反压
Flink反压是一个在实时计算应用中常见的问题,特别是在流式计算场景中。以下是对Flink反压的详细解释:
一、反压释义
反压(backpressure)意味着数据管道中某个节点成为瓶颈,其处理速率跟不上上游发送数据的速率,从而需要对上游进行限速。在Flink等实时计算框架中,反压通常是从某个节点传导至数据源,并降低数据源(如Kafka consumer)的摄入速率。
二、反压原因
- 数据倾斜:数据分布不均,导致个别task处理数据过多。
- 算子性能问题:可能某个节点逻辑很复杂,如sink节点很慢或lookup join热查询慢等。
- 流量陡增:如大促时流量激增,或者使用了数据炸开的函数。
三、反压影响
- 任务处理性能出现瓶颈:例如,在消费Kafka时,可能会出现消费Kafka Lag。
- Checkpoint时间长或失败:因为某些反压会导致barrier需要花很长时间才能对齐,从而影响任务的稳定性。
- State状态变大:由于数据处理速度不匹配,可能导致系统内部状态堆积。
- Kafka数据积压:当Flink作业无法及时处理Kafka中的数据时,会导致数据在Kafka中积压。
- OOM(内存溢出):严重的反压可能导致系统资源耗尽,进而引发内存溢出等问题。
四、反压机制实现方式
在Flink中,反压机制可以通过以下两种方式实现:
- 阻塞式反压:当下游任务无法及时处理上游任务生成的数据时,上游任务会被阻塞,直到下游任务处理完毕。这种方式可以保证数据不丢失,但会造成延迟增加。
- 异步非阻塞式反压:此方式的具体实现和细节可能因Flink版本和配置而异,但通常旨在通过异步处理和非阻塞操作来减轻反压的影响。
五、解决思路
- 优化数据分布:通过调整数据分区策略或重新设计数据模型来减少数据倾斜。
- 提升算子性能:针对性能瓶颈的算子进行优化,如简化逻辑、增加资源等。
- 限流与缓冲:在数据源端或关键节点前设置限流策略和缓冲区,以平滑处理流量陡增的情况。
- 监控与告警:建立完善的监控和告警机制,及时发现并处理反压问题。
综上所述,Flink反压是一个需要关注的问题,它可能影响到实时计算应用的性能和稳定性。通过理解反压的原理和影响,并采取相应的解决措施,可以有效地提升Flink作业的处理能力和稳定性。
监控
Flink Web
Flink Web 界面提供了一个选项卡来监控正在运行 jobs 的反压行为。
Task 性能指标
task(SubTask)的每个并行实例都可以用三个一组的指标评价:
- backPressuredTimeMsPerSecond,subtask 被反压的时间
- dleTimeMsPerSecond,subtask 等待某类处理的时间
- busyTimeMsPerSecond,subtask 实际工作时间 在任何时间点,这三个指标相加都约等于1000ms。
这些指标每两秒更新一次,上报的值表示 subtask 在最近两秒被反压(或闲或忙)的平均时长。 当工作负荷是变化的时需要尤其引起注意。如,一个以恒定50%负载工作的 subtask 和另一个每秒钟在满负载和闲置切换的 subtask 的busyTimeMsPerSecond值相同,都是500ms。
