Go-知识并发控制RWMutex
- [1. 介绍](#1. 介绍)
- [2. 原理](#2. 原理)
-
- [2.1 读写锁的数据结构](#2.1 读写锁的数据结构)
- [2.2 接口定义](#2.2 接口定义)
- [2.3 Lock() 写锁定 原理](#2.3 Lock() 写锁定 原理)
- [2.4 Unlock() 写锁定解锁 原理](#2.4 Unlock() 写锁定解锁 原理)
- [2.5 RLock() 读锁定 原理](#2.5 RLock() 读锁定 原理)
- [2.6 RUnlock() 读锁定解锁 原理](#2.6 RUnlock() 读锁定解锁 原理)
- [3. 场景分析](#3. 场景分析)
-
- [3.1 写锁定如何阻塞写锁定](#3.1 写锁定如何阻塞写锁定)
- [3.2 写锁定如何阻塞读锁定](#3.2 写锁定如何阻塞读锁定)
- [3.3 读锁定如何阻塞写锁定](#3.3 读锁定如何阻塞写锁定)
- [3.4 写锁定不会被 饿死](#3.4 写锁定不会被 饿死)
gitio: https://a18792721831.github.io/
1. 介绍
互斥锁 Mutex 是串行加锁,拿到锁之后,不管是读操作还是写操作,对于 Mutex 来说,是等价的。
但是在并发里面,如果仅仅是读操作,不改变数据的前提下,是可以共享的,多个协程读取到的数据都是可信的。
Mutex 存在这几个问题:
- 写锁需要阻塞写锁: 一个协程拥有写锁时,其他协程写操作需要阻塞
- 写锁需要阻塞读锁: 一个协程拥有写锁时,其他协程读操作需要阻塞
- 读锁需要阻塞写锁: 一个协程拥有读锁时,其他协程写操作需要阻塞
- 读锁不能阻塞读锁: 一个协程拥有读锁时,其他协程读操作不需要阻塞
而 RWMutex 是 Mutex 的一个增强版,解决了上面的4个问题
2. 原理
2.1 读写锁的数据结构
在源码包src/sync/rwmutex.go中定义了读写锁的数据结构
Go
type RWMutex struct {
w Mutex // 用于控制多个写锁,获得写锁需要先获取该锁
writerSem uint32 // 写阻塞等待的信号量,最后一个读者释放锁时会释放信号量
readerSem uint32 // 读阻塞的协程等待的信号量,持有写锁的协程释放锁后会释放信号量
readerCount int32 // 记录读者个数
readerWait int32 // 记录写阻塞时读者个数
}读写锁内部使用 Mutex 互斥锁,用于将多个写操作隔离开来。
2.2 接口定义
RWMutex 提供了这几个接口用于操作锁:
- RLock(): 读锁定
- RUnlock(): 读锁定解锁
- Lock(): 写锁定
- Unlock(): 解除写锁定
- TryLock(): 以非阻塞方式尝试写锁定( >= Go 1.18)
- TryRLock(): 以非阻塞方式尝试读锁定( >= Go 1.18)
2.3 Lock() 写锁定 原理
写锁定需要实现两个动作: 1. 获取互斥锁;2. 阻塞等待所有读操作结束(如果存在未结束的读操作)
Go
// 锁定rw进行写入。
// 如果锁已经被锁定用于读取或写入,
// 锁定块,直到锁定可用。
func (rw *RWMutex) Lock() {
// 首先,解决与其他作家的竞争。
// rw.w 是 Mutex 锁,Lock 操作 会阻塞获取锁
// 如果有多个写操作竞争锁,那么会使用 Mutex 的策略,进行排队或自旋 获取锁
rw.w.Lock()
// 向读者宣布有一个待定的作者。
// 假设 raderCount = 2 , rwmutexMaxReaders = 100
// 并发安全的 2 - 100 = -98
// 并发不安全的 -98 + 100 = 2
// 拿到了 raderCount
// 因为 raderCount 是 int32 类型,并不是 atomic.Int32,所以不能使用 Load() 方法并发安全的获取值
// func AddInt32(addr *int32, delta int32) (new int32)
// 直接调用底层方法,让一个普通的 int32 拥有了 atomic 的能力
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxReaders
//等待活动的读卡器。
// 如果读操作不为空,那么将当前写操作记录到 写阻塞时,读操作的个数
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
