本篇介绍Netty的剩下三个组件Future&Promise、Handler&Pipeline、ByteBuf
**1、**Future&Promise
Future和Promise都是Netty实现异步的组件。
1.1、JDK中的future
在JDK中也有一个同名的Future,通常是配合多线程的Callable以及线程池的submit()方法使用,通过Future的get()方法在主线程处阻塞等待异步处理的结果:
@Slf4j
public class TestJDKFuture {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService service = Executors.newFixedThreadPool(2);
Future<Integer> future = service.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
log.debug("执行call方法");
Thread.sleep(1000);
return 30;
}
});
log.debug("main 线程运行");
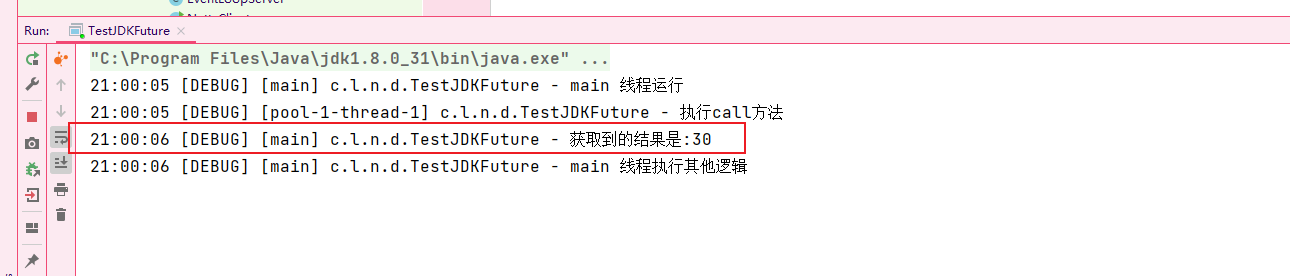
//会阻塞
log.debug("获取到的结果是:{}",future.get());
log.debug("main 线程执行其他逻辑");
}
}在get()方法拿到线程池中任务的返回结果后,主线程结束阻塞才执行后续的逻辑:
1.2、Netty中的future
Netty中的Future,相比较JDK中的Future做出了增强,增强点在:
-
getNow()方法立刻得到异步处理结果,还未产生结果时返回 null。
-
addLinstener()添加回调,异步接收结果,主线程不会阻塞。
@Slf4j
public class TestNettyFuture {
public static void main(String[] args) {
EventLoopGroup group = new NioEventLoopGroup();EventLoop eventLoop = group.next(); Future<Integer> future = eventLoop.submit(() -> { log.debug("执行call方法"); Thread.sleep(1000); return 30; }); //由执行call方法的线程异步获取结果,不会阻塞主线程 future.addListener(future1 -> log.debug("获取到的结果:{}", future1.getNow())); log.debug("main 线程执行"); }}

1.3、Netty中的promise
在上面的案例中,无论是JDK和Netty的Future,都是被动地接受多线程任务异步返回的结果。
而promise相当于一个容器,可以主动地设置多线程任务异步返回成功或失败的结果:
@Slf4j
public class TestPromise {
public static void main(String[] args) throws ExecutionException, InterruptedException {
EventLoop eventLoop = new NioEventLoopGroup().next();
DefaultPromise<Object> promise = new DefaultPromise<>(eventLoop);
new Thread(() -> {
try {
log.debug("开始计算");
// int i = 1 / 0;
//设置成功结果
promise.setSuccess(30);
} catch (Exception e) {
e.printStackTrace();
//设置失败结果
promise.setFailure(e);
}
}, "test").start();
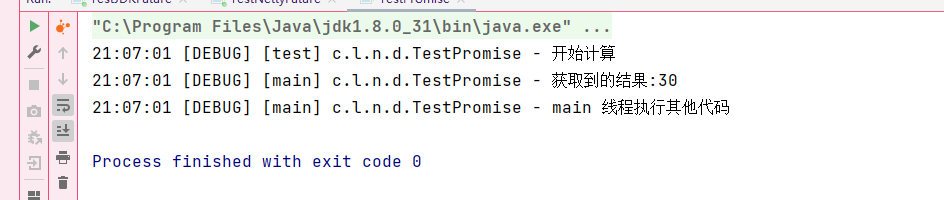
//会一直阻塞直到获取到最终结果
log.debug("获取到的结果:{}",promise.get());
log.debug("main 线程执行其他代码");
}
}没有发生异常,返回成功的结果:
将代码中的int i = 1 / 0 放开,发生异常,返回失败的结果:

2、Handler & Pipeline
Handler是Netty中的一个接口,用于处理特定类型的事件或数据,主要分为:
- ChannelInboundHandler:处理入站事件和数据
- ChannelOutboundHandler:处理出站数据和事件。
什么是入站和出站?