在内部,反压根据输出 buffers 的可用性来进行判断的。 如果一个 task 没有可用的输出 buffers,那么这个 task 就被认定是在被反压。 相反,如果有可用的输入,则可认定为闲置,
WebUI
WebUI 集合了所有 subTasks 的反压和繁忙指标的最大值,并在 JobGraph 中将集合的值进行显示。除了显示原始的数值,tasks 也用颜色进行了标记,使检查更加容易。
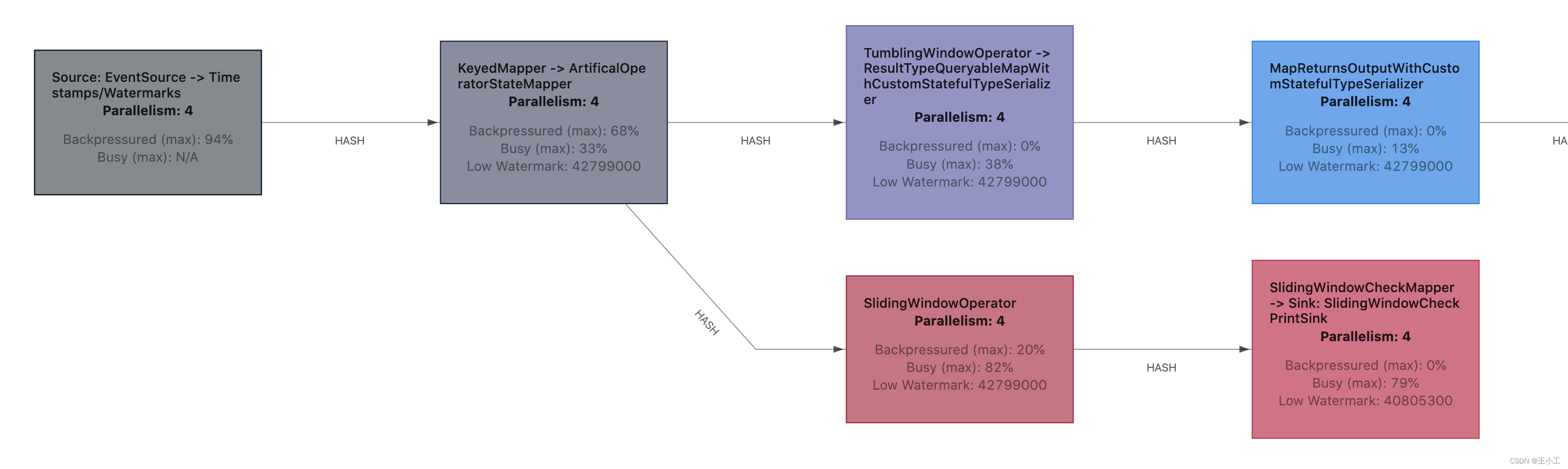
闲置的 tasks 为蓝色,完全被反压的 tasks 为黑色,完全繁忙的 tasks 被标记为红色。 中间的所有值都表示为这三种颜色之间的过渡色。
反压状态
在 Job Overview 旁的 Back Pressure 选项卡中,可以找到更多细节指标。
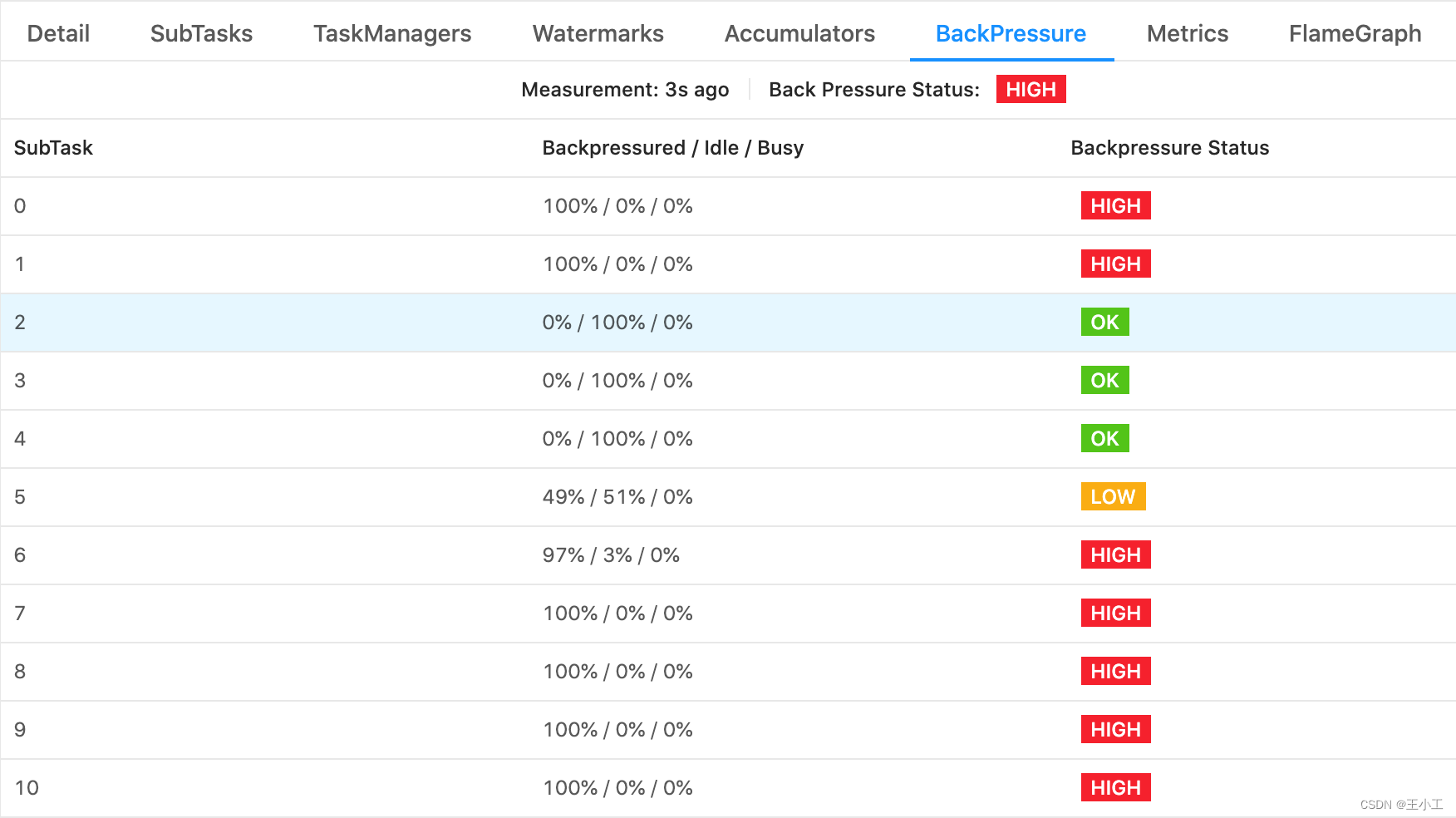
如果看到 subtasks 的状态为 OK 表示没有反压。HIGH 表示这个 subtask 被反压。状态用如下定义:
- OK: 0% <= 反压比例 <= 10%
- LOW: 10% < 反压比例 <= 50%
- HIGH: 50% < 反压比例 <= 100%
Prometheus监控
在Flink中使用Prometheus进行反压监测通常涉及配置Flink的metrics系统以及Prometheus的配置。以下是配置Flink以使用Prometheus进行反压的基本步骤:
配置
- 在Flink配置文件中启用Prometheus metrics(通常是flink-conf.yaml):
yml
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: <prometheus-pushgateway-host>
metrics.reporter.promgateway.port: <prometheus-pushgateway-port>
metrics.reporter.promgateway.jobName: <job-name>
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false- 确保Prometheus配置了PushGateway,并且Prometheus能够从Flink TaskManagers推送指标。
- 下载并解压 Prometheus Pushgateway:
bash
wget https://github.com/prometheus/pushgateway/releases/download/v1.4.1/pushgateway-1.4.1.linux-amd64.tar.gz
tar xvzf pushgateway-1.4.1.linux-amd64.tar.gz
