文章目录
- [1 背景](#1 背景)
- [2 模块](#2 模块)
-
- [2.1 部分交叉熵损失](#2.1 部分交叉熵损失)
- [2.2 弱标签(线/点)](#2.2 弱标签(线/点))
- [2.3 Gated CRF Loss](#2.3 Gated CRF Loss)
- [3 效果](#3 效果)
-
- [3.1 总体效果](#3.1 总体效果)
- [3.2 消融实验](#3.2 消融实验)
- [4 总结](#4 总结)
- 参考文献
1 背景
全监督的语义分割需要对全图进行完全而精确的标注。当需要标注的目标在图像中较多,又或形状不规则,又或边界不清晰,人工进行标注的成本就极高,甚至无法进行标注。比如下图1-1所示,需要分割图片中的"脏污",这用全监督的方式训练该如何标注呢?图1-1中,我们可以确定一些区域必然是脏污,一些区域必然不是脏污,至于比较模糊的区域,使用弱监督的方式进行标注的话,就可以不标注,让模型自行判断。对于确定的区域,也不需要完全的标注,只需要标注部分即可。也就是说,对于图1-1,使用弱监督模型进行训练时,一种标注方式就是在确定是脏污的几个区域画几条线,在确定是背景的区域也画几条线就可以了。
弱监督的标注形式可以是点、线、多边形,只要不是讲所有目标完整地进行标注,均可称为弱监督。

图1-1 脏污样本示意图
本文要介绍的这篇文章讲了一种弱监督的损失,可以适用于任意的语义分割模型,对预测部分不会产生任何额外的代价。
所有的弱监督损失其实都在回答一个问题:如何利用未标注区域?
不要被这篇文章的题目吓到,又是Gated了,又是CRF,这些词我们都可以不管。我们只需要知道这篇文章把"如何利用未标注区域"分成了两个问题:
(1)哪些像素是无效区域,不加入损失的计算,即Gated
(2)如何描述有标注的像素和无标注像素之间的相似度,用于监督的引导,即CRF
2 模块
2.1 部分交叉熵损失
训练用于语义分割任务的神经网络 F F F 需要成对的图像 x x x 及其带标注的对应图像 y y y ,传递 C C C 类中的逐像素类分配。用 N N N 表示图像中的像素总数,预测结果 y ^ = F ( x ) \hat{y}=F(x) y^=F(x) 中类别 i i i 的概率为 y ^ ( i ) \hat{y}(i) y^(i) 。多类分类问题的传统损失是交叉熵损失,当标签 y y y 作为概率分布给出时(软标签),其形式为
L C E ( y ^ i , y i ) = − ∑ c = 1 C y i ( c ) l o g y ^ i ( c ) (2-1) L_{CE} (\hat{y}i, y_i) = -\sum{c=1}^C y_i(c) log\hat{y}_i(c) \tag{2-1} LCE(y^i,yi)=−c=1∑Cyi(c)logy^i(c)(2-1)
或当标签 y y y 具有类标签时(硬标签)
L C E ( y ^ i , y i ) = − l o g y ^ i ( y i ) (2-2) L_{CE} (\hat{y}_i, y_i) = -log\hat{y}_i(y_i) \tag{2-2} LCE(y^i,yi)=−logy^i(yi)(2-2)
在全监督中,训练图像的几乎所有像素都被标注,形成与 y y y 大小相同的标注像素 m i ∈ { 0 , 1 } m_i \in \{0, 1\} mi∈{0,1} 的密集图。在弱监督中,仅对训练图像的几个像素进行标注,形成标注像素 m i m_i mi 的部分图,其稀疏性取决于弱标注的类型(例如线、点)。由于未标注的像素不向学习过程提供任何信息,因此在用于通过反向传播计算梯度的损失函数中不考虑它们,即
