发现好像还是爬虫的知识热度比较高,最近一直在加强JS这块。这两天脚本模拟爬BOSS的时候也想着怎么用nodejs,昨天都没更新文章,Q-Q,因为一直failed没啥成果。
使用模块
这边可以看到使用的模块其实也挺多,但主要还是http和https模块,这两个用来爬取信息算是比较方便的
javascript
var http=require('http');
var https=require('https');
var _=require('lodash')
const { createObjectCsvWriter } = require('csv-writer');
const download=require('download')
javascript
const csvWriter = createObjectCsvWriter({
path: 'comments.csv',
header: [
{ id: 'comment_id', title: 'Comment ID' },
{ id: 'user_id', title: 'User ID' },
{ id: 'content', title: 'Content' },
{ id: 'url', title: 'url' },
// { id: 'parent_id', title: 'Parent Comment ID' } // 添加父评论
]
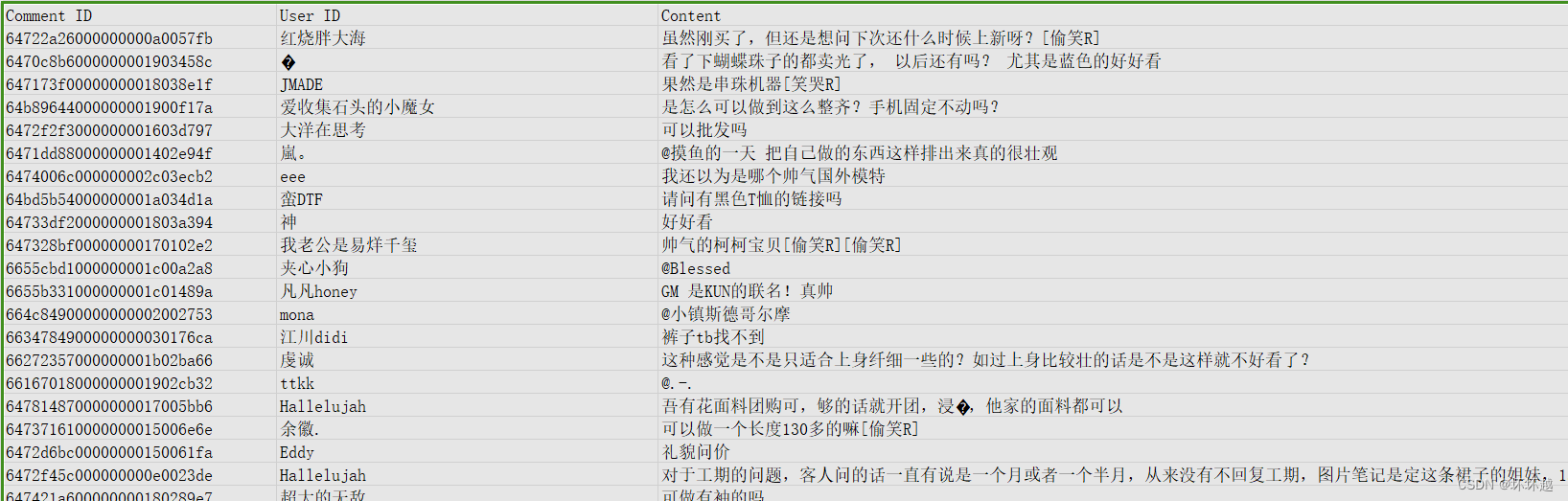
});先是生成了一个csv文件用于存储到时候爬取到的信息
javascript
const options = {
hostname: 'edith.xiaohongshu.com',
port: 443,
path: '/api/sns/web/v2/comment/page?note_id=6663171e000000000d00f19c&cursor=&top_comment_id=&image_formats=jpg,webp,avif',
method: 'GET',
headers: {
'Cookie':'你的cookie',
'User-Agent': 'User-Agent' // 可选: 设置User-Agent
}
};这边主要就是http请求的信息设定了,headers信息直接复制就好了

调用HTTPS请求并将结果存放到data
javascript
https.get(options2,(resp)=>{
let data=''
resp.on("data",(chunk)=>{
data+=chunk;
});
resp.on('end',()=>{得到的data会是很长的内容,需要用正则表达式将数据分割出来
javascript
resp.on('end',()=>{
// <script[^>]*>\s*window\.__INITIAL_STATE__\s*=\s*(\{[\s\S]*?\})
const scriptRegex = /{"id":"([^"]+)",("modelType":"[^"]+")/g;
let match;
while ((match = scriptRegex.exec(data)) !== null) {
if (match[1]) {
const initialState = match[1];再将需要的数据存放到csv文件中
javascript
csvWriter.writeRecords(records, { append: true })
.then(() => {
console.log('The CSV file was written successfully');
})
.catch(err => {
console.error('Error writing CSV file:', err);
});