入站指的是数据从外部(例如客户端)进入到服务器(或其他网络组件)内部的过程。在Netty中,入站数据通常包括接收自网络的字节流、连接事件、解码后的消息等。(服务器接受客户端的消息数据,消息进入服务器)
出站指的是数据从内部(例如服务器)发送到外部(例如客户端)的过程。在Netty中,出站数据通常包括编码后的消息、写入网络的字节流等。(服务器向客户端发送数据消息,消息从服务器发出)
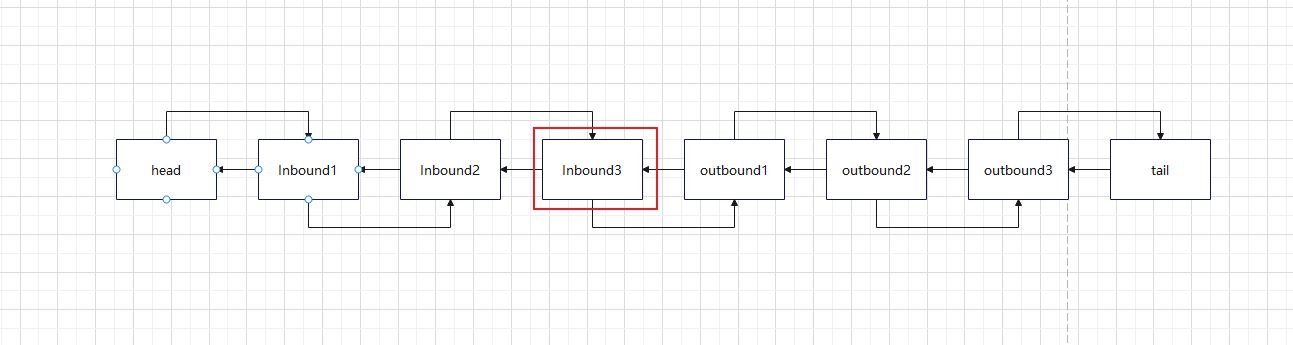
而Pipeline类似于流水线,由多个Handler组成,Handler可以理解成流水线上的各道工序。是Netty中的一个数据通道,负责管理和组织多个Handler的执行顺序。当一个Channel被创建时,Netty会自动创建一个与之关联的Pipeline。
相关案例:
@Slf4j
public class PipelineDemo1 {
public static void main(String[] args) {
new ServerBootstrap()
.group(new NioEventLoopGroup(),new NioEventLoopGroup(2))
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
/**
* head -> 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> tail
* @param ch
* @throws Exception
*/
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("1");
super.channelRead(ctx,msg);
}
});
ch.pipeline().addLast(new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("2");
super.channelRead(ctx,msg);
}
});
ch.pipeline().addLast(new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("3");
super.channelRead(ctx,msg);
//向byteBuff写入字节
ch.writeAndFlush(ctx.alloc().buffer().writeBytes("abc".getBytes(StandardCharsets.UTF_8)));
}
});
ch.pipeline().addLast(new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("4");
super.write(ctx, msg, promise);
}
});
ch.pipeline().addLast(new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("5");
super.write(ctx, msg, promise);
}
});
ch.pipeline().addLast(new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("6");
super.write(ctx, msg, promise);
}
});
}
})
.bind(8080);
}
}它的底层是一个双向链表:
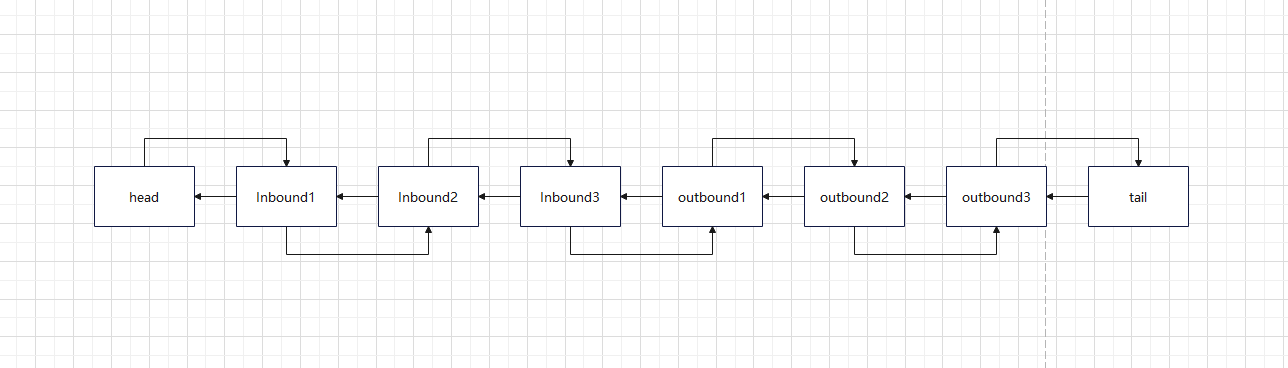
我们看一下它的执行顺序:
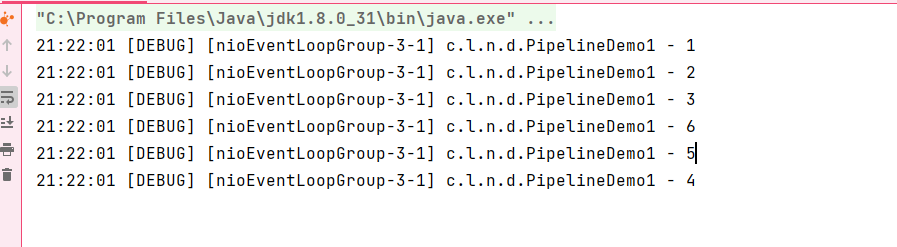
会发现InBound事件是从前往后执行的,而outBound事件是从后往前执行的。
关于outBound事件的触发时机,为什么需要手动调用这段代码?
ch.writeAndFlush(ctx.alloc().buffer().writeBytes("abc".getBytes(StandardCharsets.UTF_8)));原因在于,入站事件是指从客户端到服务器的数据流动,这些事件是由Netty内部自动触发的,例如接收到数据、连接建立等。出站事件是由应用程序主动触发的操作,这些事件通常是由应用程序主动触发的操作,例如写入数据到Channel、刷新数据到网络。
案例中的这段代码,是利用了NioSocketChannel的.writeAndFlush方法,而ChannelHandlerContext也具有.writeAndFlush方法,两者之间有什么区别?
将案例中的代码进行替换:
ctx.writeAndFlush(ctx.alloc().buffer().writeBytes("abc".getBytes(StandardCharsets.UTF_8)));结果是出站事件一个都没有触发,为什么?