L C E ( y ^ , y ) = ∑ i = 1 N m i L C E ( y ^ i , y i ) / ∑ i = 1 N m i (2-3) L_{CE} (\hat{y}, y) = \sum_{i=1}^N m_i L_{CE}(\hat{y}i, y_i) / \sum{i=1}^N m_i \tag{2-3} LCE(y^,y)=i=1∑NmiLCE(y^i,yi)/i=1∑Nmi(2-3)
由于标注像素 m i m_i mi的部分映射,弱监督语义分割的交叉熵损失通常称为部分交叉熵(pCE)。
2.2 弱标签(线/点)
典型的弱监督是由标注更少像素同时获得更多样本的动机驱动的。绘制多边形、涂鸦或边界框已被证明可以在标注时间和分割性能之间产生良好的折衷。与边界框相比,点击和涂鸦具有一些有价值的资产:
1)虽然稀疏,但标注的像素更加准确和可靠;
2)标注过程更加高效;
3)对象类和东西类(例如"天空"、"道路")可以以相同的方式处理。
图2-1展示了不同的标注方式以及对应训练出来的模型的效果。

图2-1 不同标注方式及模型效果示意图
2.3 Gated CRF Loss
本文着手寻找一种方法来最小化弱监督和完全监督语义分割之间的性能差距。作者希望在不依赖任何常用先验的情况下实现这一目标,例如"objectness";不扩大带标注的输入;没有在类似任务和数据集上预训练模型(即 COCO);无需使用复杂的训练程序或使用非常规最小化技术优化网络权重;并且不会生成"fake" proposals作为GT并进行多轮训练,这被证明会导致过拟合。
由于仅在弱标签上应用 pCE 通常无法提供接近语义边界的足够监督信号,因此在监督不可用的情况下,很自然地会出现更糟糕的预测。为了缓解这种情况,作者使用带标注的输入作为 pCE 监督信号的种子,并使用其他形式的正则化将其传播到周围像素。
首先定义类别 i i i 和 j j j 在位置 a a a 和 b b b 的能量方程
ψ a , b ( i , j ) = μ ( i , j ) K a b (2-4) \psi_{a, b}(i, j) = \mu (i,j) K_{ab} \tag{2-4} ψa,b(i,j)=μ(i,j)Kab(2-4)
其中
K a b = ∑ p = 1 P w ( p ) k ( p ) ( f a ( p ) , f b ( p ) ) (2-5) K_{ab} = \sum_{p=1}^{P} w^{(p)} k^{(p)}(f_a^{(p)}, f_b^{(p)}) \tag{2-5} Kab=p=1∑Pw(p)k(p)(fa(p),fb(p))(2-5)
ψ a , b \psi_{a,b} ψa,b 表示成对的潜在可能性, μ \mu μ 表示通用类兼容性矩阵,尺寸为 R C × C R^{C \times C} RC×C ,紧接着的是 P P P 个内核 k ( p ) ( ⋅ , ⋅ ) k^{(p)}(\cdot, \cdot) k(p)(⋅,⋅) 用于一对有权重 w ( p ) w^{(p)} w(p) 的位置。特征向量 f a ( p ) f_a^{(p)} fa(p) 是第 p p p 个内核独有的,并且不依赖于预测结果。实际情况下,通常由位置坐标或者输入的模态信息(RGB或者深度图)决定。作者使用的 k ( p ) ( ⋅ , ⋅ ) k^{(p)}(\cdot, \cdot) k(p)(⋅,⋅)为
k ( p ) ( f a ( p ) , f b ( p ) ) = e x p { − 1 2 ∣ f a ( p ) − f b ( p ) σ ( p ) ∣ 2 } (2-6) k^{(p)} (f_a^{(p)}, f_b^{(p)}) = exp\{ -\frac{1}{2}| \frac{f_a^{(p)} - f_b^{(p)}}{\sigma^{(p)}} |^2 \} \tag{2-6} k(p)(fa(p),fb(p))=exp{−21∣σ(p)fa(p)−fb(p)∣2}(2-6)
