作者:archimekai,转载请注明出处
参考文献: Edara, P., Forbesj, J., & Li, B. (2024). Vortex: A Stream-oriented Storage Engine For Big Data Analytics. Companion of the 2024 International Conference on Management of Data, 175--187. https://doi.org/10.1145/3626246.3653396
文章目录
- [Vortex: A Stream-oriented Storage Engine For Big Data Analytics](#Vortex: A Stream-oriented Storage Engine For Big Data Analytics)
Vortex: A Stream-oriented Storage Engine For Big Data Analytics
免责声明:为了行文连贯,本文中掺杂了一些笔者的推测,请务必对照原论文阅读以免被误导。欢迎批评指正!
为什么?
在数据流(continuous stream)上的数据分析,缩短了从数据产生,到洞察见解的时间。为了更好地支持数据流上的分析,Google BigQuery构建了Vortex系统以支持实时分析。Vortex是一个把数据流放在首要位置的存储系统,其既能支持流式分析,又能支持批处理。借助于Vortex,BigQuery能够支持PB级数据的亚秒级导入和查询。
现有批量数据处理的问题
- 新鲜度:流式数据处理对数据新鲜度的要求较高,现有的离线批量数据导入架构(新鲜度在小时级、天级)无法满足。
- 数据丢失:生成流式数据的应用,通常运行在资源高度受限的环境中。这样的应用难以在本地缓存较多数据,常常需要对数据进行采样以减少数据量,导致数据流式。
- 多次拷贝:批量数据处理中需要多次将中间结果写入临时存储,增加了数据处理时延,难以进行数据管理
路线选择
- 路线一:将现有的批处理改造为支持处理流式数据(Spark)
- 路线二:专门为流式数据处理构建系统,然后将这个系统也用在批处理上(Flink)
Vortex选择了后者。
是什么?
Vortex是一个专为(流式)追加写(append)优化的存储引擎。
- 在架构上,Vortex是高度分布式的,在*region粒度(TODO 待确认)*进行数据复制(可用性较高)的存储引擎
- 在可扩展性上,vortex的数据面和控制面均是分布式的,能够支持单表PB级数据
- 在API上,Vortex为批处理和流处理提供了统一的API
- 在事务能力上,Vortex的所有API均支持ACID性质
- 在性能上,vortex提供亚秒级写入的SLA,这样客户端无需预留很大的buffer缓存要写入的数据
- 在数据类型上,Vortex支持结构化和半结构化数据(见Dremel论文,本次不介绍)
下面本文将从核心概念,架构,API,写入读取流程等方面对Vortex进行分析,并总结一些vortex设计中值得我们借鉴的思路。
核心概念
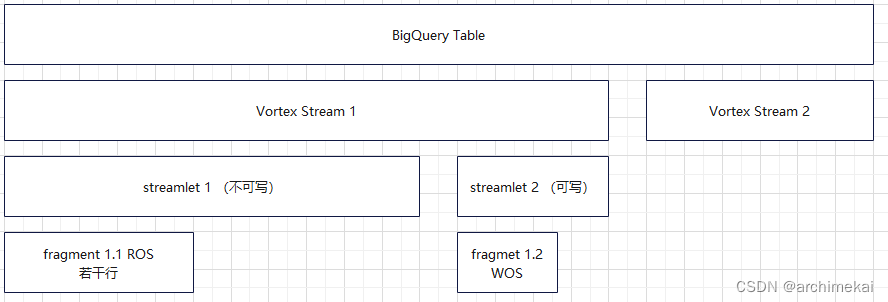
如上图所示,stream是Vortex的核心概念,笔者将围绕stream展开介绍。
vortex stream
Vortex Stream(下文简称stream)是基于BigQuery Table的抽象。在同一个BigQuery Table上,可以同时存在多个stream,因此一个BigQuery Table也可以被视为多个stream的集合。
stream是用来承载写入和读取操作的实体。用户将要写入的行追加到stream的末尾(注意每个stream在当前时刻的末尾都是确定的)。当前已写入stream的行数,也被叫做stream的长度(length)。每一个写入stream的行,都会获得一个row offset。一个客户端可以创建一个或多个stream并发写入同一张表。一张表可以支持上万个客户端同时写入(从而能够达到很快的并发写入速度)。
同一个stream可以被多个reader并发读取。
在Vortex系统内部,一个stream由若干个streamlet组成,一个streamlet又由若干个fragment组成。
streamlet
streamlet由一组连续的行组成,是数据持久性(数据复制)管理的最小单位。为了保证数据的持久性(durability),每行数据(每个streamlet)至少要被写入两个borg cluster才会被认为写入成功。一个stream由一个或多个streamlet组成。stream中最多有一个streamlet是可写的,其必然是stream中的最后一个streamlet。对于可写的streamlet,其元信息(例如streamlet的当前长度)由stream server管理,spanner中保存的元信息仅作为缓存使用。对于已经写完的streamlet,spanner中会保存准确的元信息。