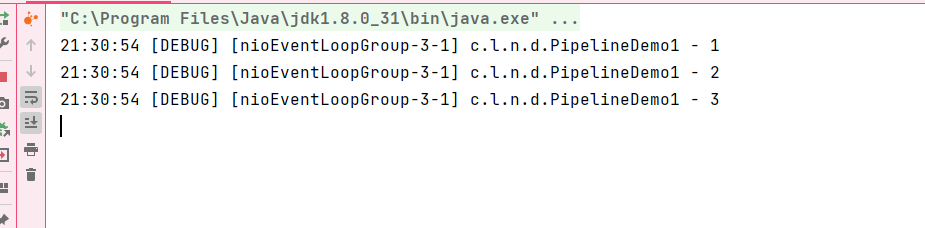
原因在于它们的触发方式和传播机制:
- ctx是上下文的实例,会从当前节点向前去找所有的outBound事件并且触发。
- ch是整个连接通道的实例,会从尾部节点向前去找所有的outBound事件并且触发。
当前节点是在inBound3位置,它的前面没有任何outBound事件:
如果此时有一个outBound事件在inBound3之前,使用ctx去进行写入并刷新也是可以触发的:
将事件4放在事件3的前面:
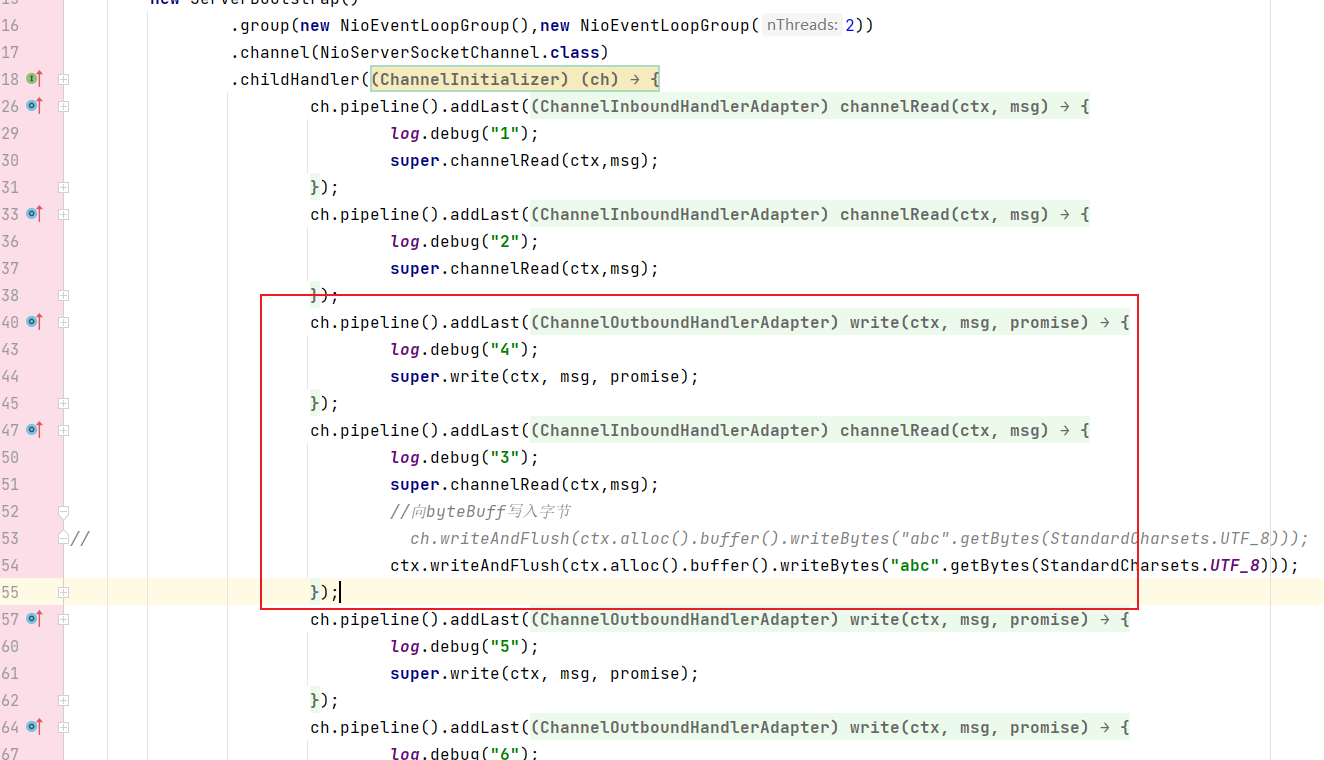
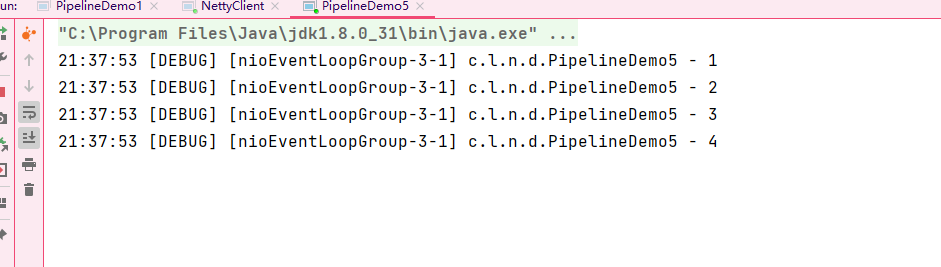
在执行完所有inBound事件后回头执行了outBound事件:
在上面的案例中提到了,ctx是上下文的实例。调用链最初的ctx,可以从客户端接受消息,并且逐层传递给后一个调用链上的handle进行处理。那么它是如何通知后一个调用链进行处理的?
关键在于super.channelRead(ctx,msg); 它的内部调用了上下文实例的.fireChannelRead方法。这个方法大致的含义是唤醒下一个handle并且将ctx进行传递。
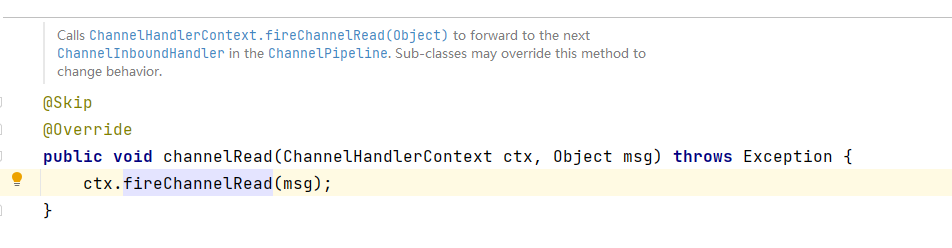
3、ByteBuf
ByteBuf可以理解成对于NIO中缓冲区ByteBuffer的增强,最大的区别在于:
- ByteBuffer在创建时指定了最大容量后不可以扩容,而ByteBuf具有扩容机制。
- ByteBuffer在写入/读取数据前需要进行读写模式切换,指针在读写模式下代表的含义也是不一样的,而ByteBuf内部维护了独立的读,写指针,互不干扰。
**3.1、**ByteBuf的初始容量
我们可以通过下面的api去创建一个ByteBuf:
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer();DEFAULT 是ByteBufAllocator接口中的一个成员变量:
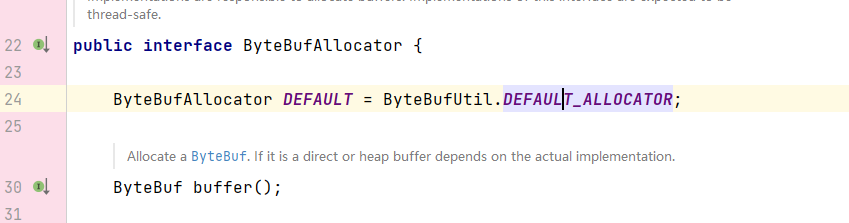
它的来源又是ByteBufUtil中的成员变量DEFAULT_ALLOCATOR
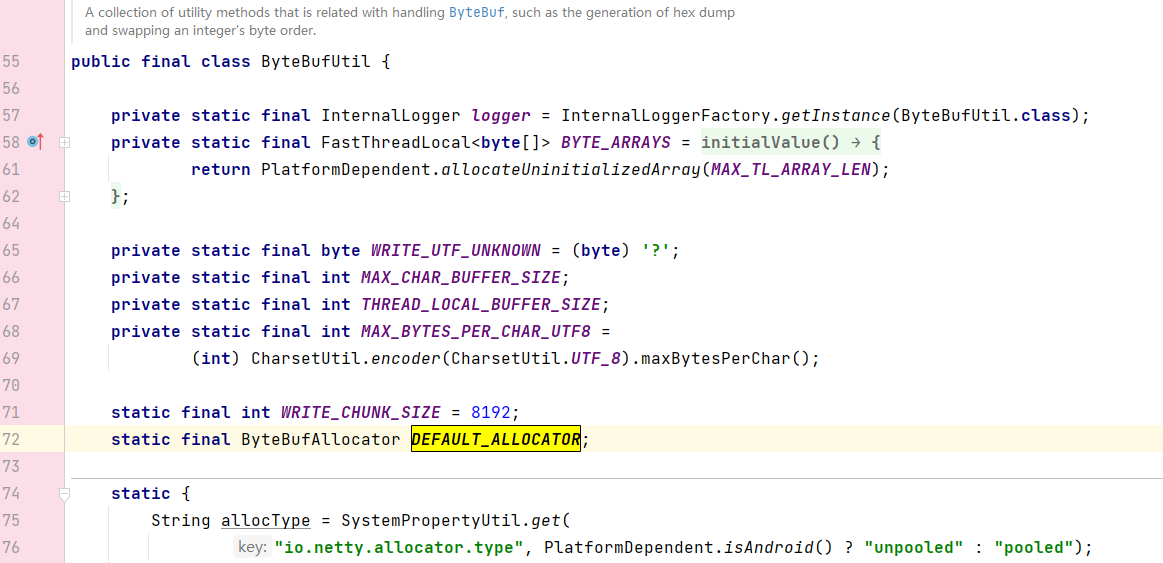
在静态代码块中,会在类加载时给DEFAULT_ALLOCATOR 赋值,其数据来源会根据是否开启池化进行分派:(这里暂且知道有池化这回事,后续会进行说明)
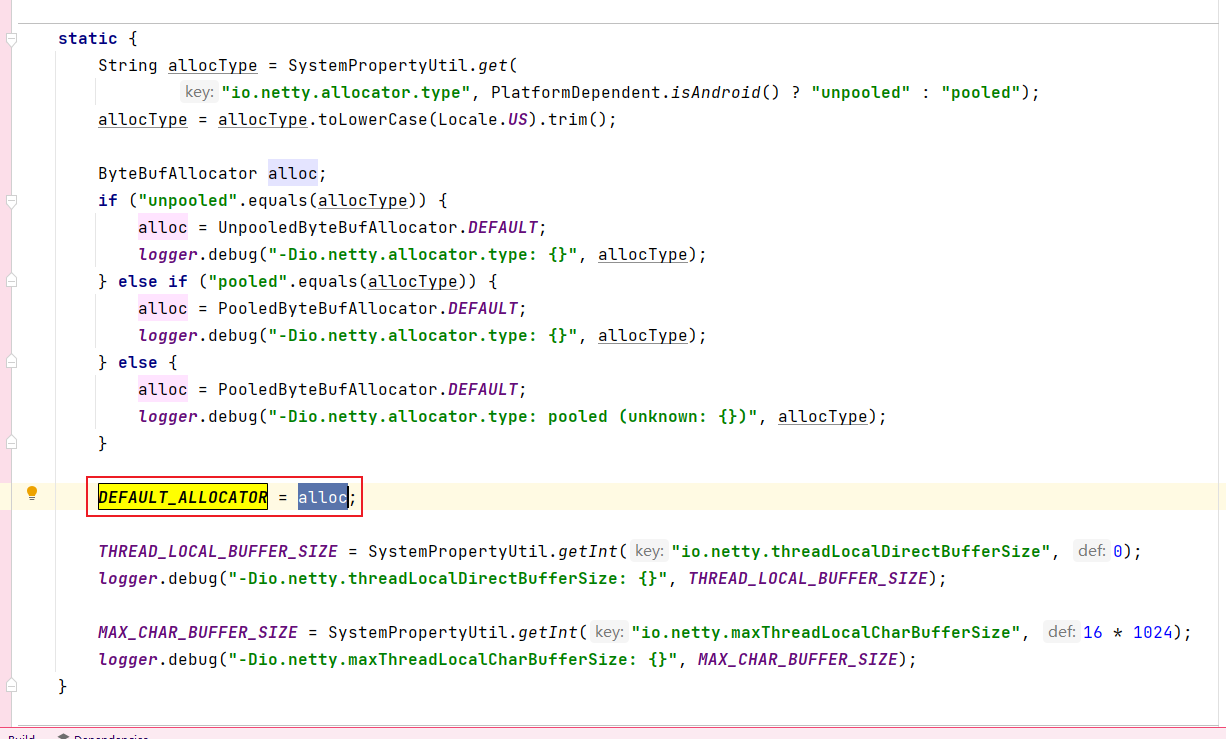
假设目前是开启了池化,最终DEFAULT_ALLOCATOR 的值是新创建的PooledByteBufAllocator实例。
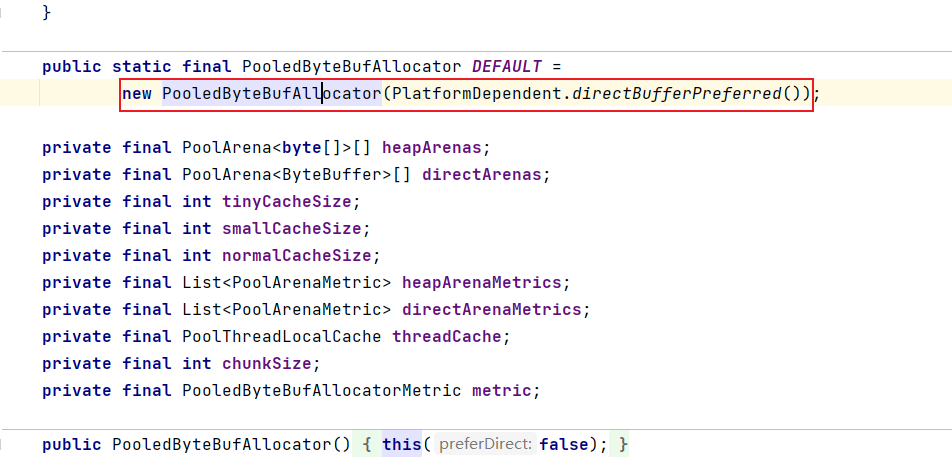
PooledByteBufAllocator 的类关系图:
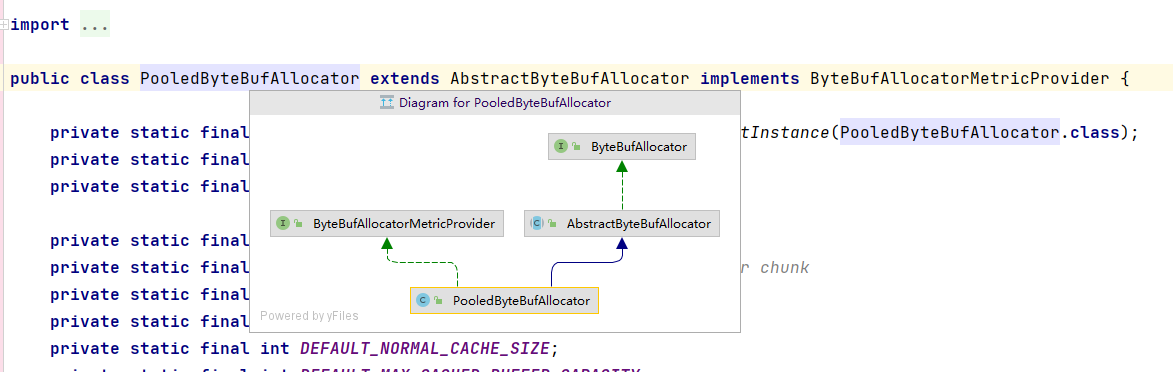
最后调用的buffer();方法还是PooledByteBufAllocator 的父类AbstractByteBufAllocator中的
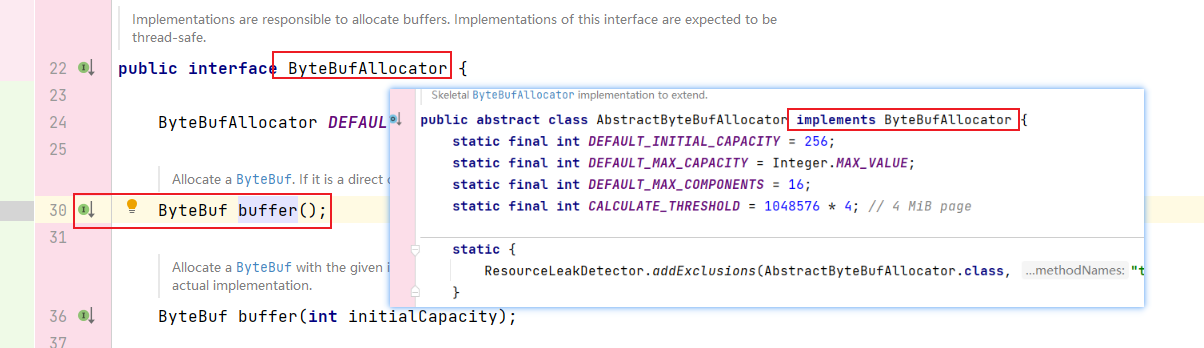
有三个重载的方法,它们的共同点都是通过directByDefault 的布尔值判断返回何种类型的Buffer(直接内存或堆内存)
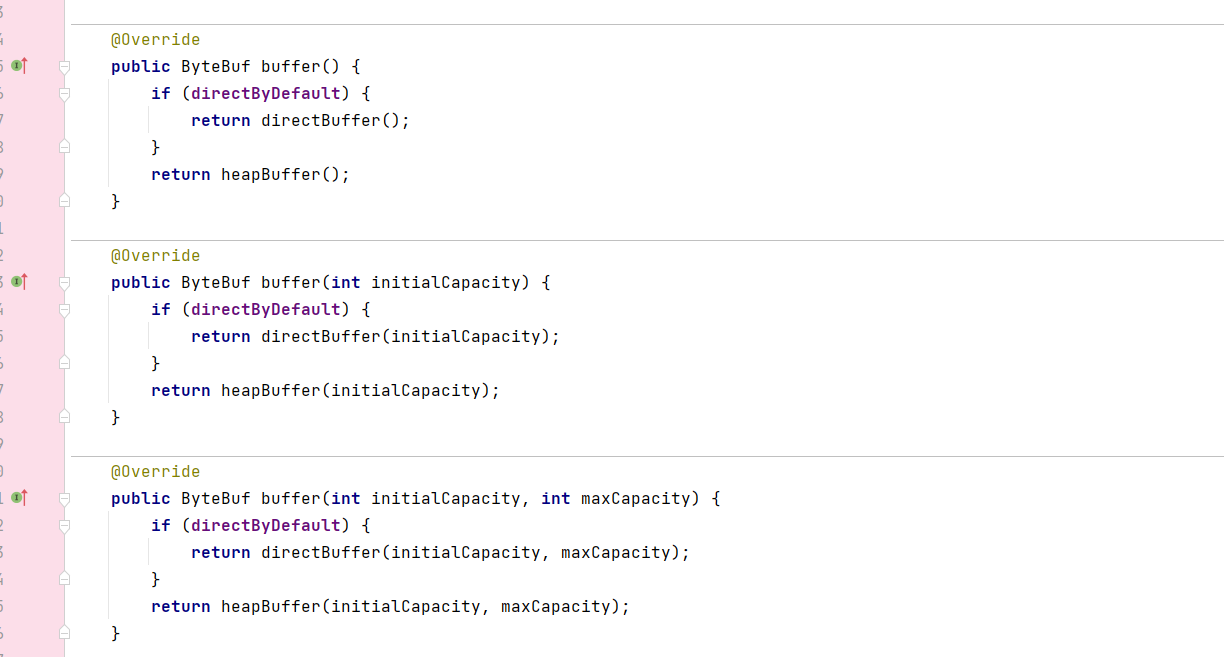
如果我们没有指定大小,走的是第一个无参的方法,初始容量是256,最大容量是integer的最大值:
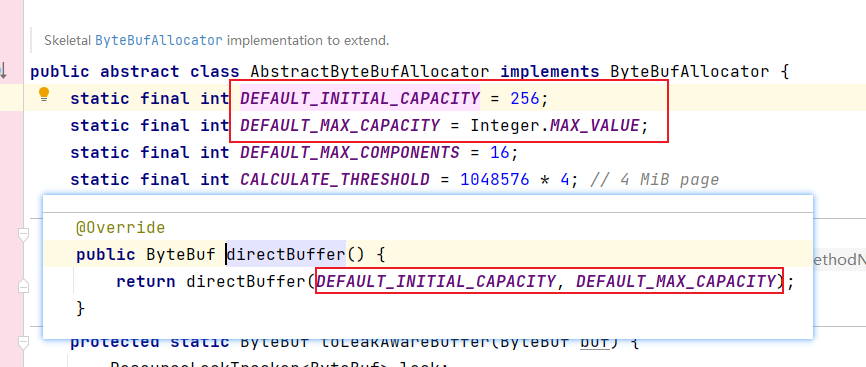
**3.2、**ByteBuf的扩容机制
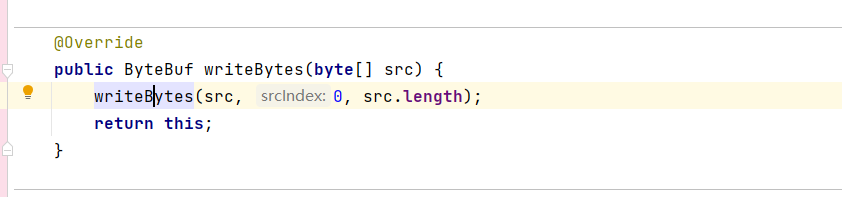
ByteBuf的扩容,主要体现在buffer.writeBytes()方法上,在上面的案例中,它的实际类型是
class io.netty.buffer.PooledUnsafeDirectByteBuf
又调用了另一个writeBytes方法,传递了参数数组以及参数数组的长度。
再次进入会发现内部调用了三个方法:
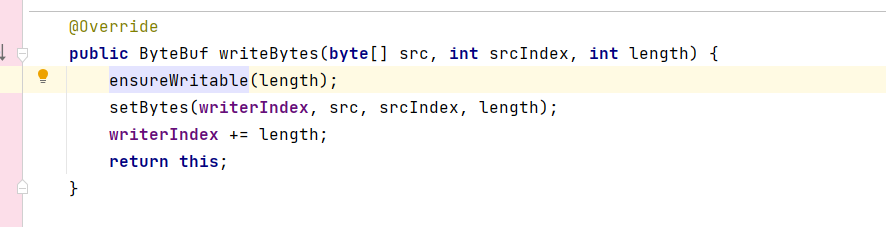
研究扩容机制,我们重点关注ensureWritable方法
3.2.1、ensureWritable(length)
ensureWritable(length)方法的内部又调用了两个方法(方法的参数minWritableBytes
是将要写入的byte数组的长度):
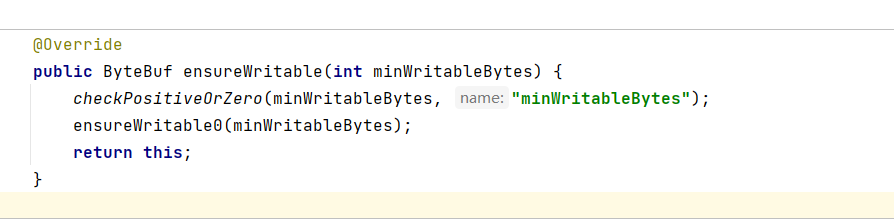
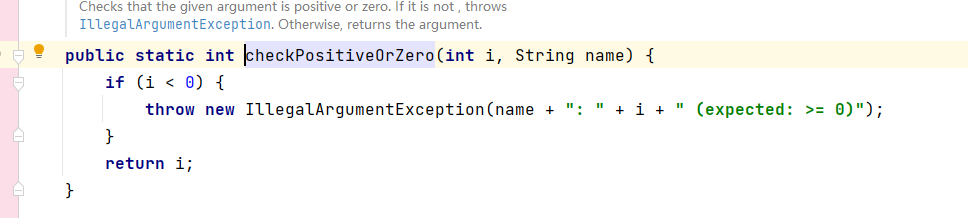
- checkPositiveOrZero(minWritableBytes, "minWritableBytes"):这个方法的目的是为了检查将要写入的byte数组长度的合法性:
- ensureWritable0(int minWritableBytes):该方法是扩容逻辑的体现:

这段代码的含义是,判断当前byte数组的长度如果小于或等于可写入大小,则无需扩容直接返回:
if (minWritableBytes <= writableBytes()) {
return;
}writableBytes() 方法会用当前bytebuf的容量-写指针的索引得到可写入大小
假设没有设置ByteBuf的容量,那么它的默认值此时是256,还没有进行写入,写指针的索引就在0位置。writableBytes()方法返回的是256 - 0 = 256。并且假设需要写入的byte数组的大小是300,那么300 > 256**(300比当前的容量大,但是小于最大容量)**,就不满足该if代码块,会继续向下执行,如果没有进入该if块就说明需要扩容了。
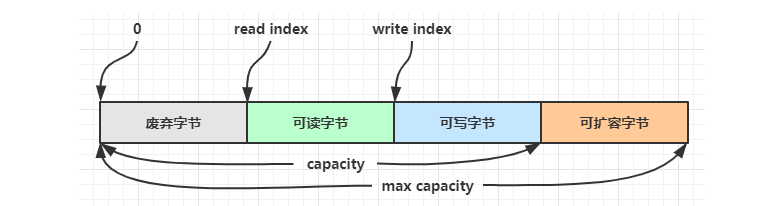
在这里有必要顺带着说明一下ByteBuf的数据结构:
- Capacity(容量):是缓冲区中可以存储的最大字节数。
- Reader Index(读索引):表示当前读操作的位置。
- Writer Index(写索引):表示当前写操作的位置。
- Max Capacity(最大容量):integer的最大值或自己设置。
可扩容字节 = 最大容量 - 容量。
然后会将当前写指针的位置(0)赋值给一个局部变量。
final int writerIndex = writerIndex();这段代码的含义是检查边界**(默认情况下都是要检查的,都会进入该if条件块)**:
如果当前需要写入的byte数组的大小比最大容量还要大,就会抛出异常。
if (checkBounds) {
if (minWritableBytes > maxCapacity - writerIndex) {
throw new IndexOutOfBoundsException(String.format(
"writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s",
writerIndex, minWritableBytes, maxCapacity, this));
}