// 等待读操作结束后释放信号量,这里是阻塞的,等待 writerSem 地址的信号量
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
}需要注意一点,在 Lock() 操作里面 readerCount 因为溢出,现在是负值
最开始的时候, readerCount 是 0 , 当 Lock 后,是 负的 max
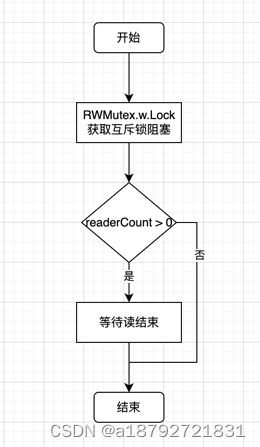
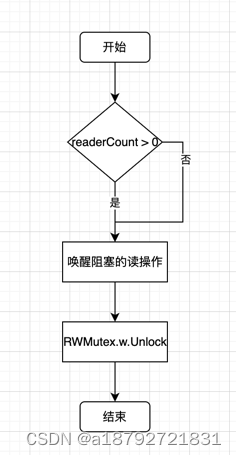
2.4 Unlock() 写锁定解锁 原理
写锁定解锁要实现的两个动作: 1. 唤醒因读锁定而被阻塞的协程(如果有)(写操作的同时发生的读操作,因为写操作还未完成,所以读操作需要等待写操作完成后才能进行读); 2. 解除互斥锁(写操作必须先获取 Mutex )
Go
//解锁解锁rw进行写入。如果rw为
//未锁定,无法在输入解锁时写入。
//
//与Mutex一样,锁定的RWMutex与特定的
//goroutine。一个goroutine可以RLock(Lock)一个RWMutex,然后
//安排另一个goroutine来解锁它。
func (rw *RWMutex) Unlock() {
//向读者宣布没有活动的写入程序。
// 因为在 Lock 中, raderCount 的值被置为负值
// 所以在这里在 加上 rwmutexMaxReaders ,readerCount 的值就变成了正值
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
// 如果出现溢出,,那么是错误的
if r >= rwmutexMaxReaders {
throw("sync: Unlock of unlocked RWMutex")
}
// 取消阻止被阻止的读卡器(如果有的话)。
// 因为存在 r 个读操作因为写操作而阻塞,当写操作完成时,就需要唤醒读操作
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
//允许其他写入程序继续。
// 释放锁,等待下次写操作
rw.w.Unlock()
}这里其实有一点小的不同,当写操作锁释放时,如果即存在读操作等待,又存在写操作等待,那么是优先读操作的。
也就是: 读 -> 写 -> 读 -> ...
这里引申出来一个思考,假设在读操作中,不断的派生,导致读操作占用一直无法结束,那么就会导致写操作加锁也无法加锁
写锁定解除的时候,将 readerCount + max ,获取到真正的 reader waiter
然后释放 reader waiter 个信号量,唤醒全部等待的读锁定
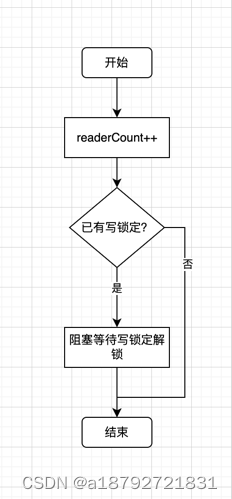
2.5 RLock() 读锁定 原理
读操作加锁需要的动作: 1. 增加读操作计数器; 2. 阻塞等待写锁定解锁(如果有)
Go
// 在关系通过以下方式指示给竞赛检测器之前发生:
// - Unlock -> Lock: readerSem
// - Unlock -> RLock: readerSem
// - RUnlock -> Lock: writerSem
//
// 以下方法暂时禁用竞赛同步的处理
// 事件,以便为比赛提供更精确的模型 探测器
//
// 例如,原子。RLock中的AddInt32不应显示为提供
// 获取发布语义,这将错误地同步比赛
// 读者,从而可能错过种族。
// RLock锁定rw进行读取。
//
// 它不应用于递归读取锁定;被锁住的锁
// 调用将阻止新读者获取锁。请参阅
// RWMutex类型的文档。
func (rw *RWMutex) RLock() {
// 在写锁定里面,会将 raderCount 置为负数,所以如果给 raderCount + 1 依然小于 0
// 那么说明至少有一个读锁定在阻塞等待写锁定解锁
// 换句话说,当 raderCount + 1 小于 0 ,说明有协程正在 写锁定
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
//有一个写入程序正在挂起,请稍候。
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
}因为在 写锁定 操作中,是直接减去最大值,所以这里实际上是不会限制读锁加锁数量的,也就是说,如果不断派生,那么读操作可能永远无法结束。
写锁定饿死?