并且
μ ( i , j ) = { 0 , i f i = j 1 , o t h e r w i s e (2-7) \mu (i,j) = \begin{cases} 0, \ if\ i = j\\ 1, \ otherwise \end{cases} \tag{2-7} μ(i,j)={0, if i=j1, otherwise(2-7)
观察定义的能量项,很明显,在特征相似的情况下,如果两个位置的类标签不同,则其值会更高,也就是损失会很高。这种相似性是由内核的组合、权重和带宽定义的,在RGBXY内核的情况下,这些相似性会转化为5D颜色邻近相似性(RGB为3D,XY为2D,合起来为5D),图2-2中显示了一些示例。

图2-2 RGBXY内核下相似性可视化
现在,可以在位置 a a a 和 b b b 处写出预测 y ^ \hat{y} y^ 的能量,然后在"密集"设置中写出预测 y ^ \hat{y} y^ 的总能量,其中图像的每个像素都与其他每个像素相关
ψ a , b ( y ^ ) = ∑ i , c ∈ 1 , C ψ a , b ( i , j ) y ^ a ( i ) y ^ b ( j ) (2-8) \psi_{a, b}(\hat{y}) = \sum_{i, c \in 1, C} \psi_{a, b}(i, j)\hat{y}_a(i)\hat{y}_b(j) \tag{2-8} ψa,b(y^)=i,c∈1,C∑ψa,b(i,j)y^a(i)y^b(j)(2-8)
观察式2-8也可以发现,惩罚的主要是 y ^ a ( i ) \hat{y}_a(i) y^a(i)和 y ^ b ( j ) \hat{y}_b(j) y^b(j)置信度都很高,且特征相似类别不一致的情况。
总能量为
Ψ ( y ^ ) = ∑ a = 1 N ∑ b = 1 , b ≠ a N ψ a , b ( y ^ ) (2-9) \Psi(\hat{y}) = \sum^{N}{a=1} \sum^{N}{b=1, b \neq a} \psi_{a,b}(\hat{y}) \tag{2-9} Ψ(y^)=a=1∑Nb=1,b=a∑Nψa,b(y^)(2-9)
Gated CRF Loss的改进包括:
(1) b ≠ a b \neq a b=a 条件指定总能量项不包括自标记能量。然而,除了自身位置 a a a 之外,还有其他像素位置可能需要从总能量中排除。排除点可以是标记为无效的像素,无论是 RGB 图像中曝光过度/曝光不足的区域,还是其他模式(例如深度图)中丢失的数据。 "待排除"区域也可以通过一些常用的计算操作生成,例如通过深度学习框架的数据增强(图像裁剪和旋转)生成的 RGB 图像的出界区域 。为了排除这些像素影响其他像素,作者定义了一个与图像 x x x 大小相同的源图 m s r c m^{src} msrc ,其中 m a s r c ∈ { 0 , 1 } m_a^{src}\in\{0, 1\} masrc∈{0,1},其中 1 表示可用于为任意像素提供成对能量的像素,否则为 0。
(2)所有位置 a ∈ 1 , N a \in 1, N a∈1,N 的求和的假设条件是总能量是作为这样的累积而找到的。对于某些情况(包括弱监督分割)来说,这也是过度简单化。对于此任务,可能需要排除带标注的位置免受其他像素的影响 ,因为 pCE 损失在这些位置上提供了直接且更强的监督。简而言之,如果 pCE 正确分类了标注像素的标签,那么应用 CRF 能量项来"纠正"它们不会带来额外的好处。为了排除这些像素接收能量,作者定义了一个与图像 x x x 大小相同的目标图 m a d s t m_a^{dst} madst ,其中 m a d s t ∈ { 0 , 1 } m_a^{dst} \in \{0, 1\} madst∈{0,1} ,其中 1 表示可用于接收和累积成对能量的像素图像中的任何其他位置,否则为 0
