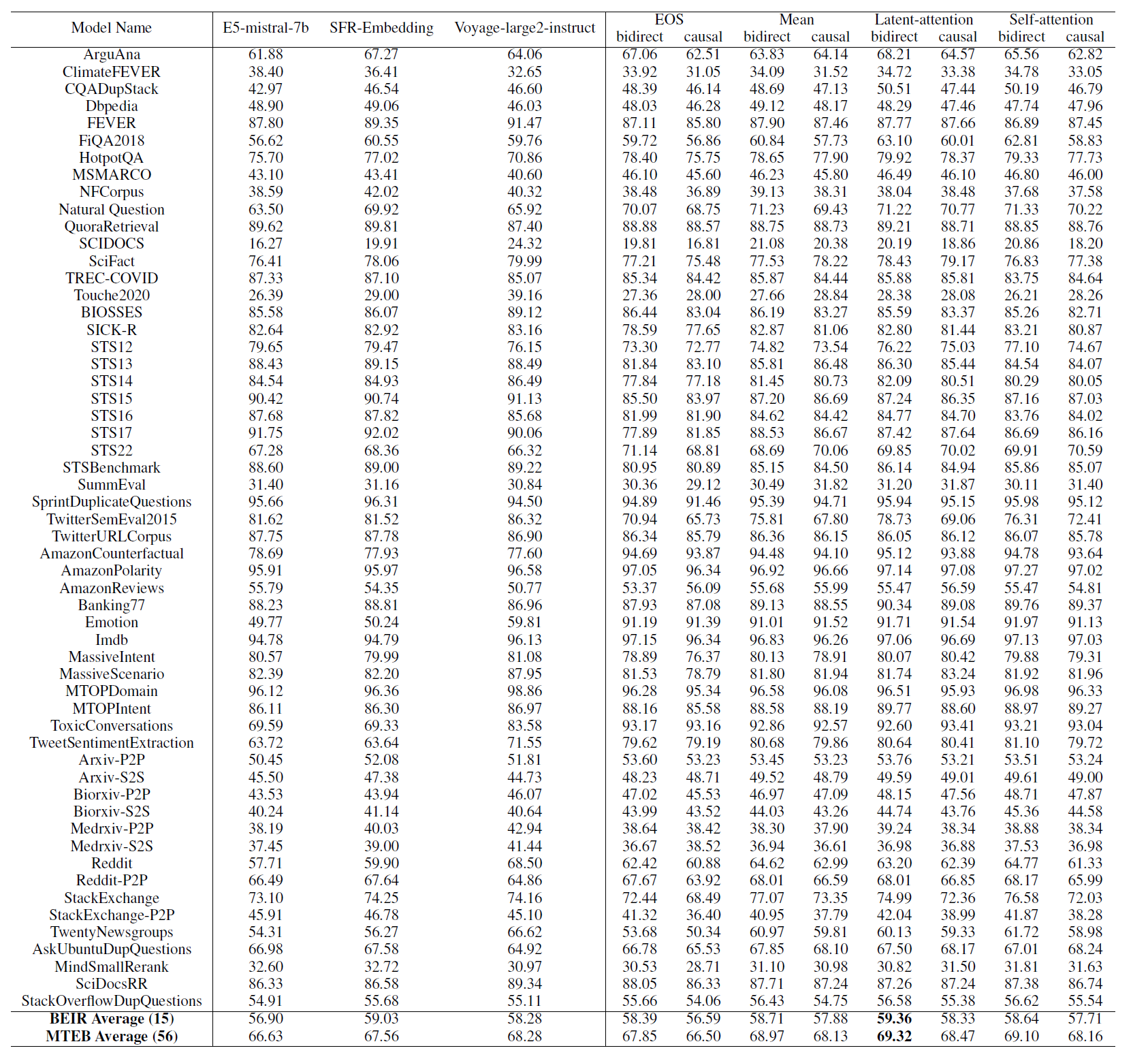
- 这是NVIDIA的一篇论文,LLM通常使用的是GPT的decoder范式作为一个生成模型,文章探讨如何利用这样的decoder生成模型来实现BERT这样的encoder的功能,即提取有效的embedding。
- 现有的方法提取embedding的方式无非是 1 mean pooling; 2 the last token embedding。前者是encoder-like的model用得多,后者是decoder-like的model用得多。然而这两者都有问题。
- 文章提出的方法是,decoder模型正常是会通过循环的方式生成一段序列嘛,最后一个time step的一层的Q就是 l × d l\times d l×d的, l l l个token每个 d d d维,然后我预定义一个latent array,是 r × d