1. 场景与目标
- 目标作业 :Click Event Count(按页面
page对点击事件分桶,做 15 秒滚动窗口计数)。 - 数据特性 :6 个页面,每个页面 每 15 秒产生 1000 条 点击事件,因此每窗口每页的计数应为 1000。
- 组件拓扑 :
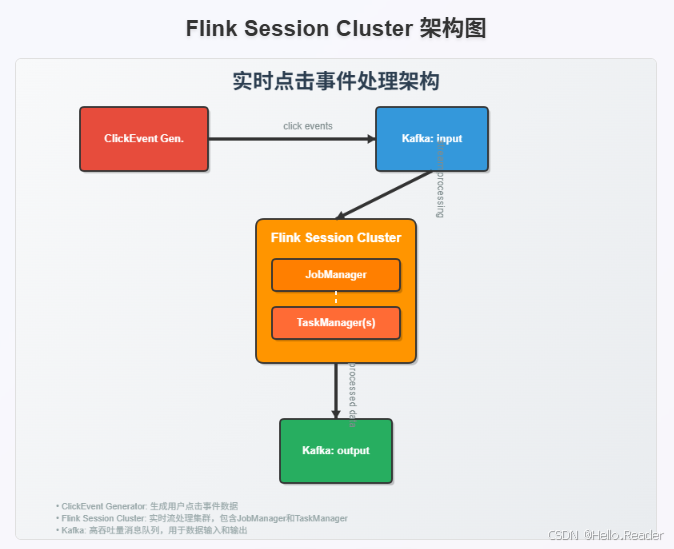
2. 基础概念速览
- Flink Session Cluster :长驻集群,接收多个作业提交。由 JobManager (接收提交/资源管理/监控)与一个或多个 TaskManager(执行 Task,提供 TaskSlots)构成。
- Kafka 集群 :含 Zookeeper 与 Kafka Broker 。操练场启动后创建
input/output两个 topic。 - Client 容器:用于提交作业与执行运维命令,本身不是集群必需,仅为操作便利。
3. 环境准备与启动
3.1 前置条件
- Docker ≥ 20.10
- docker compose ≥ 2.1
3.2 获取工程与构建镜像
bash
git clone https://github.com/apache/flink-playgrounds.git
cd flink-playgrounds/operations-playground
docker compose build3.3 启动操练场
bash
docker compose up -d3.4 验证容器状态
bash
docker compose ps观察点:
operations-playground_client_1Exit 0 → 已成功提交作业;- JobManager/TaskManager/Kafka/Zookeeper/数据生成器均为 Up。
3.5 停止操练场
bash
docker compose down -v4. 观测:WebUI、日志、CLI、REST、Kafka
4.1 Flink WebUI
浏览器访问:http://localhost:8081
- 你应能看到作业 Click Event Count 处于 RUNNING;
- 可查看 JobGraph 、Metrics 、Checkpointing Statistics 、TaskManager 状态 等关键信息。
4.2 查看日志
bash
# JobManager 日志(关注 checkpoint 完成)
docker compose logs -f jobmanager
# TaskManager 日志(关注 checkpoint 完成)
docker compose logs -f taskmanager4.3 Flink CLI(在 client 容器内)
bash
docker compose run --no-deps client flink --help列出运行中的作业:
bash
docker compose run --no-deps client flink list期望输出示例:
------------------ Running/Restarting Jobs -------------------
<timestamp> : <job-id> : Click Event Count (RUNNING)
--------------------------------------------------------------4.4 REST API
列出作业:
bash
curl localhost:8081/jobs查询指定作业详情(含 vertices/metrics/plan 等):
bash
curl localhost:8081/jobs/<job-id>查询作业级指标(示例:最近一次 checkpoint 大小):
bash
curl "localhost:8081/jobs/<job-id>/metrics?get=lastCheckpointSize"4.5 Kafka Topics 验证
持续读取 input 与 output:
bash
# input:约 1000 条/秒
docker compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic input
# output:约 24 条/分钟(6 页 × 每 15 秒 1 条聚合结果 = 每分钟 24 条)
docker compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output正确性校验 :output 中每个 15 秒窗口,每个页面的计数应为 1000。
5. 容错演练:观察失败与恢复(Exactly-Once 视角)
步骤 1:开启 output 观察
bash
docker compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output保持窗口打开直至恢复完成。
步骤 2:制造部分故障(杀掉 TaskManager)
bash
docker compose kill taskmanager现象:
- JobManager 感知 TaskManager 丢失,取消作业并立即重提;
- 作业 tasks 进入 SCHEDULED (紫色),总体状态仍可能显示 RUNNING;
- 期间数据仍持续进入 Kafka
input(模拟真实"作业停摆但数据仍在生产"的场景)。
步骤 3:恢复 TaskManager
bash
docker compose up -d taskmanager恢复过程:
- JobManager 获取新资源后调度任务;
- 各算子自 最近一次成功 checkpoint 恢复状态;
- 作业快速消费停机期间积压的 Kafka 数据,output 短时速率升高;
- 所有窗口与页面的数据完整且计数仍为 1000。
注:示例使用 FlinkKafkaProducer at-least-once,可能产生少量重复输出;生产上可按需配置端到端一致性(两阶段提交等)。
6. 升级与弹性扩缩(Savepoint 驱动)
核心流程 :
1)用 Savepoint 优雅停止作业;
2)从 Savepoint 重启(可变更配置/拓扑/UDF/并行度)。
6.1 先观察 output
bash
docker compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output6.2 生成 Savepoint 并停止作业
获取 <job-id> 后:
bash
docker compose run --no-deps client flink stop <job-id>输出示例(包含保存路径):
Suspending job "<job-id>" with a savepoint.