cd pushgateway-1.4.1.linux-amd64- 创建一个系统服务文件 /etc/systemd/system/pushgateway.service:
lni
[Unit]
Description=Pushgateway
After=network.target
[Service]
User=nobody
Group=nobody
Type=simple
ExecStart=/path/to/pushgateway
[Install]
WantedBy=multi-user.target- 启动并使 Pushgateway 服务随系统启动:
bash
sudo systemctl daemon-reload
sudo systemctl start pushgateway
sudo systemctl enable pushgateway- 配置 Prometheus 来从 Pushgateway 拉取数据。在 Prometheus 配置文件 (prometheus.yml) 中添加以下内容:
yml
scrape_configs:
- job_name: 'pushgateway'
static_configs:
- targets: ['localhost:9091']- 配置Prometheus PushGateway,通常在Prometheus配置文件中(prometheus.yml):
yml
scrape_configs:
- job_name: 'flink-metrics'
honor_labels: true
static_configs:
- targets: ['<pushgateway-host>:<pushgateway-port>']- 重启Flink集群和Prometheus以应用配置更改。
配置告警规则,推送alertmanager进行告警通知推送
通过Grafana显示Flink运行状态
方案
增加资源
- 增加CPU资源: 调整TaskManager的CPU配置和并行化任务
- 增加内存资源:调整TaskManager的内存配置和优化数据结构
- 增加其他资源:例如:使用SSD或RDMA等网络加速设备、增加GPU资源
注意:
- 避免过度资源分配:虽然增加资源可以缓解反压问题,但过度分配资源可能导致资源浪费和成本增加。因此,在增加资源之前,需要仔细评估任务的实际需求和资源使用情况。
- 结合其他优化措施:除了增加资源外,还可以结合其他优化措施来进一步缓解反压问题。例如,优化处理逻辑、减少计算复杂度、使用更高效的数据结构等。
数据倾斜
- 数据倾斜定义
数据倾斜是指数据的分布严重不均,造成一部分数据很多,一部分数据很少的局面。在Flink中,这通常表现为部分节点处理的数据量远大于其他节点。 - 数据倾斜的原因
- 业务原因:如订单数据中某些城市的订单量远大于其他城市。
- 技术原因:大量使用KeyBy、GroupBy等操作,错误地使用了分组Key,人为产生数据热点。
- 解决方案
- 业务层面 :
- 尽量避免热点key的设计,例如将热点城市分成不同的区域,并进行单独处理。
- 在数据预处理阶段对数据进行均衡处理,如使用随机前缀打散key。
- 技术层面 :
- 调整方案打散原来的key,避免直接聚合。
- 使用Flink提供的二次聚合等策略,先对打散后的数据进行聚合,再还原为真正的key进行二次聚合。
- 优化join操作,将条目少的表/子查询放在Join的左边,减少内存溢出的几率。
- 使用MapJoin处理小表关联大表的情况,避免数据倾斜。
- 配置层面 :
- 设置合理的mapreduce的task数,能有效提升性能。
- 在数据量较大的情况下,慎用count(distinct)等操作。
- 对小文件进行合并,减少文件数据源带来的倾斜问题。## 算子性能
算子性能
原因:
- 下游算子性能差:下游算子sub-task的处理性能低下,无法及时消费上游算子产生的数据。
- 外部接口访问:算子需要频繁访问外部接口,如数据库或API,这些操作耗时长,导致数据处理速率下降。
- 代码问题:用户代码执行效率低下,例如存在频繁的阻塞操作或性能瓶颈。
判断:
- 通过Flink Web UI的BackPressure模块,观察算子的颜色和数值来判断是否出现反压。红色- 表示当前算子繁忙,有反压;绿色表示当前算子不繁忙,没有反压。
- 通过对比不同SubTask处理的数据量,判断是否存在数据倾斜导致的个别SubTask性能下降。
解决
- 限制数据源消费速度:在数据源处设置限流措施,确保数据匀速消费,避免速度不均导致的反压。
- 关闭Checkpoint:在数据回溯期间关闭Checkpoint,以减少barrier对齐对性能的影响。完成数据回溯后再重新开启Checkpoint。
- 优化代码:检查并优化用户代码,减少阻塞操作和性能瓶颈,提高算子处理效率。
- 增加计算资源:根据实际需要增加计算资源,如增加计算节点、CPU和内存等,提高系统的整体处理能力。
- 动态调整并行度:根据系统负载情况动态调整任务的并行度,将任务分配到更多的计算节点上,以提高处理能力。
- 重分区:通过重分区将数据均匀地分布到不同的分区中,减少数据倾斜并提高并行度。
- 使用缓冲区:设置缓冲区来暂存数据,避免在下游算子处理速度不足时导致数据丢失或延迟增加。
调大并行度
**并行度:**并行度(Parallelism)是指Flink任务中每个算子的并行实例数。增加并行度意味着更多的任务实例将同时处理数据,从而提高了系统的整体处理能力。
调大并行度
- 分析原因:
- 在调大并行度之前,首先需要分析反压的具体原因。常见原因包括资源不足、数据倾斜、算子性能问题等。
- 使用Flink的监控工具(如Web UI、Metrics等)来观察任务的资源使用情况和性能瓶颈。
- 确定合理的并行度:
- 可以通过压测来确定合理的并行度。例如,先获取高峰期的QPS(每秒处理的数据量),然后测试不同并行度下系统的处理能力,找到能够处理该QPS而不发生反压的并行度。
- 也可以考虑使用经验法则,如根据数据源(如Kafka)的分区数来设置并行度。
- 设置并行度:
