1、LLaNA: Large Language and NeRF Assistant
中文标题:LLaNA: 大型语言和NeRF助手
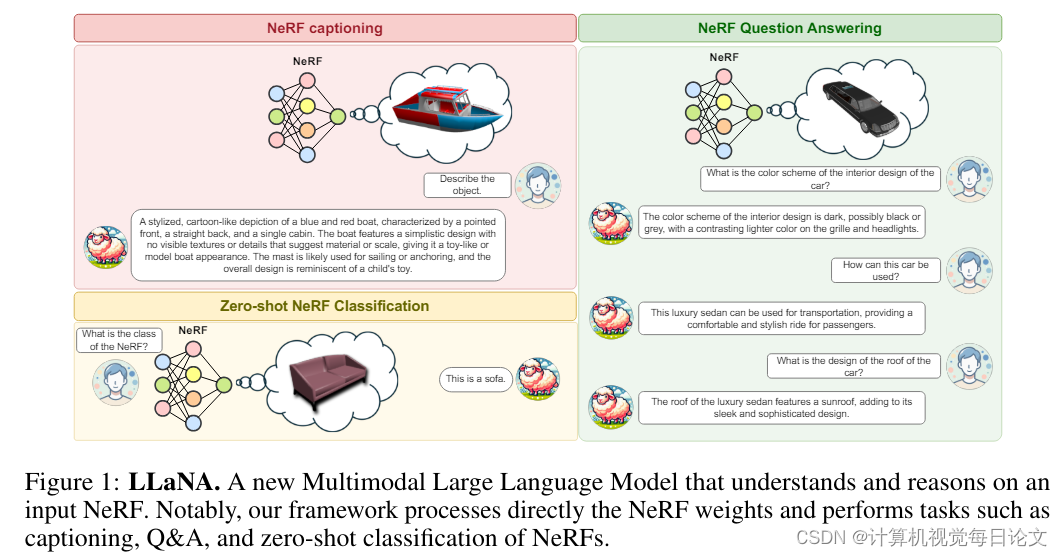
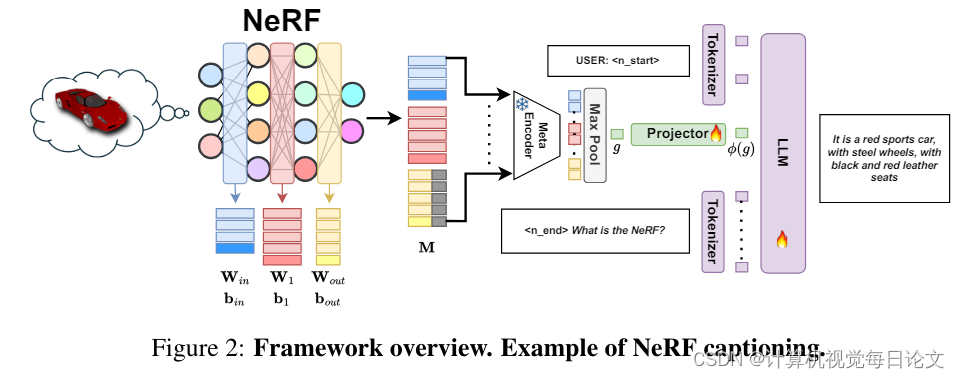
简介:多模态大语言模型(MLLMs)已经展现出对图像和三维数据的出色理解能力。然而,这两种数据形式在全面捕捉物体外观和几何形状方面存在局限性。与此同时,神经辐射场(NeRFs)通过在简单多层感知器(MLP)权重中编码信息,已成为一种越来越普及的新兴模态,能同时编码物体的几何形状和逼真外观。
本文探讨将NeRF引入MLLM的可行性和效果。作者提出了LLaNA,这是第一个能执行NeRF字幕、问答等新任务的通用NeRF语言助手。值得注意的是,该方法直接处理NeRF的MLP权重,无需渲染图像或实现3D数据结构,就可以提取所表示物体的信息。作者还构建了一个包含各种NeRF语言任务的文本注释NeRF数据集,无需人工干预。
基于这个数据集,作者开发了一个基准来评估处理NeRF权重的方法在NeRF理解能力方面的表现。结果显示,这种方法优于从NeRF中提取2D或3D表示的方法。
2、 Autoregressive Image Generation without Vector Quantization
中文标题:自回归图像生成无向量量化
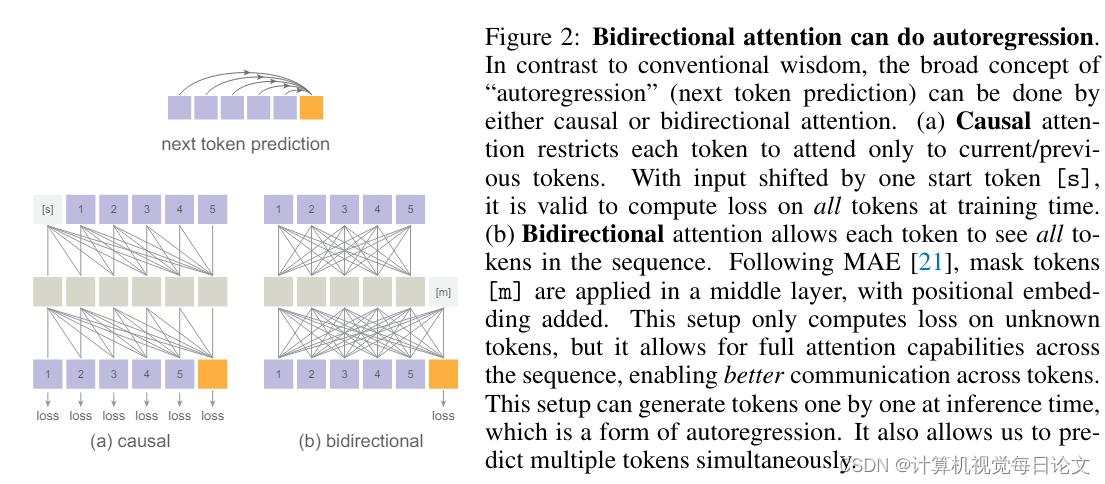

简介:这段文章探讨了一种图像生成的新方法,不需要使用向量量化技术。传统的观点认为,采用自回归模型进行图像生成需要使用离散的编码标记。但是作者发现,尽管离散值空间可以方便地表示分类分布,但它并不是自回归建模的必要条件。
在这项研究中,作者提出使用扩散过程来建模每个标记的概率分布,从而允许在连续值空间中应用自回归模型。作者定义了一种扩散损失函数,来建模每个标记的概率分布,而不是使用分类交叉熵损失。这种方法消除了需要使用离散值标记的必要性。
作者在标准自回归模型和广义掩码自回归(MAR)变体的广泛案例中评估了这种方法的有效性。通过消除向量量化,这种图像生成器在保留序列建模速度优势的同时,取得了优秀的生成结果。
作者表示,希望这项工作能激发更多在其他连续值领域和应用中使用自回归生成的研究动力。
3、Scaling the Codebook Size of VQGAN to 100,000 with a Utilization Rate of 99%
