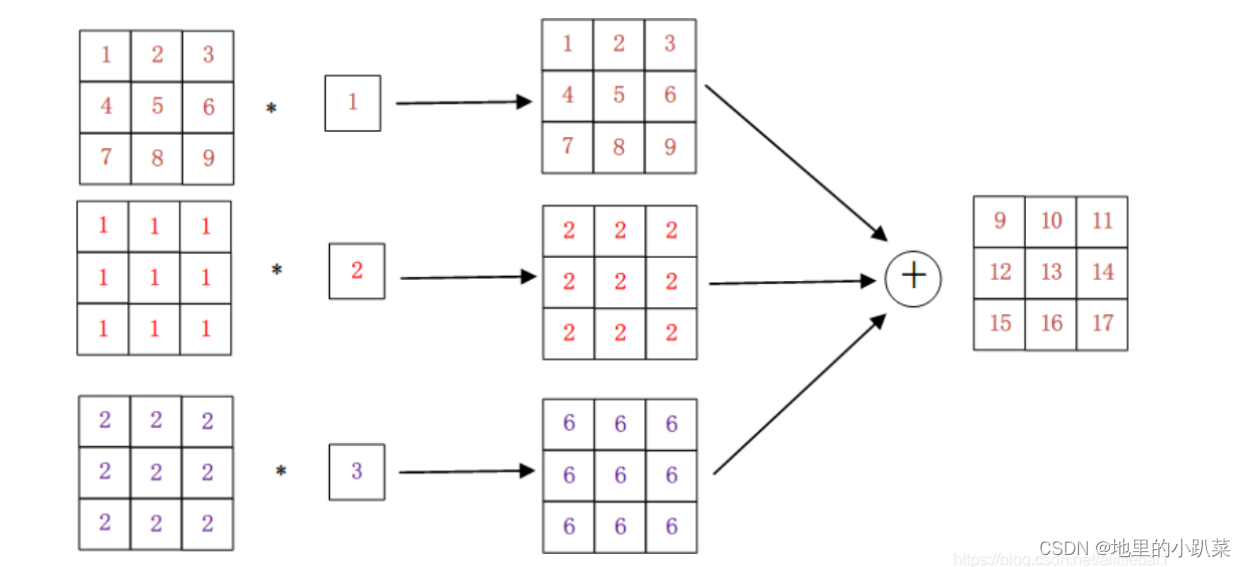
1.输入通道数等于卷积核通道个数
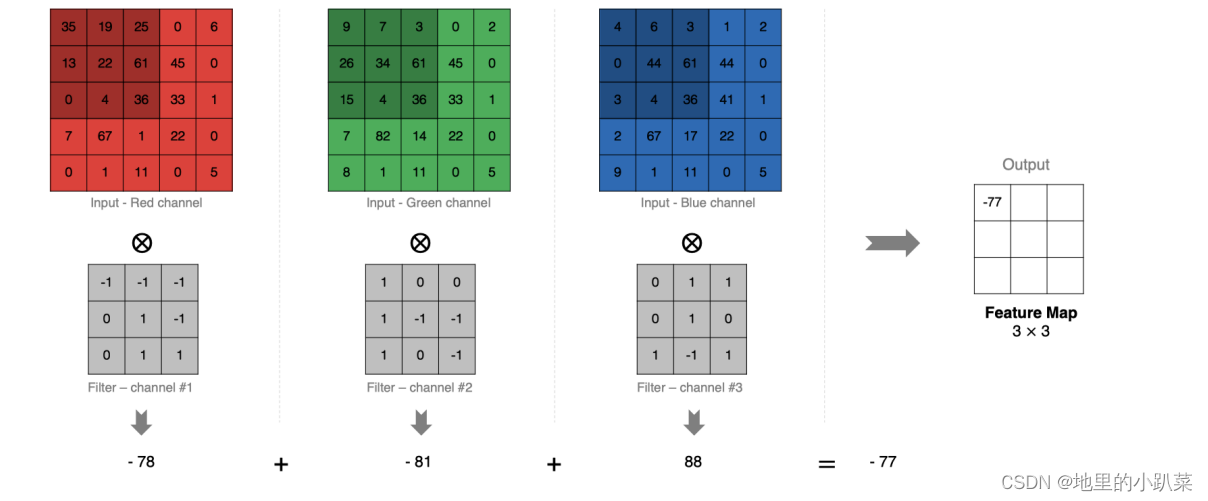
例如当我们输入的图片为三通道时,那么卷积核也会有三个通道,就像上述图片,最左边的三个矩阵是一个图片的三个通道(因为计算机上是以数字矩阵存储),与这张图片相乘的是一个1*1的三通道卷积核。
为了让图像的三个通道和卷积核分别进行点积并相加得到一个矩阵,即一个特征图,所以卷积核的通道也要有三个,为了和图像的每个通道都进行运算。
2.卷积核个数 等于 输出通道个数
卷积核的数量决定输出的通道数,比如说现在有一张像素为16*16的三通道图片(16*16*3),其实这张照片就由三个16*16的矩阵组成,如果这时我们有256个3*3*3的卷积核,其实就是每个卷积核由3个3*3的矩阵,有256个这样的卷积核。那么这张16*16*3的图片要和256个3*3*3的卷积核都进行点积并相加得出特征图,即得到的特征图有256个,即卷积核的个数,也是输出通道的个数.
3.为什么要增加通道
在一张照片中可能有很多信息,比如人,动物....,我们人眼可以一下子就分辨出来,但是计算机不可以,他要进行特征提取,也是卷积的第一个操作。
我们增加通道数就代表着增加特征,而造成通道数增加的操作其实就是卷积核的增加,不同的卷积核可以提取到不同特征,比如说平滑卷积核,它可以让整个图像更加平滑清晰,还比如增加水平边界过滤器,垂直边界过滤器(本质都是卷积核),让图像的矩阵和卷积核进行点积相加,得到不同的矩阵,即不同的特征图,这些特征图越多,越利于计算机学习,这将教会计算机识别特征。
因为不同的卷积核可以分辨出不同的特征,所以增加卷积核的个数很必要,计算机通过利用这些特征图,来最终得到结论,分辨出图像的事物到底是什么。
八、多通道卷积
实际中的图像都是多个通道组成的,我们怎么计算卷积呢?
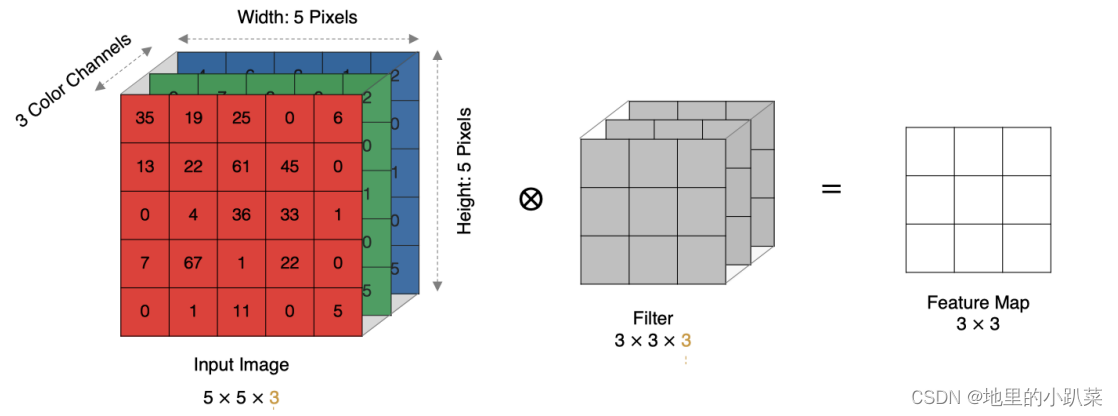
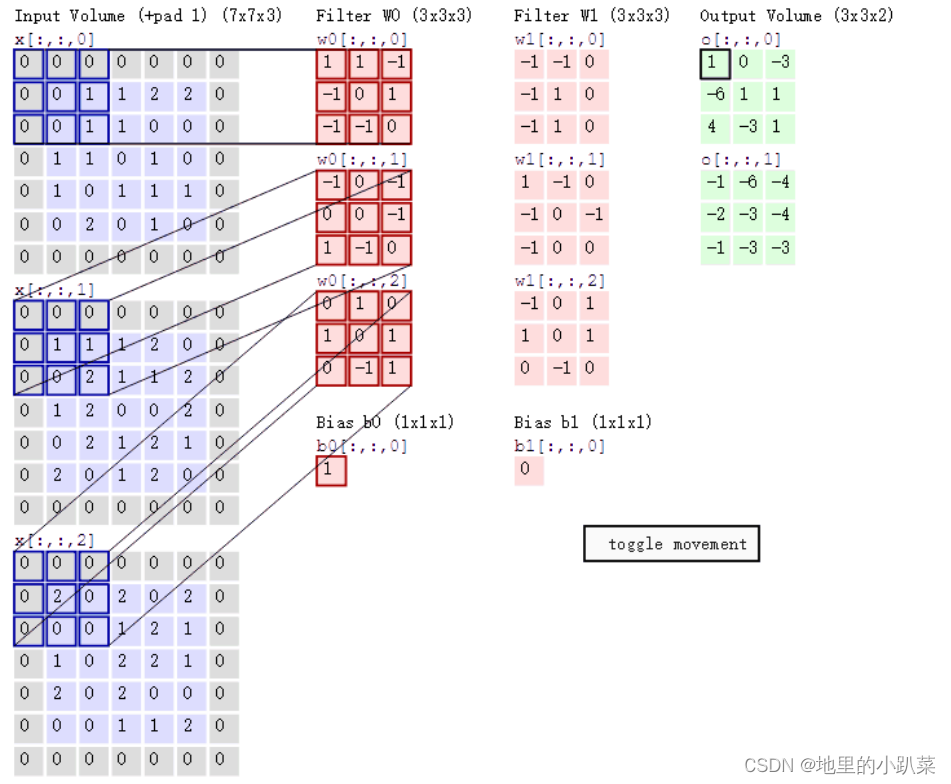
计算方法如下:当输入有多个通道(channel)时(例如图片可以有 RGB 三个通道),卷积核需要拥有相同的channel数,每个卷积核 channel 与输入层的对应 channel 进行卷积,将每个 channel 的卷积结果按位相加得到最终的Feature Map