(3)假设所有核都是高斯分布并且特征向量 k ( p ) k^{(p)} k(p) 包含位置坐标,对于任何固定位置 a a a ,联合标记 a a a 和 b b b 的成对能量将随着距 a a a 的距离而减小。具有长范围求和的 CRF 损失对结合 pCE 和 CRF 损失的深度神经网络的联合训练提出了巨大的计算挑战。作者认为,当与相当简单的一元项模型一起使用时,CRF 设置的"密集"属性对于捕获像素之间的远程关系至关重要。目前的语义分割模型本身可以有效地捕获全局上下文。因此,拥有密集的成对项可能不会带来额外的好处(即模型下采样后,本身就具备全局关联性)。更重要的是,这需要使用高维过滤技术来减轻过高的计算复杂性,这也使内核项的操作变得复杂。作者认为,在弱监督语义分割的背景下,将 b b b 的求和范围限制为局部邻域 Ω ( a ) \Omega(a) Ω(a) 是有益的 ,该局部邻域由可接受的信号损失和内核带宽 σ ( p ) \sigma^{(p)} σ(p) 的函数来表征。
为解决(1)(2)中的问题,重写式2-4来支持门控信息传播
ψ a , b ( i , j ) = μ ( i , j ) G a b K a b (2-10) \psi_{a, b}(i, j) = \mu (i,j) G_{ab} K_{ab} \tag{2-10} ψa,b(i,j)=μ(i,j)GabKab(2-10)
完整的能量方程变为
Ψ ( y ^ ) = ∑ a = 1 N ∑ b ∈ Ω r ( a ) , b ≠ a N ψ a , b ( y ^ ) (2-11) \Psi(\hat{y}) = \sum^{N}{a=1} \sum^{N}{b \in \Omega_r(a), b \neq a} \psi_{a,b}(\hat{y}) \tag{2-11} Ψ(y^)=a=1∑Nb∈Ωr(a),b=a∑Nψa,b(y^)(2-11)
后一种表示可以使用标准张量运算有效地计算。由于损失函数直接嵌入到网络中,因此在训练期间局部影响会传播到图像的整个范围。
提出的Gated CRF Loss只是预测类别概率的总能量:
L G C R F ( y ^ ) = Ψ ( y ^ ) / ∑ i = 1 N m i d s t (2-12) L_{GCRF}(\hat{y}) = \Psi(\hat{y}) / \sum_{i=1}^N m_i^{dst} \tag{2-12} LGCRF(y^)=Ψ(y^)/i=1∑Nmidst(2-12)
总损失为
L ( y ^ ) = L C E ( y , y ^ ) + λ L G C R F ( y ^ ) (2-13) L(\hat{y}) = L_{CE}(y, \hat{y}) + \lambda L_{GCRF}(\hat{y}) \tag{2-13} L(y^)=LCE(y,y^)+λLGCRF(y^)(2-13)
3 效果
3.1 总体效果
使用Gated CRF损失的模型和其他模型的对比可见下表3-1。
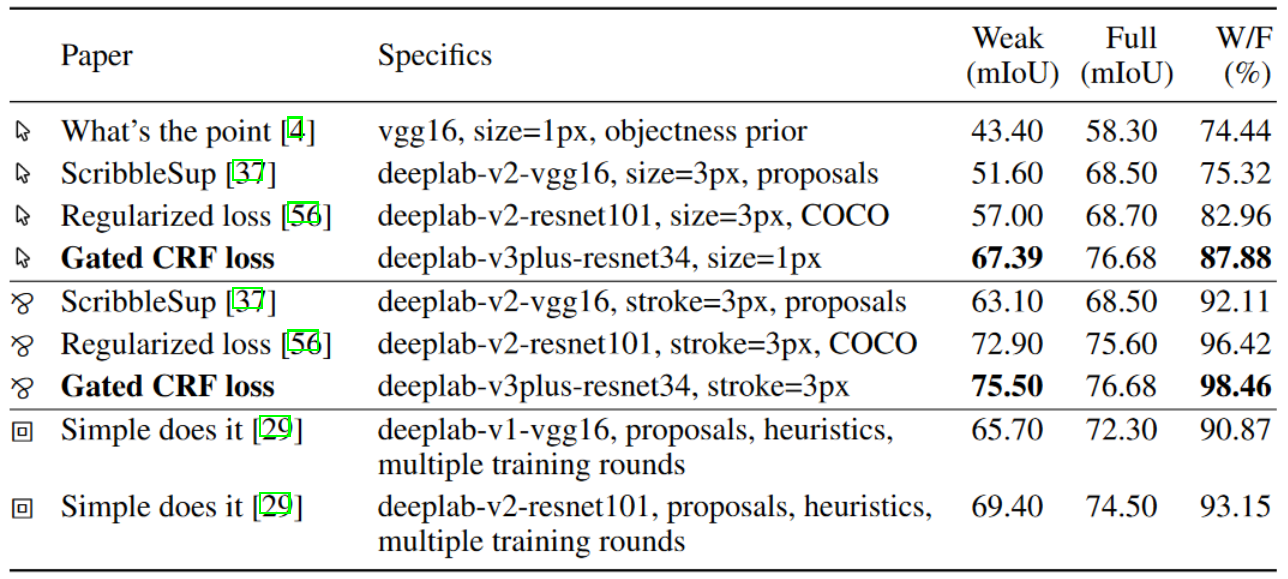
表3-1 Gated CRF损失的模型和其他模型的对比
3.2 消融实验
(1)Source and destination masking
