

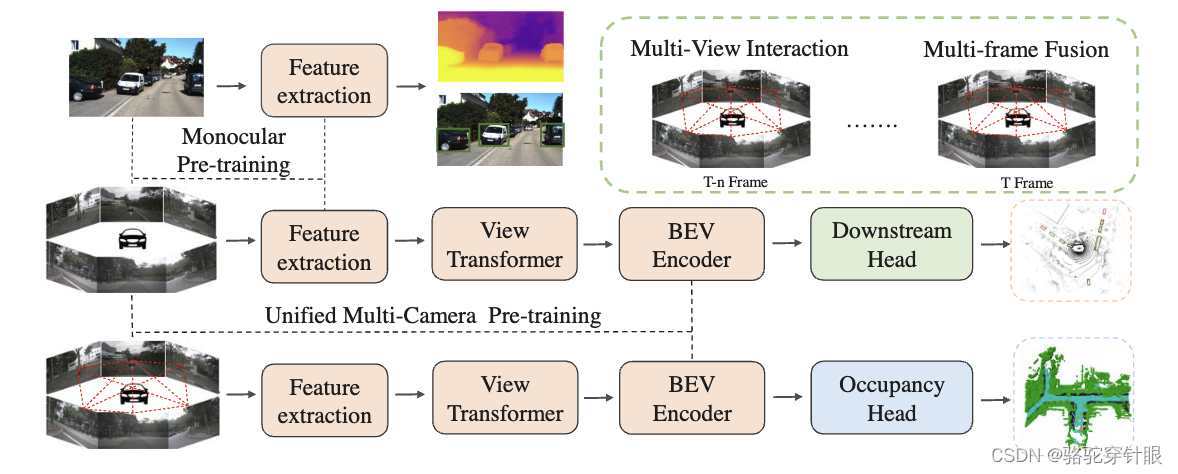
多摄像头三维感知已成为自动驾驶领域的一个重要研究领域,为基于激光雷达的解决方案提供了一种可行且具有成本效益的替代方案。具有成本效益的解决方案。现有的多摄像头算法主要依赖于单目 2D 预训练。然而,单目 2D 预训练忽略了多摄像头在空间和时间上的相关性。多摄像头系统之间的时空相关性。针对这一局限性,我们提出了首个多摄像头统一预训练框架。
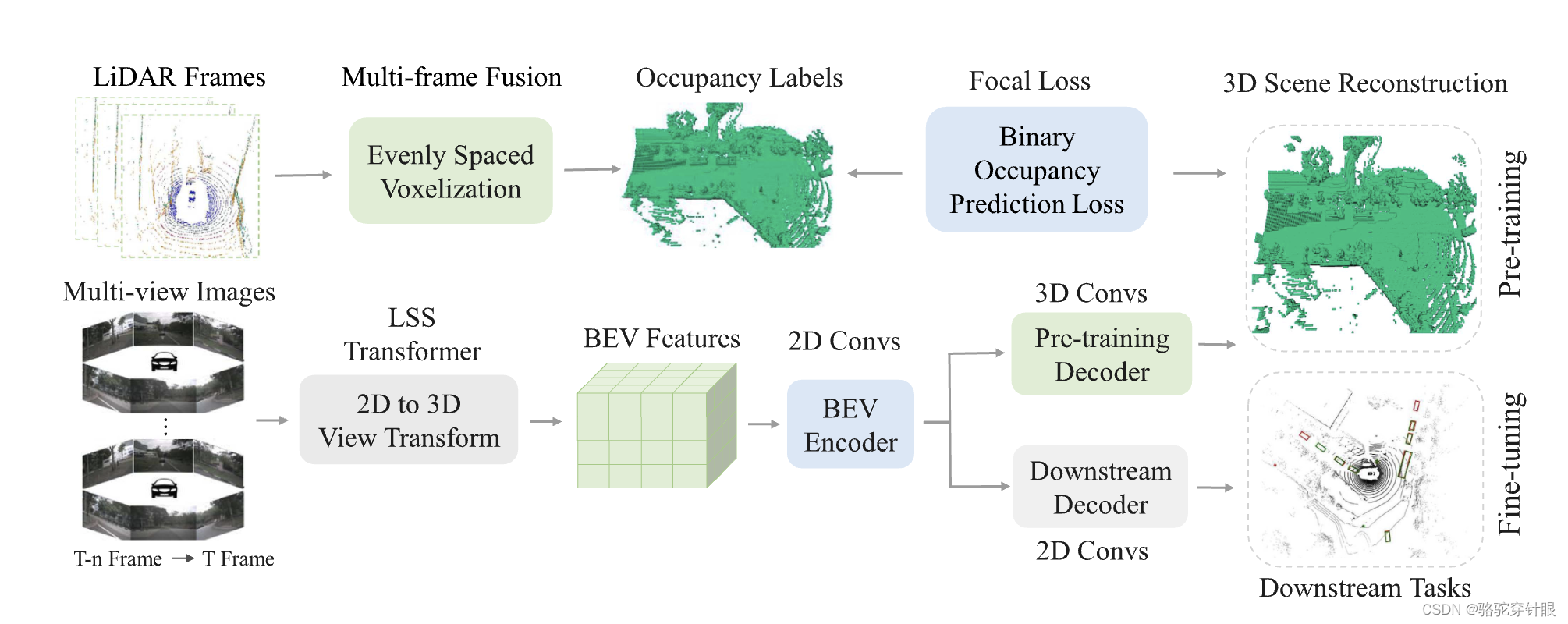
首先重建三维场景作为基础阶段,然后对模型进行微调随后在下游任务中对模型进行微调。具体来说,我们采用 "占位"(Occupancy)作为三维场景的一般表示方法
三维场景的一般表征,使模型能够通过预训练掌握周围世界的几何先验
通过预训练,模型能够掌握周围世界的几何先验。UniScene 的一个显著优势是,它能够利用大量未标记的图像UniScene 的一个显著优势是它能够利用大量未标记的图像-LiDAR 对进行预训练。该所提出的多摄像头统一预训练框架在一些关键任务中取得了可喜的成果,如多摄像头三维物体检测和周边语义场景补全。
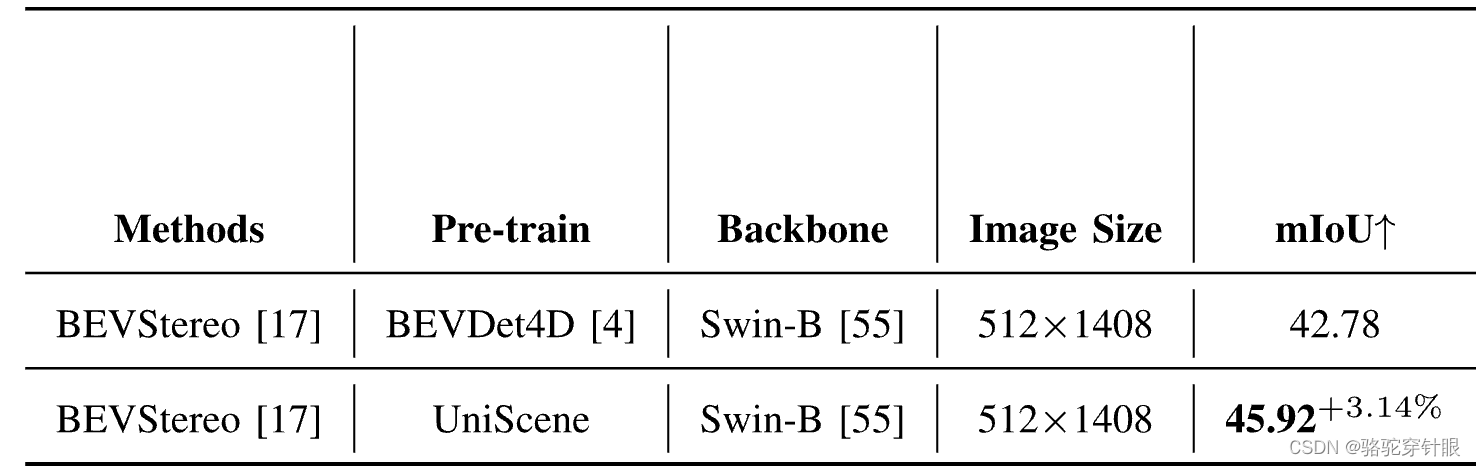
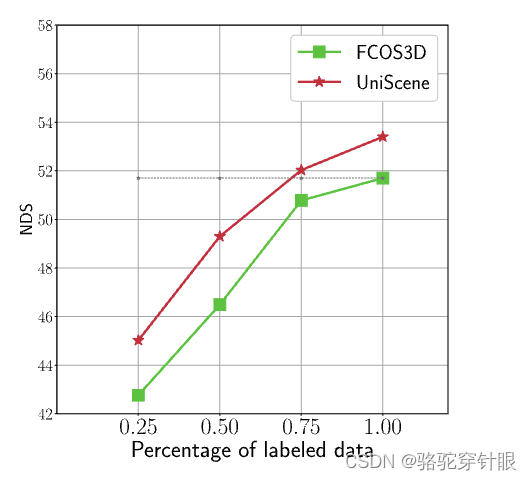
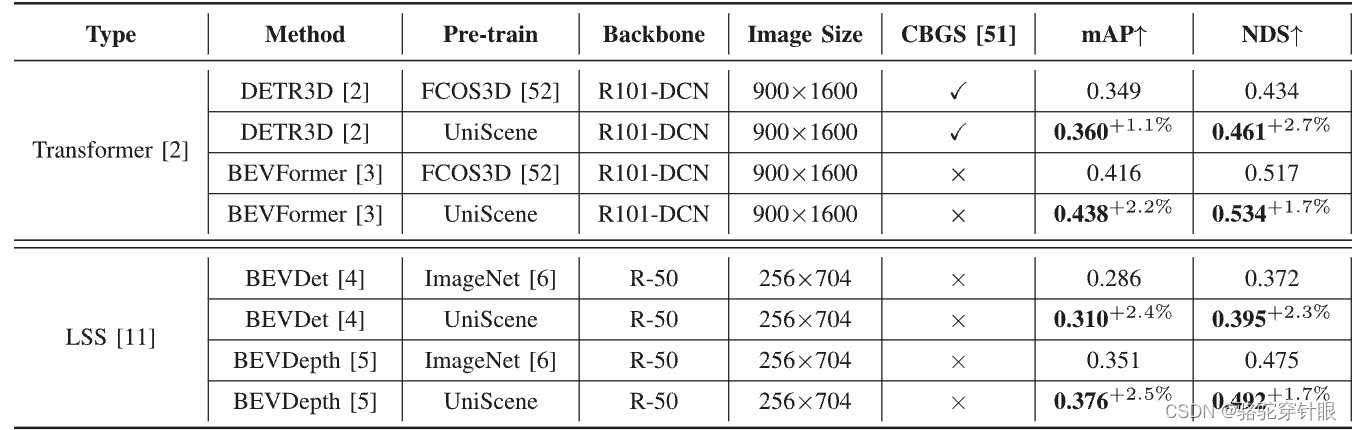