}这段代码是将写指针的索引+byte数组的长度赋值给一个新的变量**(此时的值是300)**
int minNewCapacity = writerIndex + minWritableBytes;然后会在这段代码中执行扩容的逻辑,调用calculateNewCapacity方法,传入byte数组的长度和最大容量:
int newCapacity = alloc().calculateNewCapacity(minNewCapacity, maxCapacity);选择第一个实现:

同样去进行条件检查:
checkPositiveOrZero(minNewCapacity, "minNewCapacity");
if (minNewCapacity > maxCapacity) {
throw new IllegalArgumentException(String.format(
"minNewCapacity: %d (expected: not greater than maxCapacity(%d)",
minNewCapacity, maxCapacity));
}然后会将一块4MiB大小的区域赋值给变量threshold,如果当前数组容量和它相等,就直接返回。
final int threshold = CALCULATE_THRESHOLD; // 4 MiB page
if (minNewCapacity == threshold) {
return threshold;
}否则进入该if块:
-
首先用当前数组容量(300)/ threshold * threshold (当前数组容量/threshold的整数倍)赋值给newCapacity。
-
如果newCapacity + threshold > 最大容量,就将newCapacity设置成最大容量。
-
否则newCapacity加上一个threshold。
if (minNewCapacity > threshold) { int newCapacity = minNewCapacity / threshold * threshold; if (newCapacity > maxCapacity - threshold) { newCapacity = maxCapacity; } else { newCapacity += threshold; } return newCapacity; }
没有进入上面的if块就说明当前数组的容量要小于threshold,就会执行下面的while循环:
-
从64开始翻倍,直到newCapacity大于等于当前数组的容量
// Not over threshold. Double up to 4 MiB, starting from 64. int newCapacity = 64; while (newCapacity < minNewCapacity) { newCapacity <<= 1; }
最后会返回扩容后的数组容量和最大容量的小值。
return Math.min(newCapacity, maxCapacity);总结:对于小的容量需求,使用指数增长方式;对于大的容量需求,采用线性增长方式。
案例中的300容量,最终会走while (newCapacity < minNewCapacity)的逻辑,也就是最终扩容的结果是从最初的256->512。
3.3、ByteBuf堆内存和直接内存
ByteBuf和ByteBuffer一样,都支持创建基于堆的ByteBuf和基于直接内存的ByteBuf 。
- 基于堆的ByteBuf受JVM控制,由JVM在合适的时机进行垃圾回收。正是因为此,使用堆内存会增加垃圾回收器的负担,尤其是在大量分配和释放内存的场景中,可能会导致 GC 开销较高。
