
image-20240619172414638 https://arxiv.org/pdf/2403.01744v2
简介
本文来自小红书和中科大, 首次尝试了将LLM应用到笔记推荐(Note Recommendation)中. 更具体的,
-
本文在推荐链路(召回->粗排->精排->重排)的召回环节, 新上(或替换了)一路现有的I2I(Item2Item, 这里item其实是Note)召回.
-
模型核心点是: 如何考虑用户共点击行为和属性/标签, 对LLM模型LLama2进行微调, 使之可以适配推荐场景的需求?
-
在线A/B测试的提升也非常显著. 对比之前的SentenceBERT , LLMNote的ctr提升高达16.20%. 但这应该是单路召回的对比提升. 实际大盘应该关注在 笔记的评论量(number of comments)和每周创作者数(weekly number of publishers), 前者和I2I的提升更相关, 后面的提升更间接.
下面是个简单的流程示例
-
底层设计和使用了多种prompt. 比如Note Emb 和 Output Guidance, 分别用于得到note的embedding和相关属性标签.
-
中间是微调好的NoteLLM
-
上层是如何进行服务的, 包括标签/属性生产, 然后从候选的note pool筛选出相关的note. 这里是基于Singapore的Note, 召回了另1个与Singapore相关的Note(红色箭头部分).
 image-20240619173541080
image-20240619173541080
模型
下面是更具体的训练流程, 主要有3块: prompt的构建, 以及2种训练任务
 image-20240619175128648
image-20240619175128648
Prompt结构
对于第i篇笔记, 其主要由4部分组成, 分别代表标题(title), 标签(hashtag), 类目(category)和内容(content).
 image-20240619182021284
image-20240619182021284
相应的, prompt的结构如下:
 image-20240619182308974
image-20240619182308974
这里EMB代表经过LLM生成的笔记的embedding, 用于后续的对比学习任务.
类目生成的prompt
 image-20240619182342244
image-20240619182342244
标签主题生成的prompt
 image-20240619182413942
image-20240619182413942
共现相似笔记对的构建 -> 对比学习(Generative-Contrastive Learning)

如上图, 主要就2步:
(1) 共现统计来构建相似笔记对. 这里思路比较常见, 就是统计2个笔记被哪些用户共同点击过, 次数越多, 笔记越像.

(2) 正负样本对比loss. 正样本相似度大于负样本.

标签/类目的预测任务(Collaborative Supervised Fine-Tuning)
对于这部分, 文中介绍的较为简洁, 主要是1个预测公式和loss计算.
 image-20240619182924424
image-20240619182924424
最后, 把2种loss做了个加权融合(调控), 进行联合训练
 image-20240619183026047
image-20240619183026047
实验
效率实验都比base要好一些, 这里简单罗列一下. 召回离线评估指标选取的是经典的Recall系列.
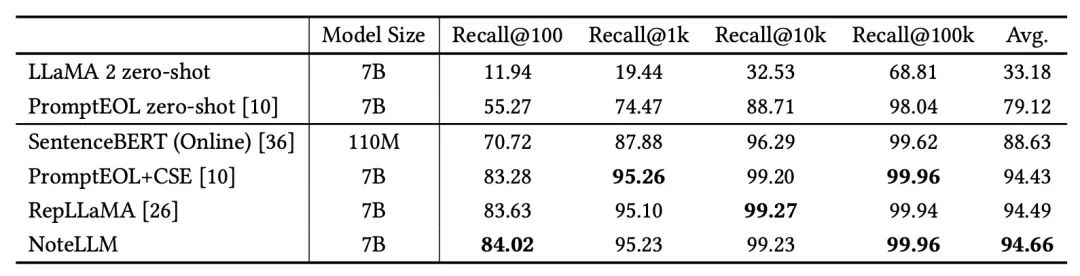 image-20240619183434864
image-20240619183434864
后面的参数实验也调整了, 但是看起无明显规律, 且的时候效果也还不错...

作者也找了一些case去看, 基本符合预期.
 image-20240619183352359
image-20240619183352359