输入是一个5x5x3的矩阵,有三个通道。filter是一个3x3x3的矩阵。首先,filter中的每个卷积核分别应用于输入层中的三个通道。执行三次卷积,产生3个3x3的通道。

九、多卷积核卷积
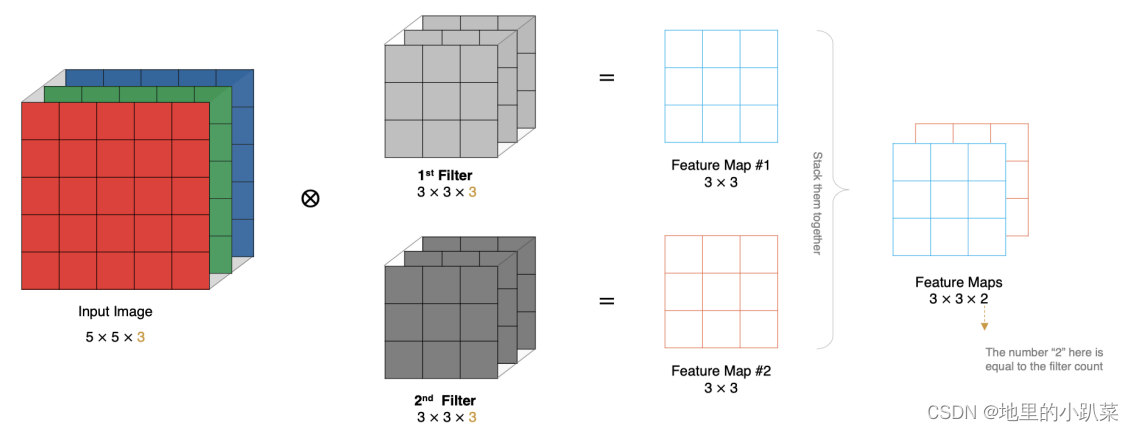
如果有多个卷积核时怎么计算呢?当有多个卷积核时,每个卷积核学习到不同的特征,对应产生包含多个 channel 的 Feature Map, 例如下图有两个filter,所以 output 有两个 channel。
然后,这三个通道相加(矩阵加法),得到一个3x3x1的单通道。这个通道就是在输入层(5x5x3矩阵)应用filter(3x3x3矩阵)的结果。

十、特征图大小
输出特征图的大小与以下参数息息相关: * size:卷积核/过滤器大小,一般会选择为奇数,比如有1 * 1, 3 * 3, 5 * 5 * padding:零填充的方式 *stride:步长

那计算方法如下图所示:
Kernel size=3,Stride=1,Padding=1:
输入特征图为5x5,卷积核为3x3,外加padding 为1,则其输出尺寸为:(2为步幅)