- 基于直接内存的ByteBuf使用 JVM 堆外内存,需要手动在合适的时机进行回收,Netty 使用引用计数(Reference Counting)机制来管理直接内存的生命周期。
学过JVM的都知道,垃圾回收有两种机制,可达性分析和引用计数。在JVM中实际上默认也是使用可达性分析 的,这样做的目的是为了解决循环引用的问题。为什么在Netty中使用了引用计数 ?
Netty 选择引用计数的原因
- 引用计数法在回收垃圾时是实时的,当引用计数归零时,会立刻释放内存,无需等待下一次垃圾回收的触发。
- Netty中的内存结构,通常不涉及复杂的对象图和循环引用,引用计数的缺点在这种情况下影响较小。
- Netty 结合了内存池化机制,进一步减少了频繁分配和释放内存的开销。
那什么是内存池化机制,基于直接内存的ByteBuf又为什么通常配合内存池化机制 一起使用?
池化是一种基于复用的思想,类似于线程池,数据库连接池,我们通常会使用线程池去管理线程,而不是手动地去创建线程,有新任务被分配时,线程池会使用空余的线程去进行处理,处理完毕后则归还线程,避免大量地去创建线程。数据库连接池也是一样的道理。
如果ByteBuf没有利用内存池化机制 ,则每次都要创建新的实例,对于内存的影响较大。特别是基于直接内存的ByteBuf,**直接内存创建和销毁的代价昂贵 ,**频繁地创建销毁很影响效率。并且在高并发时,池化功能更节约内存,减少内存溢出的可能。
在上文中提到,如果使用直接内存的ByteBuf,需要手动地去释放内存。那么释放内存的时机是?
我们知道,pipeline是一种链式调用的结构,ByteBuf可能在多个handle之间传递。那么我们就应该在最后一个ByteBuf被使用,并且不再向下传递的handle中进行release操作。具体也可细分为以下几种情况:
-
对原始 ByteBuf 不做处理,调用 ctx.fireChannelRead(msg) 向后传递,这时无须 release
-
将原始 ByteBuf 转换为其它类型的 Java 对象,这时 ByteBuf 就没用了,必须 release
-
如果不调用 ctx.fireChannelRead(msg) 向后传递,那么也必须 release
-
注意各种异常,如果 ByteBuf 没有成功传递到下一个 ChannelHandler,必须 release
-
假设消息一直向后传,那么 TailContext 会负责释放未处理消息(原始的 ByteBuf)
-
出站消息最终都会转为 ByteBuf 输出,一直向前传,由 HeadContext flush 后 release。
这是尾节点的类,实现了入站处理器的接口:
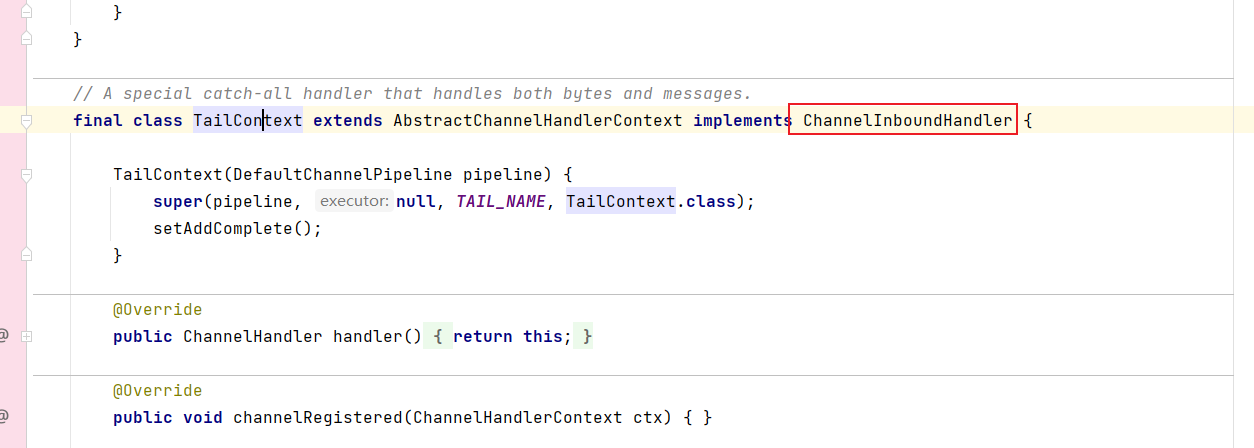
其中的onUnhandledInboundMessage方法就是release的逻辑:
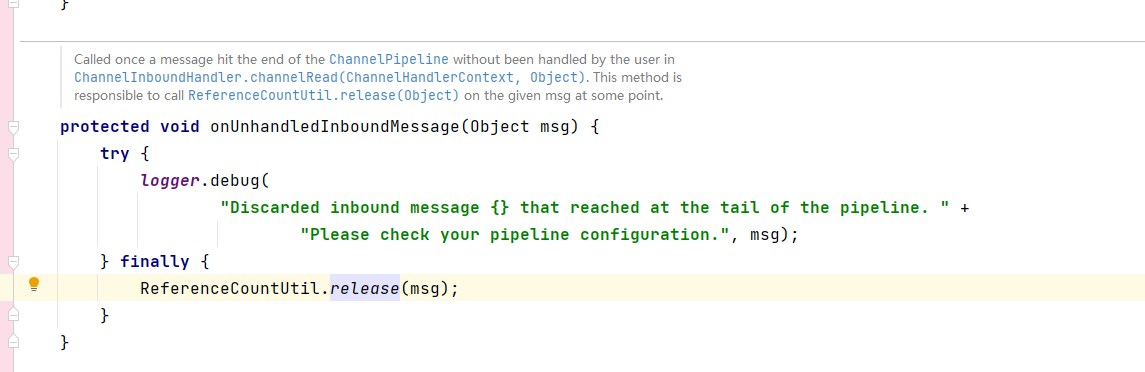
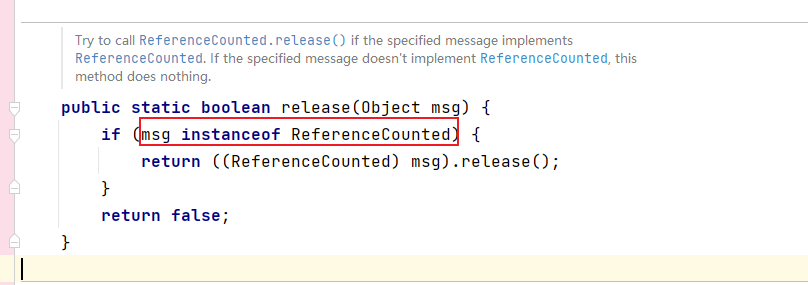
检查msg的类型是否属于ReferenceCounted及其子类。(ByteBuf实现了ReferenceCounted接口)
3.4、Slice&CompositeByteBuf
Slice和CompositeByteBuf也是ByteBuf中的两个方法,也是零拷贝的体现,下面通过案例的形式简单的介绍一下:
3.4.1、Slice
通过ByteBuf的Slice方法,将一个完整的byte数组切分成为了两个不同的部分,但是内存和完整的byte数组是同一个。
正因为如此,如果提前将完整数组手动release,则切片无法正常工作。
/**
* 切片
*/
