一、简介

文章:https://arxiv.org/abs/2406.07476
代码:https://github.com/DAMO-NLP-SG/VideoLLaMA2
VideoLLaMA 2是由阿里巴巴集团的DAMO Academy团队开发的视频大型语言模型(Video-LLM),旨在通过增强空间-时间建模和音频理解能力,提升视频和音频导向任务的性能。该模型在前代基础上,引入了定制的时空卷积(STC)连接器,有效捕捉视频数据的复杂空间和时间动态。此外,通过联合训练集成了音频分支,增强了模型的多模态理解能力。在多项选择视频问答(MC-VQA)、开放式视频问答(OE-VQA)和视频字幕生成(VC)任务的综合评估中,VideoLLaMA 2展示了与开源模型相比具有竞争力的结果,并在某些专有模型上表现相近。
二、创新点
- 多模态理解能力提升 :VideoLLaMA 2在多模态综合理解方面表现出色,这得益于其对视频和音频数据的联合处理和理解。
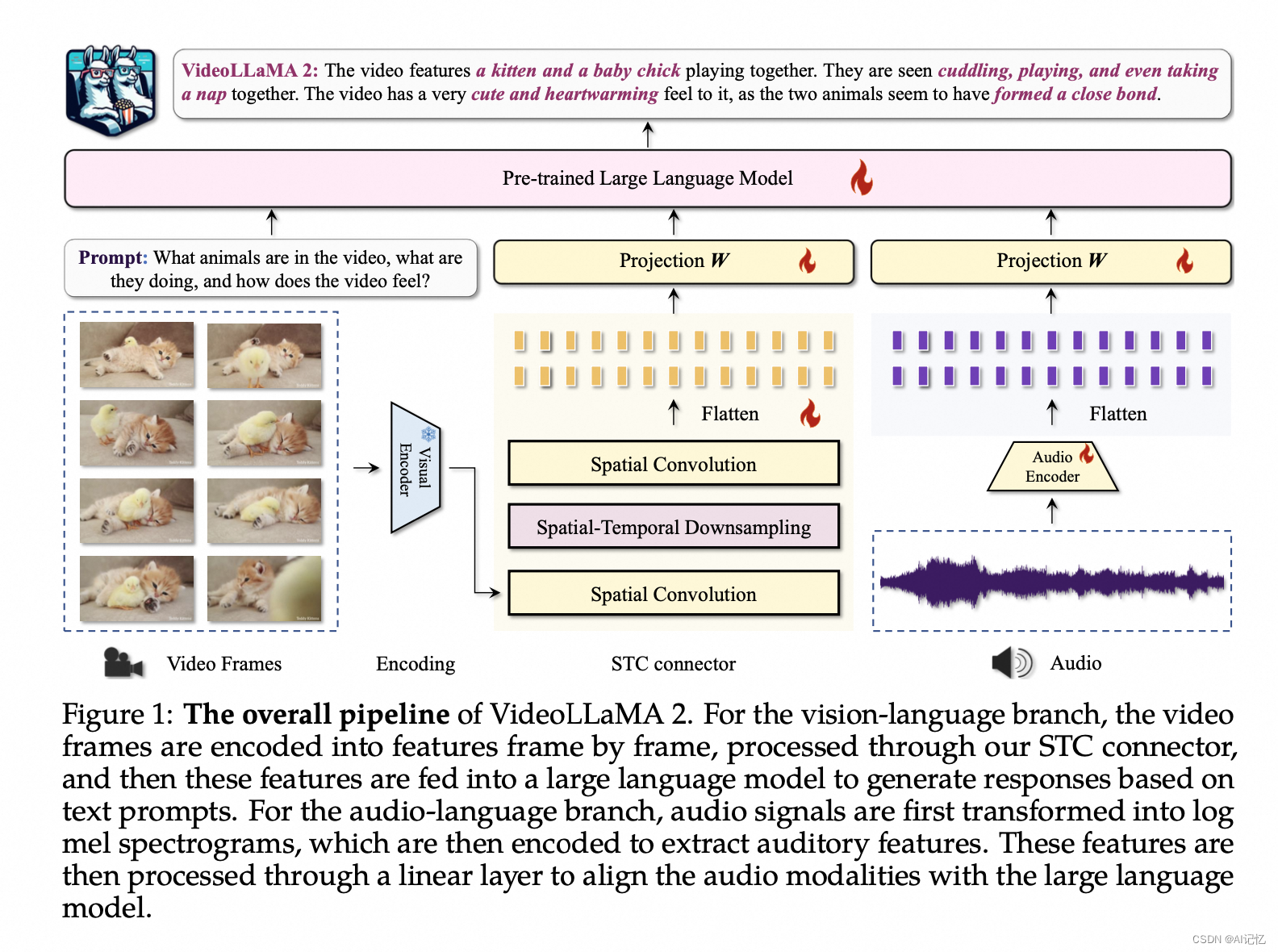
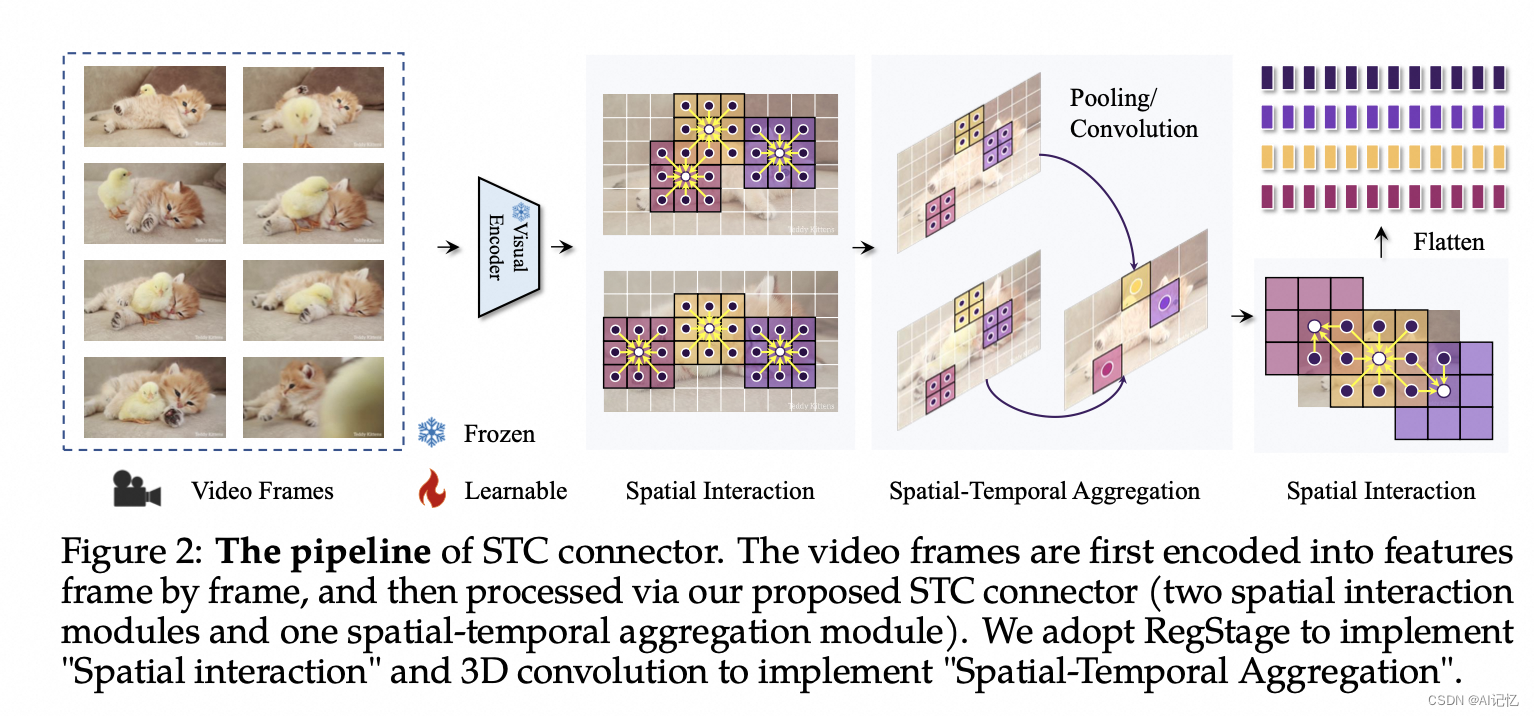
- 时空卷积(STC)连接器 :VideoLLaMA 2的一个关键创新是STC连接器,它用于有效捕捉视频数据的空间和时间动态。
三、实验结果
a.)定性结果

b.)定量结果
实验部分对VideoLLaMA 2在多个视频和音频理解任务上的性能进行了全面评估,包括:
-
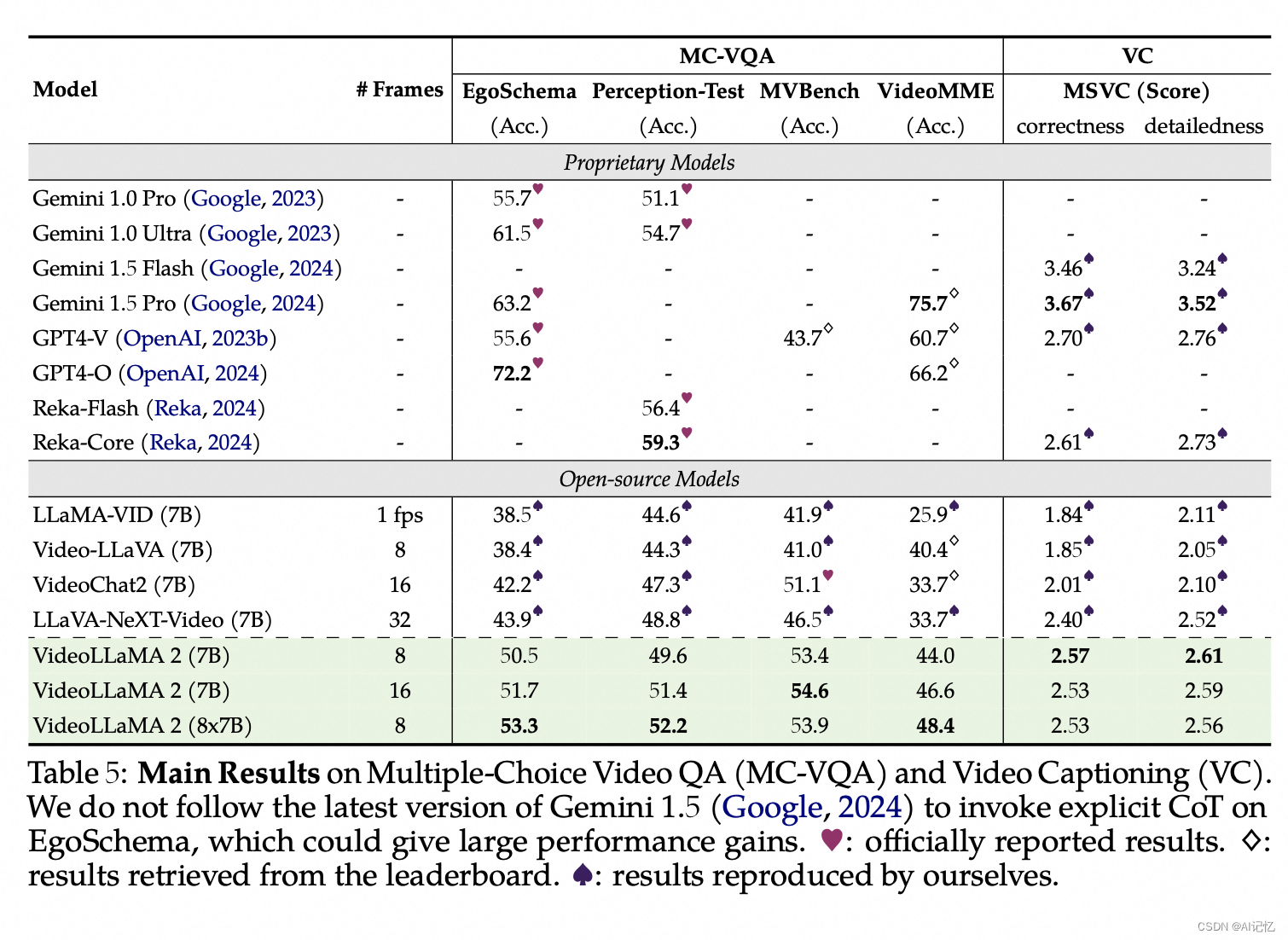
多项选择视频问答 (MC-VQA) :在EgoSchema、PerceptionTest、MV-Bench和VideoMME等数据集上,VideoLLaMA 2展示了与开源模型相比的显著性能提升,并在某些情况下接近专有模型的结果。另外在视频字幕生成,MSVC数据集上,VideoLLaMA 2在正确性和详细性方面得分,展示了模型在解释动态视频内容方面的强大能力。
-
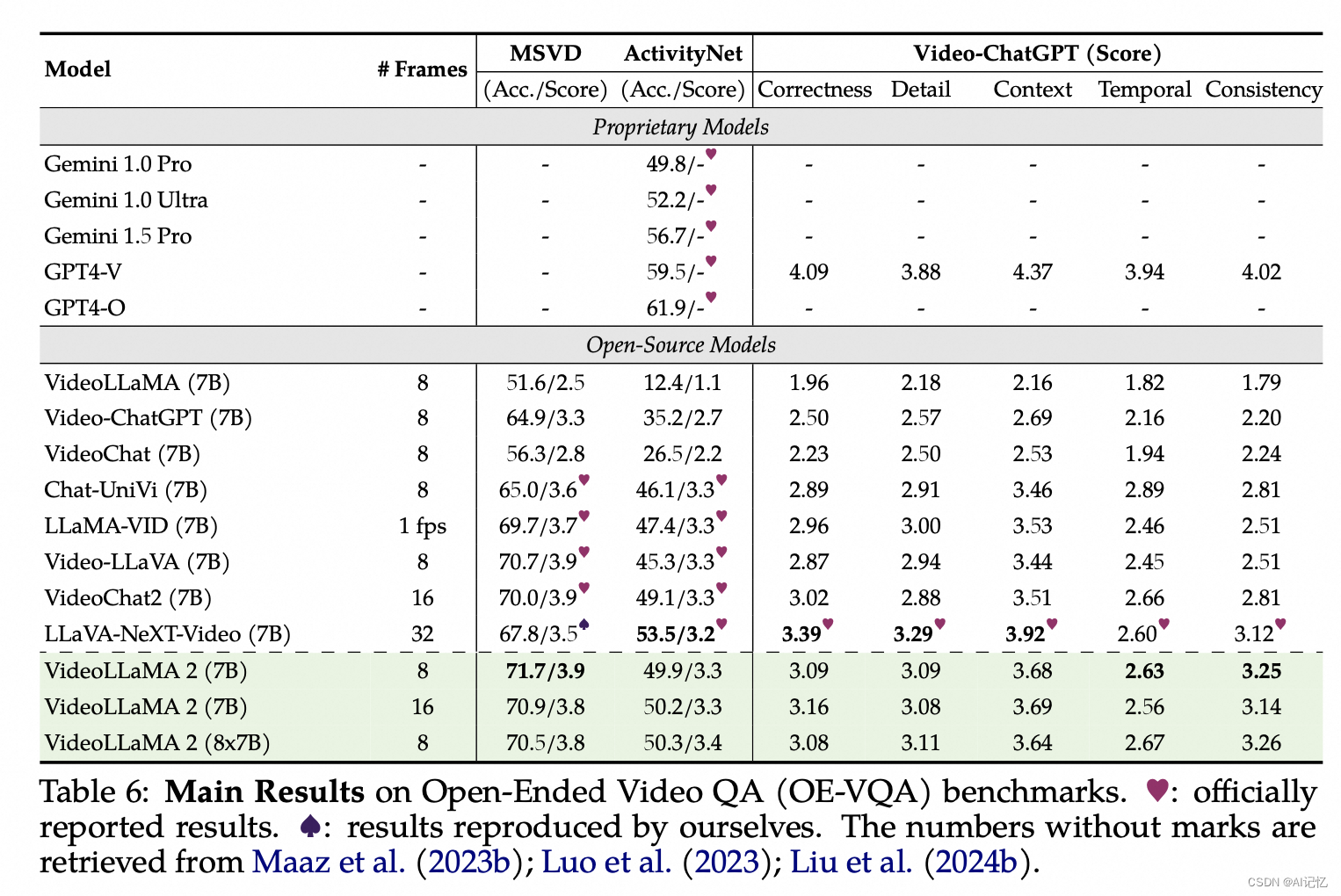
开放式视频问答 (OE-VQA) :在MSVD-QA、ActivityNet-QA和Video-ChatGPT等数据集上,VideoLLaMA 