这里要分为两种场景:
- RWMutex 无锁定,那么 readerCount > 0 ,就是读锁定个数
- RWMutex 有写锁定,那么 readerCount < 0 , 读锁定个数 = readerCount + max
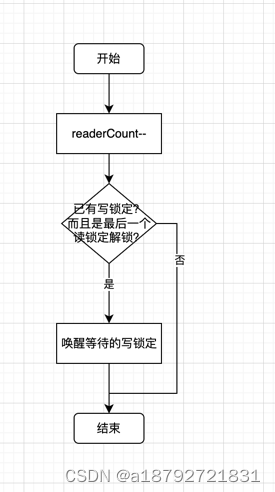
2.6 RUnlock() 读锁定解锁 原理
读锁定解锁的动作: 1. 减少读操作计数器; 2. 唤醒等待的写锁定(如果有)
Go
// RUnlock撤消单个RLock调用;
// 它不会影响其他同时阅读的人。
// 如果rw未锁定以进行读取,则是运行时错误
// 在进入RUnlock时。
func (rw *RWMutex) RUnlock() {
// 在 RUnlock 中,readerCount 是不能变为负值的,如果变为负值,
// 说明读锁在未拿到锁的情况下,调用了 RUnlock
// 也有可能是还未加锁就解锁,加锁 readerCount++, 解锁 readerCount--
// 还有一种情况是,存在读锁定的时候,出现了写锁定,写锁定会将 readerCount 变为负值
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
//勾勒出慢速路径以允许快速路径内联
rw.rUnlockSlow(r)
}
}
Go
func (rw *RWMutex) rUnlockSlow(r int32) {
// 如果 r - 1 = -1 那么说明是未加锁就解锁,异常
// 如果 r + 1 = - max , 加锁数量超过最大值,异常
if r+1 == 0 || r+1 == -rwmutexMaxReaders {
throw("sync: RUnlock of unlocked RWMutex")
}
// A writer is pending.
// 如果 是 写锁定情况下 读锁定解锁,此时会判断 readerWait 的值
// 防止 写锁定 饿死,在写锁定的时候,会同步 readerWait = readerCount
// 比如 写锁定时 readerCount = n , 此时 readerWait = n ,同时会将 readerCount 变为负值
// 变为负值后,读锁定就会阻塞
// 然后等待 读锁定解锁
// 在读锁定解锁的时候,进入 rUnlockSlow 就说明,有 写锁定 在阻塞
// 此时 readerWait > 0 , 那么每次读锁定解锁,会将 readerWait--
// 当 readerWait 等于 0 的时候,需要唤醒写锁定
// 用这样的逻辑防止 写锁定 饿死
// 只有最后一个才唤醒
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
// The last reader unblocks the writer.
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
3. 场景分析
3.1 写锁定如何阻塞写锁定
RWMutex 包含了一个 Mutex ,获取写锁定必须获取 Mutex ,如果已经有写锁定获取了 Mutex
那么后续的写锁定就必须等待前面的写锁定释放 Mutex 才能继续写锁定。
3.2 写锁定如何阻塞读锁定
写锁定会将 readerCount 的值变为负值,在读锁定里面,如果 readerCount + 1 < 0 那么会进入阻塞。
将 readerCount 的值变为负值,不会导致 readerCount 的原始值丢失,只需要 readerCount + max
就能重新拿到真实的值,并且期间针对 readerCount 的运算结果也能继续保留下来。
这个实现非常精妙,值得学习。
3.3 读锁定如何阻塞写锁定
读锁定会将 readerCount + 1 ,写锁定读取到 readerCount 不为 0 ,就会阻塞,
同时设置 readerWait = readerCount ,防止写锁定饿死
3.4 写锁定不会被 饿死
写锁定需要等待读锁定解锁后才能获取锁,写锁定的等待期间可能还有新的读锁定,那么可能永远等不到全部的读锁定解锁。
这样写锁定就出现 饿死
但是实际上是写锁定会将 readerCount 的值放到 readerWait 中,并且将 readerCount 的值变为负值
当 readerCount 的值变为负值,就不会有新的 读锁定了,读锁定因为 readerCount + 1 < 0 而进入阻塞
在 读锁定解锁的时候,如果 readerWait + 1 = 0 ,就会唤醒写锁定
相当于 当读锁定还未解锁时,写锁定会将当前读锁定的数量记下来,然后阻塞新增新的读锁定
等待记录的读锁定解锁后,就进行写锁定
强行将读锁定分割,避免饿死