备注:streamlet有点类似于CU。
fragment
streamlet中的行可以进一步被分为若干组连续的行,被叫做fragment。也即一个streamlet由若干个fragment组成。fragment是数据物理存储管理的最小单位。fragment保存在colossus文件系统中的日志文件内。
fragment的大小按如下方式确定:(1)fragment不能太大,以便存储优化服务能比较快地把WOS转换为ROS (2)fragment不能太小,以免在元信息中创建太多的fragment,加重元信息管理的负担。 当向Fragment中写入数据时,Stream Server会缓存最大2MB的数据再写入。
每个fragment上还带有两个时间戳:creation_timestamp, deletion_timestamp。数据读取请求同样携带着一个快照时间戳snapshot_timestamp,通过比较这三个时间戳,可以判断fragment是否对数据读取请求可见。fragment可见的条件为:creation_timestamp <= snapshot_timestamp < deletion_timestamp
Fragment File Format: 如下图所示,文件头中有一个File Map。File Map列出了相同streamlet中的所有已经写入过的Fragment的信息。文件头中还有一个TrueTime时间戳。当数据写入后,还会在文件尾写入一个布隆过滤器,写入一个定长的文件尾。对于BUFFERED类型的流,在进行flush时,还会向Fragment中记录一个元信息,以保存flush时提交到了哪个row offset。

streamlet和fragment对用户不可见,相关信息记录在Spanner中。
WOS与ROS
WOS:write optimized storage format。当数据通过vortex的写入API进入系统后,首先以这种格式存储。顾名思义,这种格式对写入速度比较友好。
ROS: read optimized storage format。数据被写入一段时间后,会被后台的整理任务整理为ROS格式。ROS的主要由两种,也即capacitor和parquet。
架构
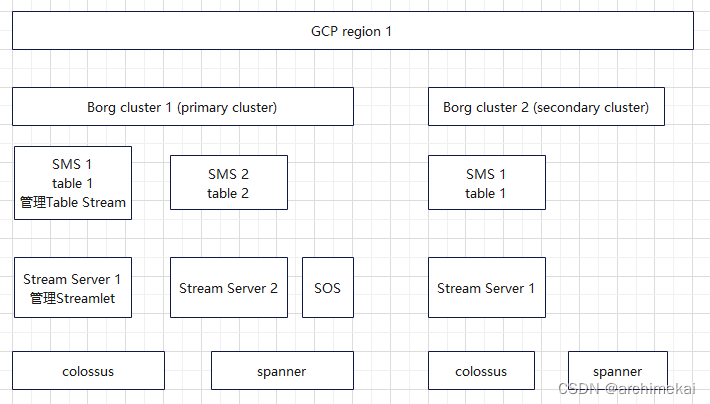
如上图所示,vortex中主要包括stream server, SMS, SOS三个组件。在客户端运行着vortex的client library。
Stream Server
stream server组成vortex的数据平面。stream server负责管理streamlet和fragment的元信息,并通过事务日志和检查点的方式确保上述元信息被持久化。Fragment被存储在colossus上的日志文件中,检查点、事务日志同样也被存储在colossus中。每个borg cluster中常常有上百个stream server。
- Fragment文件:见上文
- 日志文件:日志文件中会多保存一份File Map,以便BigQuery读取数据时,能直接通过Stream Server的日志文件确认有哪些fragments要读取
SMS
SMS即stream metadata server。SMS组成vortex的控制平面。SMS管理stream,streamlet、fragment,并将streamlet分配给某一个Stream Server负责处理。
SOS
SOS即Storage Optimization Service。将WOS转为ROS,并将旧数据标记为已删除。SOS以LSM树的方式维护Fragments。首先,SOS将WOS转换为ROS,同时减少Fragment的数量。SOS还会在后台进行自动数据聚簇。
Thick Client Library
之所以叫做厚客户端,是因为vortex的客户端可以绕过SMS直接同stream server交互,并且支持故障重试。
负载均衡和故障恢复
BigQuery的框架中,每个用户的工作负载由一个主borg cluster和一个辅borg cluster负责处理。具体到Vortex的处理逻辑,当用户使用Vortex写入数据时,优先由主borg cluster进行处理。当主borg cluster暂时不可用时,vortex会透明地转移到辅borg cluster上继续处理。