- 在Flink程序中,可以通过多种方式来设置并行度。
- 在代码中:通过StreamExecutionEnvironment的setParallelism()方法来设置全局并行度。
- 在算子层次:对于单个算子,可以调用其setParallelism()方法来设置该算子的并行度。
- 在配置文件或提交任务时:通过配置文件或提交任务时的参数来设置并行度。
- 需要注意的是,当使用savepoints时,应该考虑设置最大并行度。这可以确保在从savepoint恢复任务时,能够改变特定算子或整个程序的并行度,而不会超过设定的上限。
- 监控与调整:
- 在调整并行度后,需要持续监控任务的运行情况,观察是否解决了反压问题,以及是否出现了新的问题(如资源利用率不足、资源浪费等)。
- 根据监控结果,可以进一步调整并行度或其他相关配置,以达到最佳的性能和稳定性。
注意:
- 避免过度并行化:虽然增加并行度可以提高系统的处理能力,但过度并行化可能导致资源利用率下降、管理复杂性增加等问题。因此,在调整并行度时需要权衡利弊。
- 考虑数据倾斜:数据倾斜可能导致部分节点处理的数据量远大于其他节点,从而引发反压。在调整并行度时,需要考虑数据倾斜的情况,并采取相应的措施来平衡数据分布。
- 优化其他配置:除了调整并行度外,还可以考虑优化其他相关配置,如内存大小、缓存策略等,以进一步提升系统的性能和稳定性。
限流与缓冲
限流机制
Flink通过水位线(Watermark)机制来实现限流。水位线是一个时间戳,表示当前处理的数据已经到达的位置。通过控制水位线的传播速度,Flink可以限制数据的流量,避免数据的堆积和延迟。当下游节点处理速度较慢时,水位线的传播速度会相应减慢,从而限制上游节点的生产速度。
缓冲机制
Flink在网络传输和TaskManager内部都使用了缓冲机制来处理反压。
- 网络传输缓冲:在网络传输过程中,Flink使用NetworkBufferPool来管理内存块(MemorySegment)。每个Task都有一个输入区域(InputGate)和输出区域(ResultPartition),它们使用Buffer来存储和传输数据。当数据从上游节点传输到下游节点时,首先会存储在Buffer中,等待下游节点消费。如果下游节点消费速度较慢,Buffer中的数据会逐渐累积,形成反压。此时,Flink会根据Buffer的使用情况来限制上游节点的生产速度。
- TaskManager内部缓冲:在TaskManager内部,Flink为每个Task创建了输入和输出的LocalBufferPool。这些缓冲池用于存储和传输数据。当Task的消费速度跟不上生产速度时,LocalBufferPool中的数据会逐渐累积,形成反压。Flink会根据LocalBufferPool的使用情况来限制Task的生产速度。
关闭Checkpoint
关闭 Checkpoint。关闭 Checkpoint 可以将 barrier 对齐这一步省略掉,促使任务能够快速回溯数据。然后等数据回溯完成之后,再将 Checkpoint 打开