中文标题:将 VQGAN 的 Codebook 大小扩展至 100,000,利用率达到99%
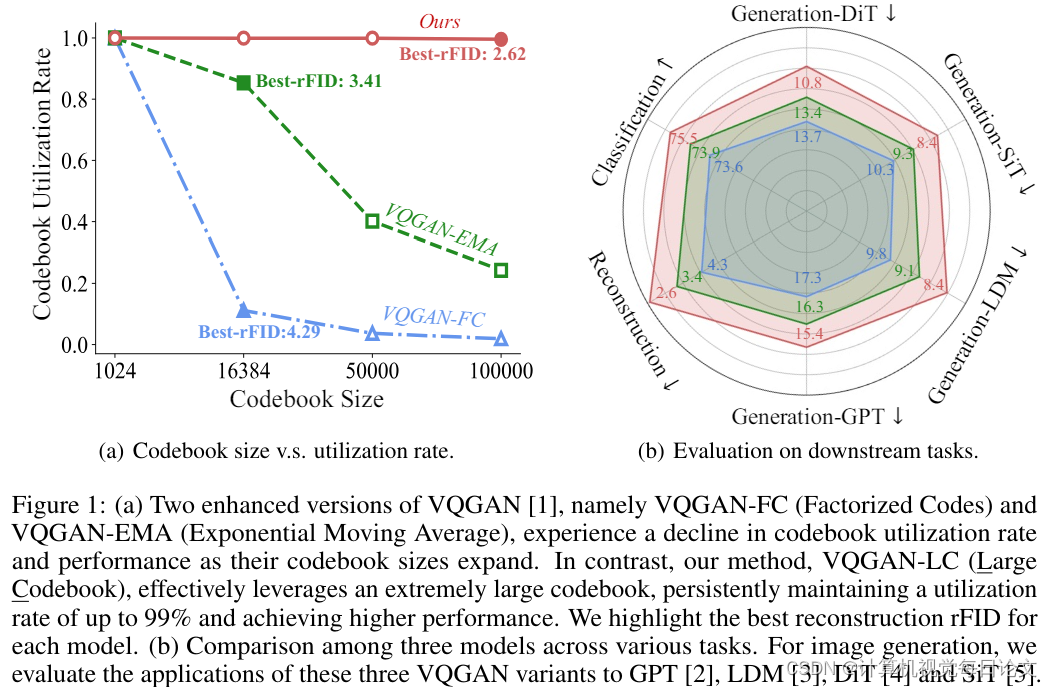
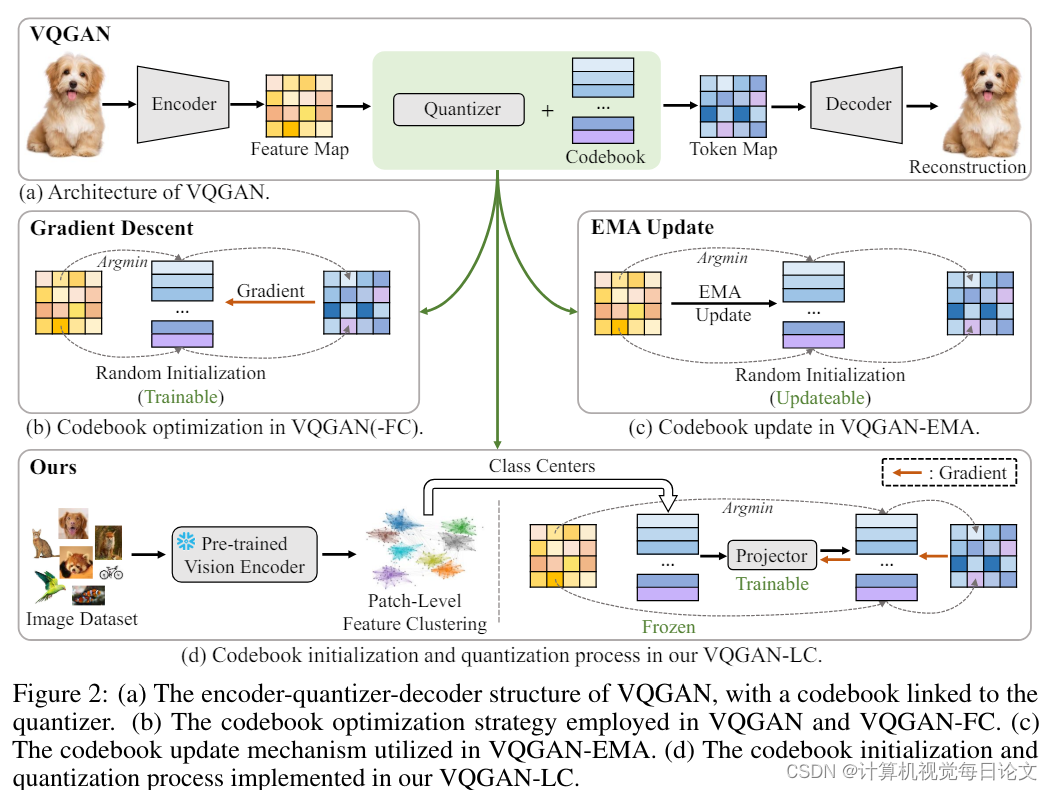
简介:在图像量化领域,VQGAN等模型通过将图像编码为预定义"码书"中的离散标记来工作。最近的研究表明,扩大码书大小可以显著提高模型性能。但VQGAN及其衍生模型(如VQGAN-FC)在增大码书大小和提高码书利用率方面仍然面临挑战。
为解决这些问题,本文提出了一种名为VQGAN-LC的新型图像量化模型。VQGAN-LC将码书大小扩展到100,000,并实现了超过99%的高利用率。与之前优化每个码书条目的方法不同,VQGAN-LC从100,000个预训练视觉特征初始化码书,然后优化一个将特征分布对齐至码书的投影器。
作者展示,VQGAN-LC在图像重建、分类、自回归生成和扩散/流式生成等任务中均优于其他模型。相关代码和模型已公开发布https://github.com/zh460045050/VQGAN-LC。