2在生成答案的质量上与其他模型进行了比较,使用GPT-3.5辅助评估来确定答案的正确性。
c.)Ablation Study
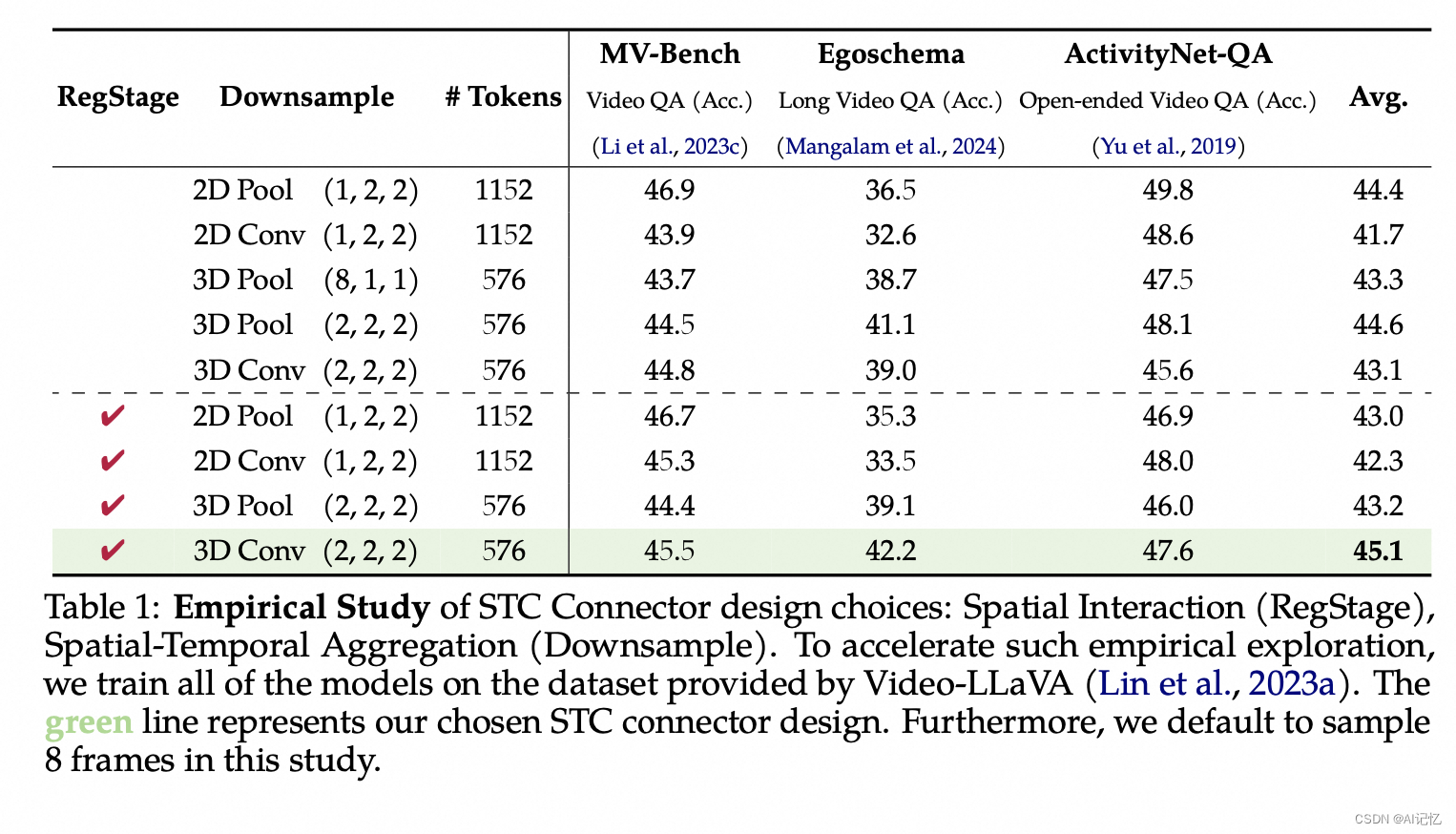
文中提供的消融研究(Ablation Study)细节如下:
- STC连接器设计选择 :通过实证研究STC连接器中空间交互(RegStage)和时空聚合(Downsample)的不同设计选择,发现3D卷积与RegStage块结合(即STC连接器)在平均性能方面表现最佳。