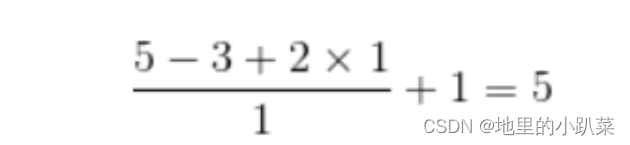
如下图所示:
在tf.keras中卷积核的实现使用
tf.keras.layers.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', activation=None )主要参数说明如下:
 十一、pooling--池化
十一、pooling--池化
池化(Pooling)是卷积神经网络中的一个重要的概念,它实际上是一种形式的降采样。有多种不同形式的非线性池化函数,而其中"最大池化(Maxpooling)"是最为常见的。
池化操作相当于降维操作,有最大池化和平均池化,其中最大池化(max pooling)最为常用。
经过卷积操作后我们提取到的特征信息,相邻区域会有相似特征信息,这是可以相互替代的,如果全部保留这些特征信息会存在信息冗余,增加计算难度。
通过池化层会不断地减小数据的空间大小,参数的数量和计算量会有相应的下降,这在一定程度上控制了过拟合。
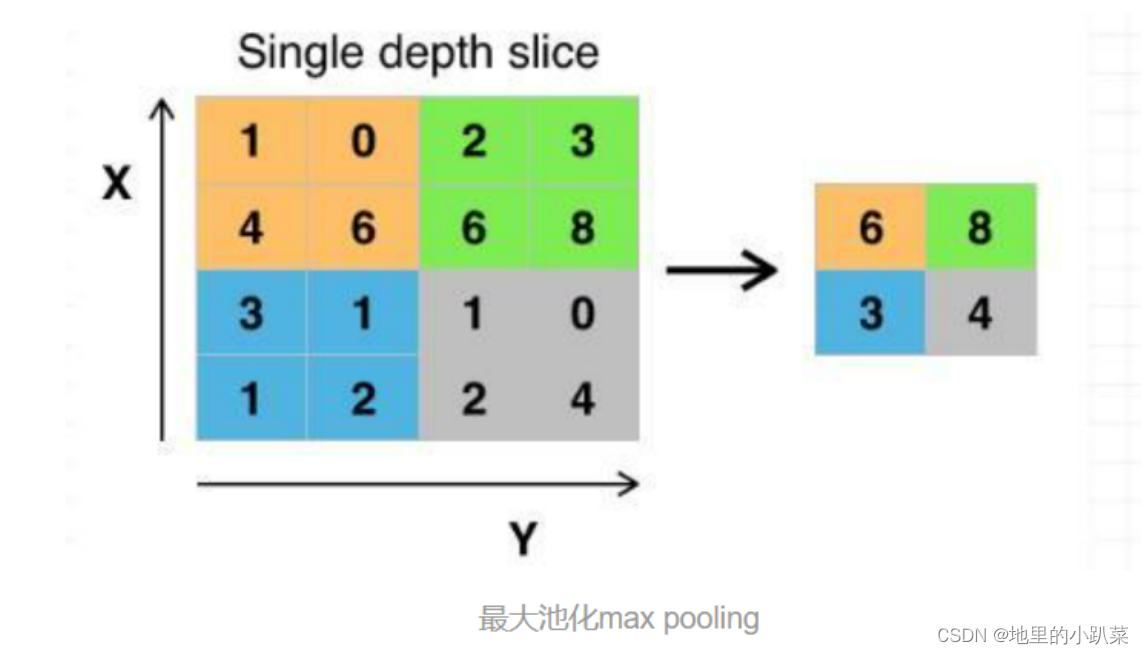
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。池化包括最大池化、平均池化等。其中最大池化是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出层
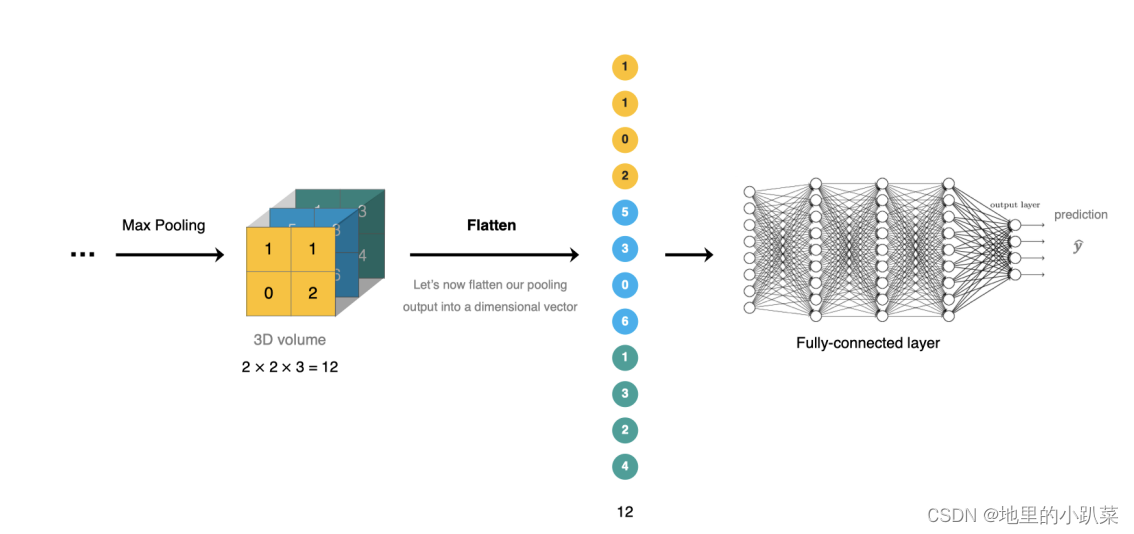
十二、Fletten--展平
Flatten 将池化后的数据拉开,变成一维向量来表示,方便输入到全连接网络
Flatten 层用来将输入"压平",即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
十三、全连接层
对n-1层和n层而言,n-1层的任意一个节点,都和第n层所有节点有连接。即第n层的每个节点在进行计算的时候,激活函数的输入是n-1层所有节点的加权
在实际使用中,全连接层可由卷积操作实现:
对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;
而前层是卷积层的全连接层可以转化为卷积核为h*w的全局卷积,分别为前层卷积结果的高和宽。
全连接的核心操作就是矩阵向量乘积 y = Wx
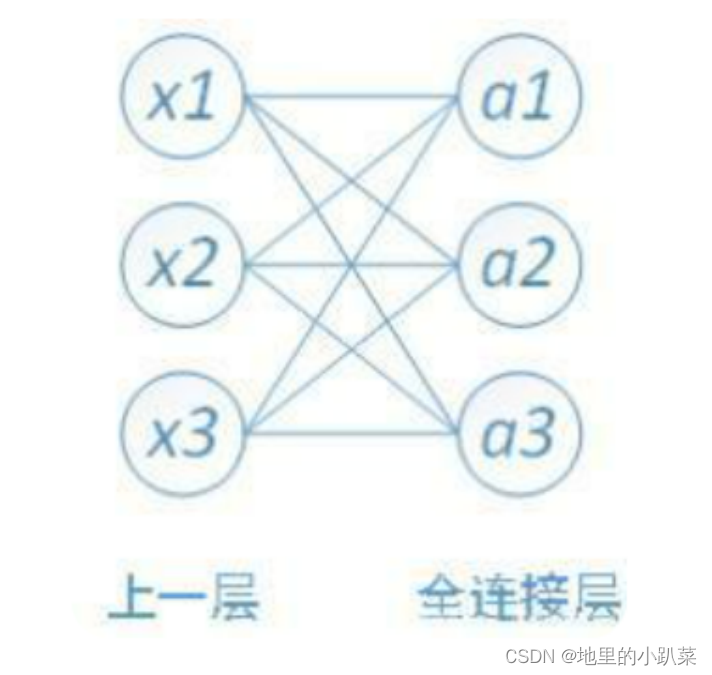
其中,x1、x2、x3为全连接层的输入,a1、a2、a3为输出,