public class SliceDemo1 {
public static void main(String[] args) {
ByteBuf origin = ByteBufAllocator.DEFAULT.buffer(10);
origin.writeBytes(new byte[]{1, 2, 3, 4});
MyByteBufUtil.log(origin);
ByteBuf b1 = origin.slice(0, 2);
ByteBuf b2 = origin.slice(2, 2);
MyByteBufUtil.log(b1);
MyByteBufUtil.log(b2);
//slice 并没有切分内存
System.out.println("**********************");
b1.setByte(0,'a');
MyByteBufUtil.log(origin);
MyByteBufUtil.log(b1);
}
}可以看到对任何一个切片内容的修改,都会体现在完整的Byte上:

3.4.2、CompositeByteBuf
CompositeByteBuf是Slice的反向操作,将多个ByteBuf组合在一起,同样也不会开辟一份新的内存。
public class CompositDemo {
public static void main(String[] args) {
ByteBuf b1 = ByteBufAllocator.DEFAULT.buffer();
b1.writeBytes(new byte[]{'1','2'});
ByteBuf b2 = ByteBufAllocator.DEFAULT.buffer();
b2.writeBytes(new byte[]{'3','4'});
//将多个ByteBuf组合在一起,同样也不会开辟一份新的内存
//内部维护了一个 Component 数组,每个 Component 管理一个 ByteBuf
//也就是说目前只存在b1和b2两块内存
CompositeByteBuf compositeBuffer = ByteBufAllocator.DEFAULT.compositeBuffer();
compositeBuffer.addComponents(true,b1,b2);
MyByteBufUtil.log(compositeBuffer);
}
}4、双向通信综合案例
最后我们通过一个客户端,服务器互相发送消息的综合案例来总结一下上面的知识点:
服务器端,我们可以重点回顾一下这几个问题:
-
ch.writeAndFlush 和 ctx.writeAndFlush 有什么区别?
-
ChannelOutboundHandlerAdapter出站事件的触发时机以及顺序?
-
ByteBuf手动release的时机?
public class TestServer2 {
public static void main(String[] args) {
new ServerBootstrap()
.group(new NioEventLoopGroup(),new NioEventLoopGroup())
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new StringDecoder(Charset.defaultCharset()));
pipeline.addLast(new StringEncoder(Charset.defaultCharset()));
pipeline.addLast(new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("从客户端读取到的消息:{}",msg);