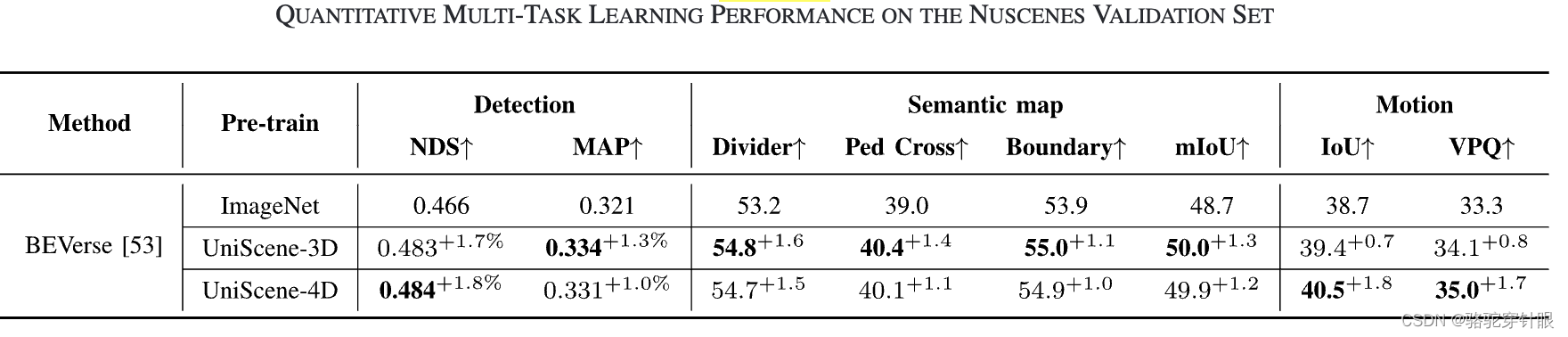
物体检测和周边语义场景补全等关键任务中取得了可喜的成果。与单目预训练方法相比,UniScene在多摄像头三维物体检测和周边语义场景补全中,UniScene 的 mAP 和 NDS 分别大幅提高了约 2.0% 和 2.0以及周围语义场景的 mIoU 提高了 3%。在周边语义场景补全方面,mIoU 提高了 3%。通过采用通过采用我们的统一预训练方法,可将三维训练和注释成本降低 25%。注释成本可降低 25%,为实现真实世界中的自动驾驶提供了重要的实用价值。
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是多摄像头3D感知在自动驾驶领域的挑战,特别是现有多摄像头算法主要依赖于单目2D预训练,忽略了多摄像头系统中的空间和时间相关性。为了解决这个限制,论文提出了一个名为UniScene的首个多摄像头统一预训练框架。该框架首先通过3D场景重建作为基础阶段,然后在下游任务上对模型进行微调。具体来说,论文采用了占用(Occupancy)作为3D场景的通用表示,使模型能够在预训练过程中掌握周围世界的几何先验。通过这种方式,UniScene能够利用大量的未标记的图像-LiDAR对进行预训练,从而提高了多摄像头3D目标检测和周围语义场景完成等关键任务的性能。
对 BEV 感知的结构图