Savepoint completed. Path: file:<savepoint-path>Savepoint 保存在 Flink 配置
execution.checkpointing.savepoint-dir指定目录(本地挂载到/tmp/flink-savepoints-directory/),记录好<savepoint-path>。
6.3 从 Savepoint 无变更重启
bash
docker compose run --no-deps client flink run -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time验证:恢复后 output 会加速追平 backlog,窗口完整、计数仍为 1000。
6.4 从 Savepoint 变更并行度(Rescaling)
bash
docker compose run --no-deps client flink run -p 3 -s <savepoint-path> \
-d /opt/ClickCountJob.jar \
--bootstrap.servers kafka:9092 --checkpointing --event-time若任务启动等待资源(例如 需要 3 个 slots,只有 2 个),增加 TaskManager:
bash
docker compose scale taskmanager=2新 TaskManager 上线后作业恢复 RUNNING,output 继续无损输出。
7. 指标与状态排查清单
-
WebUI:JobGraph、Checkpointing、Backpressure、Task 错误等一目了然;
-
REST:
- 作业级指标:
/jobs/<job-id>/metrics?get=... - 顶点详情:
/jobs/<job-id>(含 vertices、plan、metrics)
- 作业级指标:
-
日志:
docker compose logs -f jobmanagerdocker compose logs -f taskmanager
-
Kafka:
input/output消费验证吞吐、窗口完整性与计数正确性。
8. 关键运行参数与"变体"行为
--checkpointing:启用 checkpoint 容错。不启用 时,经历故障/恢复会丢数据。--event-time:启用事件时间语义。关闭 时按 wall-clock 分配窗口,每窗口计数不再严格为 1000。--backpressure:开启"反压注入"算子,使 偶数分钟 产生严重反压(如 10:12 有、10:13 无)。可通过 WebUI Backpressure 或网络相关指标(outputQueueLength/outPoolUsage)观察链路健康。
9. 常见问题(FAQ)
- 客户端容器 Exit 1 / 作业未提交
- 检查
docker compose build是否成功; operations-playground_client_1只用于提交/运维,Exit 0 代表提交完成,非异常。
- WebUI 访问不到
- 确认 JobManager 端口映射:
0.0.0.0:8081->8081/tcp; - 检查防火墙/端口占用;
- 拉日志定位:
docker compose logs -f jobmanager。
- output 没数据或计数不对
- 验证
input是否持续有数据; - 检查是否关闭了
--event-time; - 检查 checkpoint 是否启用,且无频繁失败;
- 查看反压/背压导致的积压(Backpressure 页面与网络指标)。
- Savepoint 重启失败
- 路径不正确或不可访问(容器内外路径映射关系);
- 拓扑/状态签名不兼容:升级算子改名/状态 schema 变更需遵守 状态兼容性 规则。
- 提升并行度后任务不启动
- TaskSlots 不足:增加 TaskManager,或调整每 TM 的 slots;
- 资源充足但长时间 SCHEDULED:查看 JobManager/ResourceManager 日志。
10. 进阶建议与生产最佳实践
- 端到端一致性:Source/Sink 选择支持两阶段提交(2PC)或幂等/事务的实现,避免重复;
- 合理的 checkpoint 策略:周期、超时、min pause、外部化等参数结合延迟与资源开销调优;
- 监控报警:对 checkpoint 失败率、背压、堆内存/GC、吞吐/延迟、Kafka lag 等关键指标设置阈值;
- 资源管理:生产推荐对接 K8s/YARN 自动拉起失败进程与弹性伸缩;
- 变更治理:Savepoint 驱动灰度升级;大改动前做状态兼容性评估与回滚预案;
- 容量规划:估算峰值 QPS、窗口状态大小与 RocksDB/off-heap 配置,防止 OOM 与状态膨胀。
11. 小抄(Cheat Sheet)
bash
# 启动
docker compose up -d
# 查看容器
docker compose ps
# WebUI
open http://localhost:8081
# 日志
docker compose logs -f jobmanager
docker compose logs -f taskmanager
# 列出作业
docker compose run --no-deps client flink list
# REST 列表
curl localhost:8081/jobs
# 模拟 TM 故障
docker compose kill taskmanager
# 恢复 TM
docker compose up -d taskmanager
# 生成 Savepoint 并停止
docker compose run --no-deps client flink stop <job-id>
# 从 Savepoint 重启(无变更)
docker compose run --no-deps client flink run -s <savepoint-path> \
-d /opt/ClickCountJob.jar --bootstrap.servers kafka:9092 \
--checkpointing --event-time
# 从 Savepoint 重启(并行度=3)
docker compose run --no-deps client flink run -p 3 -s <savepoint-path> \
-d /opt/ClickCountJob.jar --bootstrap.servers kafka:9092 \
--checkpointing --event-time
# 增加 TaskManager 数量
docker compose scale taskmanager=2
# Kafka 消费
docker compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic input
docker compose exec kafka kafka-console-consumer.sh \
--bootstrap-server localhost:9092 --topic output12. 总结
通过本地 Operations Playground ,你不仅能一站式体验 Flink 在 部署、观测、容错、升级、扩缩 全生命周期的核心运维能力,还能把这些操作习惯迁移到生产环境(K8s/YARN)。从 WebUI/CLI/REST/Kafka 多通道交叉验证到 Savepoint 驱动变更 与 Backpressure 诊断,这套方法论能显著降低运维复杂度与故障处置时间,帮助你持续稳定地交付实时流处理业务。