//调用ch,触发出站事件 无视顺序
ByteBuf buffer = ctx.alloc().buffer();
ch.writeAndFlush(buffer.writeBytes("abc".getBytes(StandardCharsets.UTF_8)))
.addListener(ChannelFutureListener.CLOSE_ON_FAILURE);
//byteBuf没有继续向下传递,所以需要release?
buffer.release();
}
});
pipeline.addLast(new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("向客户端发送消息");
super.write(ctx, msg, promise);
log.debug("向客户端发送消息完成");
}
});
}
})
.bind(8080);
}
}
客户端,我们可以重点回顾一下这几个问题:
-
建立连接是由主线程完成的吗?
-
建立连接后为什么要调用.sync方法,以及有无其他方式达成同样的效果?
-
关闭连接是否由主线程完成?如何才能正确地处理关闭连接后的逻辑?
@Slf4j
public class TestClient1 {
public static void main(String[] args) throws InterruptedException {
NioEventLoopGroup eventLoopGroup = new NioEventLoopGroup();
Channel channel = new Bootstrap()
.group(eventLoopGroup)
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
//字符输出编码
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new StringDecoder(Charset.defaultCharset())); // 添加解码器
pipeline.addLast(new StringEncoder(Charset.defaultCharset()));
pipeline.addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("从服务器端读取到的消息:{}", msg);
super.channelRead(ctx, msg);
}
});
}
})
.connect(new InetSocketAddress("localhost", 8080))
.sync()//阻塞方法 连接建立成功后才会执行
.channel();//新开启一个线程向服务端写入 new Thread(()->{ Scanner sc = new Scanner(System.in); while (true){ String str = sc.nextLine(); if (str.equals("q")){ //由nioEventLoopGroup线程异步关闭连接 channel.close(); break; } channel.writeAndFlush(str); } },"input").start(); //主线程调用监听器发布通知,由nioEventLoopGroup在channel.close()后 处理连接关闭后释放资源 channel.closeFuture().addListener(future -> eventLoopGroup.shutdownGracefully()); }}