单目和多目的对比
Q: 论文如何解决这个问题?
A: 论文提出了一个名为UniScene的多摄像头统一预训练框架,通过以下步骤解决多摄像头3D感知的问题:
-
3D场景重建:首先,使用多摄像头系统重建3D场景,作为预训练的基础阶段。这一步骤利用了占用(Occupancy)作为3D场景的通用表示,使模型能够通过预训练掌握周围世界的几何先验。
-
无标签预训练:UniScene的预训练过程不需要标签,可以利用自动驾驶车辆收集的大量图像-LiDAR对,这些数据对包含了宝贵的3D空间和结构信息。
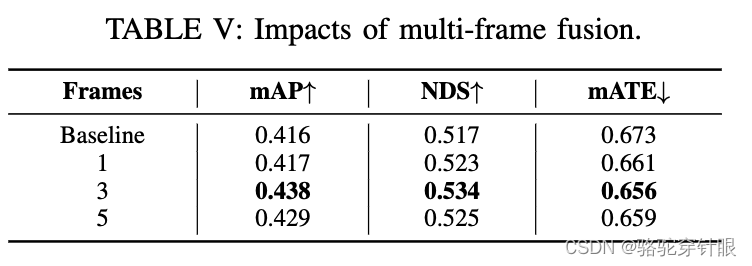
- 多帧点云融合:由于单帧点云的稀疏性,论文采用了多帧点云融合作为占用标签生成的真值。这通过融合关键帧的LiDAR点云来实现。
- 几何占位预测头:在BEV(鸟瞰图)特征上加入一个几何占用预测头,以学习3D占用分布,从而增强模型对3D周围场景的理解。
-
预训练和微调:在预训练阶段,使用轻量级解码器来重建占用体素。预训练完成后,丢弃解码器,并使用训练好的模型来初始化多摄像头感知模型,然后在下游任务上进行微调
-
空间-时间整合:通过利用多个摄像头视图的空间和时间信息,模型能够更好地理解环境的动态特性,并做出更准确的预测。
-
统一表示:统一预训练方法允许模型学习不同摄像头视图之间的共享表示,促进更好的知识迁移,并减少对特定任务预训练的需求。
-
处理遮挡区域:与单目深度估计方法相比,UniScene能够实现遮挡对象的整体3D重建。
-

-
考虑到单帧激光雷达点云的稀疏性,以及由于动态对象的存在而融合大量帧所产生的潜在不精确性,我们融合了一些关键帧的激光雷达点云和生成占用标签。根据3D感知模型的标准实践45,46,47,48,激光雷达点云被划分为均匀间隔的体素。对于激光雷达点云沿Z×Y×X的维度分别为D×H×W,体素大小相应地确定为vZ×vH×vW。体素的占用,即在每个体素中是否包含点,用作基本事实T∈{0,1}D×H×W×1。1表示已占用,0表示空闲。
-
介绍了用于预训练多摄像机感知模型的二进制几何占用分类任务。该任务的目的是训练网络基于多视图图像准确预测3D场景的几何占用分布。考虑到大量的空体素,预测占用网格提出了一个不平衡的二元分类问题。为了实现这一点,我们利用预测的占用值P和地面实况占用的体素T来计算二进制占用分类的焦点损失:
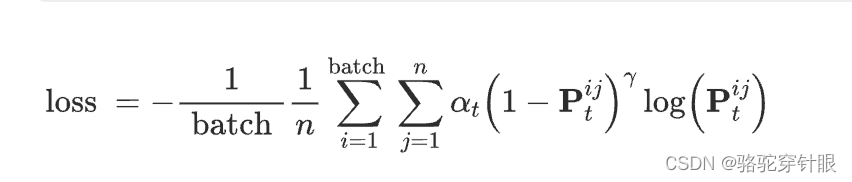

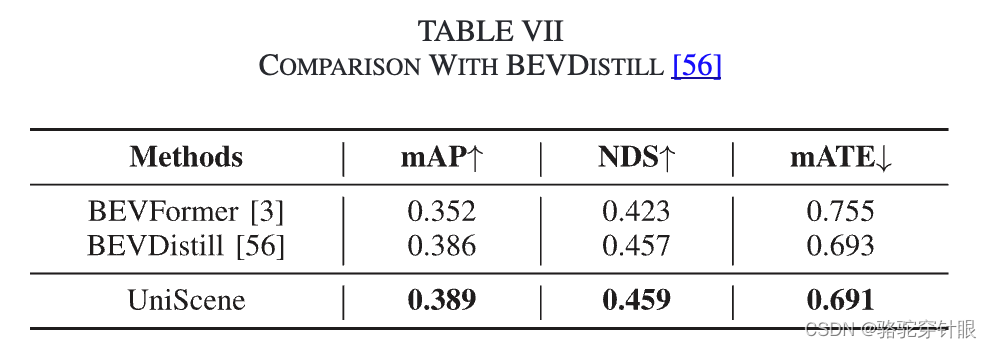
- 实验验证:通过在nuScenes数据集上进行广泛的实验,验证了UniScene框架在多摄像头3D目标检测和周围语义场景完成等关键任务中的有效性。
通过这些步骤,UniScene框架能够在预训练阶段利用未标记的数据,同时考虑空间和时间相关性,从而提高了模型对复杂3D场景的理解能力,并减少了对昂贵和耗时的手动3D注释的依赖。
