著名云数据平台Snowflake的研究人员发布了一篇论文,主要对OpenAI的GPT-4系列模型进行了研究,查看其文本生成、图像理解、文档摘要等能力。
在DocVQA、InfographicsVQA、SlideVQA和DUDE数据集上对GPT-4、GPT-4 V、GPT-4 Turbo V +OCR等进行了多维度测试。
结果显示,使用GPT-4去执行解读文档任务时,无法达到满意的效果。这是因为,文档理解不仅是对文本的解析,还涉及到对文档布局、图片视觉内容的理解、推理和整合。

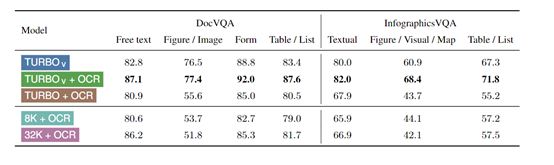
使用GPT-4 V去执行时评测数据有了很大的改善,当使用GPT-4 Turbo V+第三方OCR(光学字符识别)视觉引擎时,例如,Tesseract、Azure Cognitive 、Amazon Textract等,可明显提升大模型的视觉理解能力。
可能存在数据污染
研究人员在DocVQA和InfographicsVQA两个数据集测试GPT-4系列模型时,发现它并不是完全理解测试问题,而是之前在预训练过程中接触过该数据集给出了看似正确的答案,可能存在数据污染的现象。
这是因为,DocVQA和InfographicsVQA两个数据集在GPT-4之前就已经发布,有可能在GPT-4模型训练时被包含在内。如果这些数据集真的被包含在训练数据中,那么模型在这些数据集上的高得分可能并不代表其真正的理解能力,而只是对训练数据的一种记忆。
为了解开这个谜题,研究人员采用了一种"指导性指令"的技术。这种方法通过在模型的输入提示中加入特定的数据集名称,来检查模型是否能够根据数据集的特定特征给出不同的答案。
例如,如果模型在接收到"回答DocVQA数据集测试分割中的问题"的指令后,给出了与接收到"回答SQuAD数据集测试分割中的问题"的指令不同的答案,这可能表明模型对不同数据集有特定的反应。
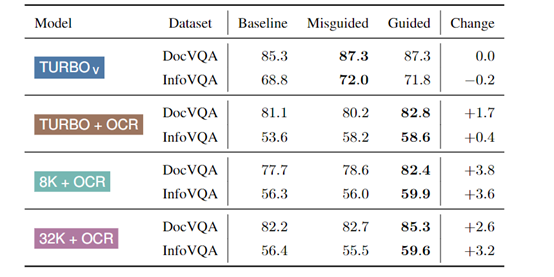
在进行数据污染分析时,当在提示中明确提及数据集名称时,模型的性能有所提高,这可能意味着模型在训练时已经接触过这些数据集,因此在评估时能够给出更加符合预期的答案。
此外,即使是使用不同的数据集名称进行误导性的指导,也可能会改变模型的输出,这进一步表明模型的输出受到了预训练数据的影响。
OCR能提升模型的视觉性能
在测试的实验中,研究者还发现,当GPT-4 Turbo V结合了第三方OCR引擎识别的文本和文档图像输入时,其在文档理解任务上的表现有了显著提升。
这种提升在SlideVQA和DUDE数据集上尤为明显,能够达到最先进的性能水平。这表明OCR技术在增强模型对文档的视觉理解方面发挥了重要作用。
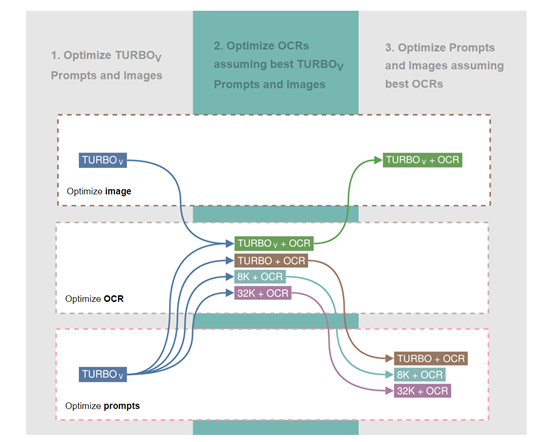
这是因为,OCR能够将图像中的文本内容转换为机器可读的格式,从而使模型能够直接处理文本信息。
在文档理解任务中,这意味着模型不仅能够"看到"文档中的文本,还能够"理解"这些文本的含义。
但不同的OCR例如,Tesseract、Azure Cognitive Services和Amazon Textract。在不同的测试数据集上表现也各不相同。这表明在实际应用中,开发者可以根据应用场景来选择不同的OCR来搭配使用。
本文素材来源Snowflake论文,如有侵权请联系删除
END