主borg cluster是以table为粒度进行分配的。也就是说,一个table只能有一个主borg cluster负责处理,多个table的负载可以被均衡到多个borg cluster上。一个table的元信息由主borg cluster中的一个SMS负责处理。Google的数据应用程序负载均衡服务Slicer会监控SMS的状态,当SMS不可用时,Slicer会自动将table的管理任务迁移到主borg cluster中的其他SMS上。当某个SMS负载过高时,Slicer同样会执行类似的迁移动作。由于table的元信息由Spanner管理,元信息的一致性可以由Spanner保证。
核心API示例
enum StreamType {
STREAM_TYPE_UNBUFFERED = 0,
STREAM_TYPE_BUFFERED = 1,
STREAM_TYPE_PENDING = 2,
};
CreateStreamOptions options;
options.set_stream_type(STREAM_TYPE_UNBUFFERED);
Stream s = CreateStream(table_name, options);
RowSet row_set;
// Populate row_set from the input data and the schema.
// ...
// Append data to the end of a Stream.
AppendStreamResponse response = AppendStream(s, row_set,
[row_offset]);
Status status = FlushStream(s, row_offset)
std::vector<Stream> streams = GetStreams();
Status status = BatchCommitStreams(streams);
Status status = FinalizeStream(s);写入流程
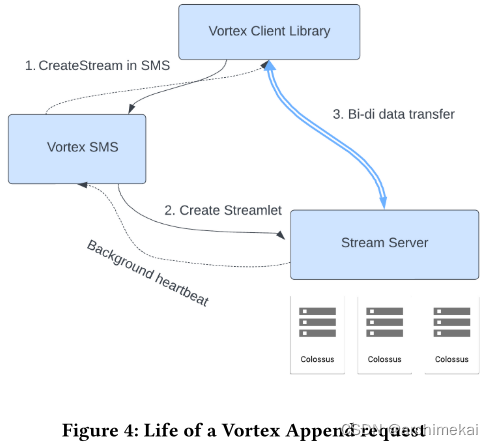
大体流程如下:
- vortex client发送写入请求到SMS
- SMS找到或创建一个未使用的stream,并确保有一个stream server上已创建该stream的streamlet。
- SMS告诉客户端streamlet id和stream server的地址。
- 客户端建立一条到stream server的长连接,以便向streamlet写入数据。
推测的细节如下:
client slicer SMS stream server colossus spanner 本图为推测 CreateStream select a SMS based on load,etc CreateStream select a stream server based on load,etc 返回id,地址给客户端 Create Streamlet data transfer (AppendStream(streamletid)) 何时创建frag? create fragment snappy compress encrypt write frag loop max buffer 2MB finish fragment update metadata loop fragments flush stream write commit record create new stream let 重复上面的写入过程 FinalizeStream client slicer SMS stream server colossus spanner
备注:默认情况下,Vortex不会应用主键约束。也就是用户可以创建主键,但是Vortex仍然允许主键重复。如果用户希望确保主键的唯一性,用户在写入数据时应该只使用UPSERT,DELETE这两种操作,这样vortex就会按照主键的语义操作数据。
读取流程
推测的读取流程如下:
client bigquery spanner Stream Server colossus select xxx gen_snapshot_time() get_frags() (if ss is online,把ss当成缓存用) get_frags() get_frags() (ROS+WOS) filter frags based on snapshot_time read data in frags until last record client bigquery spanner Stream Server colossus
关键点:BigQuery支持直接从colossus上读取vortex所写入的文件。
总结
Vortex中以下设计值得学习:
- 面向写入和读取,使用不同的存储格式,从而兼顾写入性能和读取性能
- 使用thick client library,减轻服务器的压力
- 写入需要server的,但是读取可以不要server,直接让客户端从分布式存储上读,从而降低存储成本