表3-2中 G C R F s GCRF_s GCRFs表示使用了source masking, G C R F s , d GCRF_{s,d} GCRFs,d表示使用了source masking和destination masking。CS和VOC是不同的数据集,每个数据集不同的行表示不同的标注方式,点、线、完全标注。
表3-2表明source masking的效果最好,是必须要有的。进一步添加destination masking使Cityscapes数据集改善约 1%,但 Pascal VOC 恶化最多 0.20%。这可以通过两个数据集中弱标注的性质来解释。Cityscapes通常包含许多散布在图像周围的物体实例。这为 pCE 单独学习强类描述提供了足够的弱标注。因此,在这种情况下激活目标屏蔽是有意义的,因为它会抑制门控 CRF 丢失对更可靠的 pCE 的影响。然而,在 Pascal VOC 中,图像中通常只存在几个对象实例。因此,与 Cityscapes 相比,弱标注要少得多且稀疏,使得 pCE 的监督不太可靠。
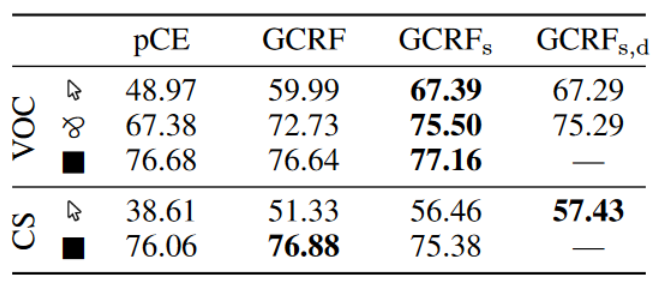
表3-2 Gated CRF损失的模型和其他模型的对比
(2)增大标注粗度
表3-3表明,即使像许多现有方法那样将点监督的大小从 1×1px 增加到 3×3px 看似微不足道,也会产生与基线情况相差 3% mIoU 的模型,即仅 PCE。然而,即使仅使用 1×1px 监督,在相同设置中与 pCE 一起使用的门控 CRF 损失也成功地弥补了这一差距。此外,任意放大带标注的输入并不总是有益的,因为它暗示了有关对象最小尺寸的先验知识,而对象的最小尺寸在数据集之间差异很大。例如,作者观察到,在 CityScapes 上仅使用 pCE 并没有从 1×1px 提高到 3×3px,可能是因为放大背景中非常小的对象的标注会导致其他类过度填充。
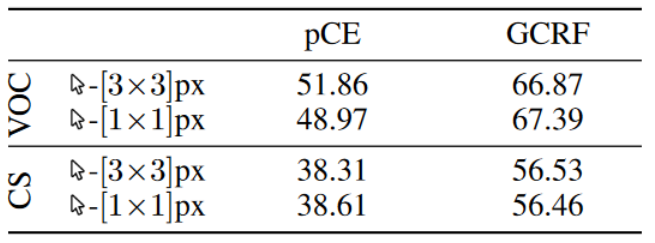
表3-3 增大标注粗度效果对比
(3)局部邻域尺寸
σ X Y \sigma_{XY} σXY表示核函数的带宽,其值越大,越远的像素起的作用越小。
表3-4表明了增大 σ X Y \sigma_{XY} σXY 并不会持续提高验证集的效果,可见前面说明的局部损失对全局也有影响的推测是正确的。这暗示局部应用的损失即使对于很小的 σ X Y \sigma_{XY} σXY也会产生全局影响。
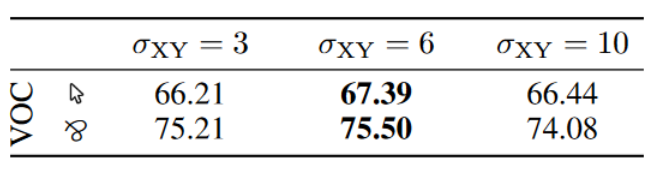
表3-4 不同局部邻域尺寸效果对比
图3-1说明了增大 σ X Y \sigma_{XY} σXY 对于细物体的结果更准,但是损失了边缘精度。

图3-1 不同局部邻域尺寸效果对比
(4)GatedCRF损失权重
表3-5展示了使用不同的门控 CRF 损失权重 λ \lambda λ 和 3 个级别的监督对 Pascal VOC 的影响。选择的 λ = 0.1 \lambda=0.1 λ=0.1 值给出了最佳的总体结果。然而,还观察到,至少对于选定的 λ 值范围,门控 CRF 损失的影响并没有显着减弱,这可能表明它不太容易出现损失平衡问题。
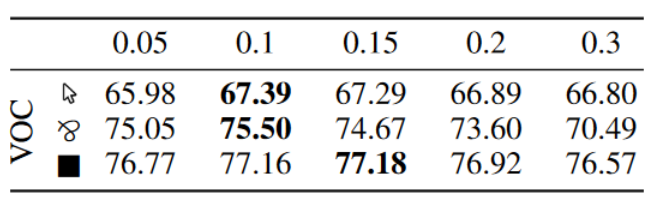
表3-5 不同GatedCRF权重的效果对比
4 总结
总的来说,GatedCRFLoss设计了一种范式。
使用者可以通过修改 f a p f_a^{p} fap和 f b p f_b^{p} fbp来用不同的方式描述两个像素之间的相似度。
使用者可以通过修改 σ X Y \sigma_{XY} σXY来控制不同距离的像素带来的影响程度。
使用者可以通过修改 G a b G_{ab} Gab来控制哪些像素参与损失的计算。
参考文献
1 Gated CRF Loss for Weakly Supervised Semantic Image Segmentation