Q: 总结一下论文的主要内容
-
问题定义:论文针对自动驾驶领域中多摄像头3D感知的问题,提出了现有算法主要依赖单目2D预训练,忽略了多摄像头系统中的空间和时间相关性。
-
UniScene框架:提出了首个多摄像头统一预训练框架UniScene,该框架通过3D场景重建作为预训练的基础阶段,然后在下游任务上对模型进行微调。
-
占用表示:采用占用(Occupancy)作为3D场景的通用表示,使模型能够在预训练过程中掌握周围世界的几何先验。
-
无标签预训练:UniScene能够利用大量的未标记的图像-LiDAR对进行预训练,减少了对昂贵3D标注的依赖。
-
实验验证:通过在nuScenes数据集上的实验,展示了UniScene在多摄像头3D目标检测和周围语义场景完成等任务中的性能提升。
-
性能提升:与单目预训练方法相比,UniScene在多摄像头3D目标检测任务上实现了约2.0%的mAP和NDS提升,在语义场景完成任务上实现了约3%的mIoU提升。
-
实际价值:通过采用UniScene的统一预训练方法,可以减少25%的3D训练注释成本,对实际自动驾驶系统的实施具有重要价值。
-
未来工作:论文指出了UniScene的局限性,并提出了未来工作的方向,包括提高分辨率、处理动态对象、利用显式监督和知识蒸馏技术等。

fine
uniscense_epoch_24
pretrain
occ_bev_epoch_24