r\times d r×d的,它作为 r r r个token的K和V,用来和Q算attention(实际上做的是多头注意力,这里简单起见按单头注意力讲解),得到 O O O是 l × d l\times d l×d的,再接MLP GELU MLP,再过一个mean pooling,得到最终的embedding。
- 文章一边说train from scratch,又说用LoRA,就很奇怪。
- 另外呢,文章把mask去掉了,之前的GPT,每个token做注意力只能看到前面的token,但文章发现直接全都看得到在提取embedding方面效果更好:
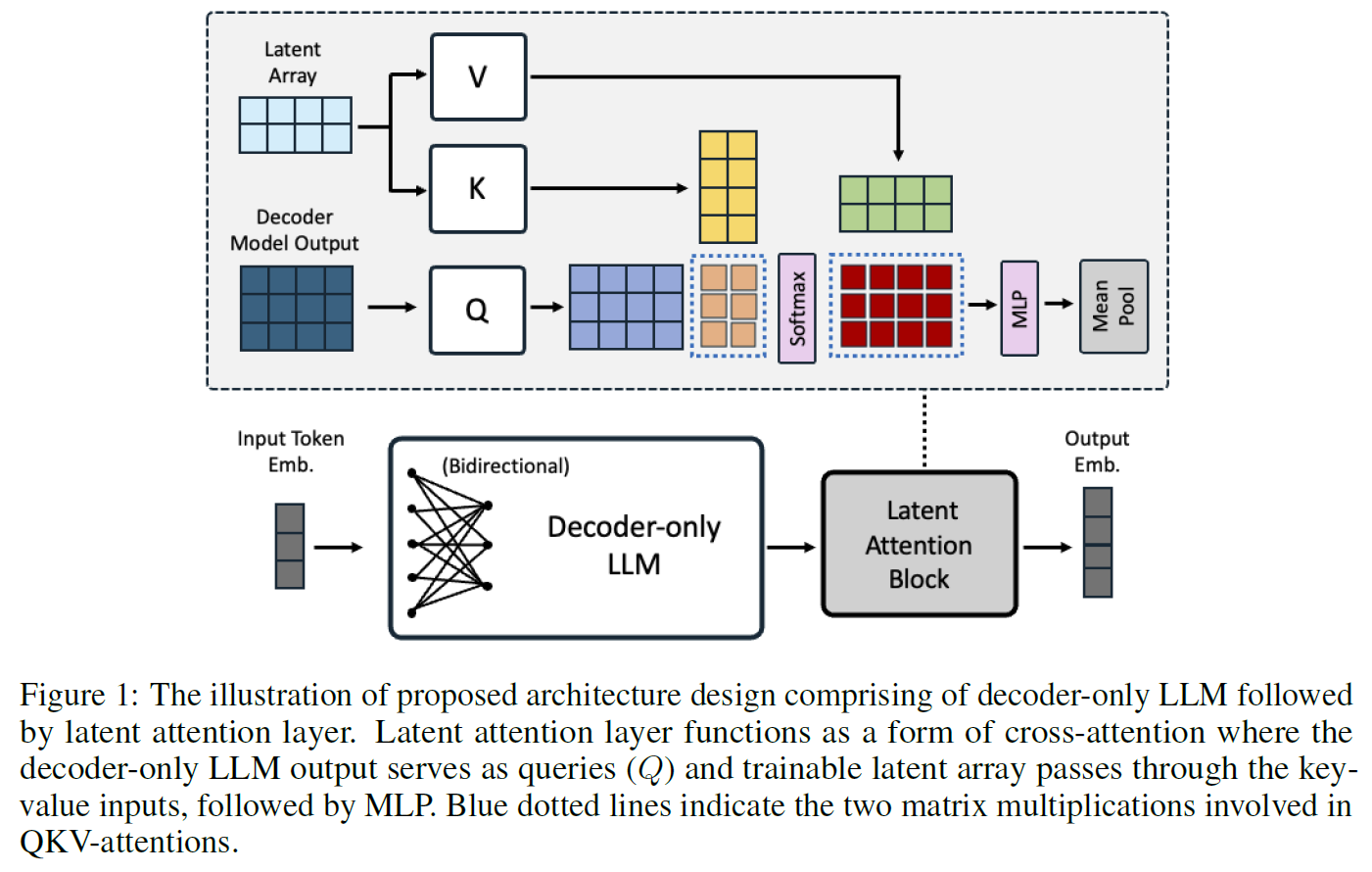
- 文章试验了bidirect attention/causal attention的对比,EOS Mean latent-attention self-attention的对比: