场景:kettle调用http接口获取数据(由于数据量比较大,鉴于网络和性能考虑,所以接口是个分页接口)。
方案:构造页码list,然后循环调用接口。
1、总体设计

1)、初始化分页参数pageNum=1,pageSize=20,这里的pageSize可以根据自己的需求自行调整,比如每次从接口取数100或者1000等等。
2)、第一次请求分页接口,然后保存数据&获取总页数。
3)、根据总分页数据,然后计算出页码list。
4)、循环页码list,单条数据请求http接口。
注:2和4调用的是同一个子trans
2、初始化分页参数

1)这里为了演示方便,使用的生成记录生成了一条数据,其中pageNum=1,pageSize=50
2)这里的pageSize可以根据自己的需求自行调整,比如每次从接口取数100或者1000等等。
3)实际业务场景中有可能用不到生成记录步骤,这个大家根据自己场景进行选择。
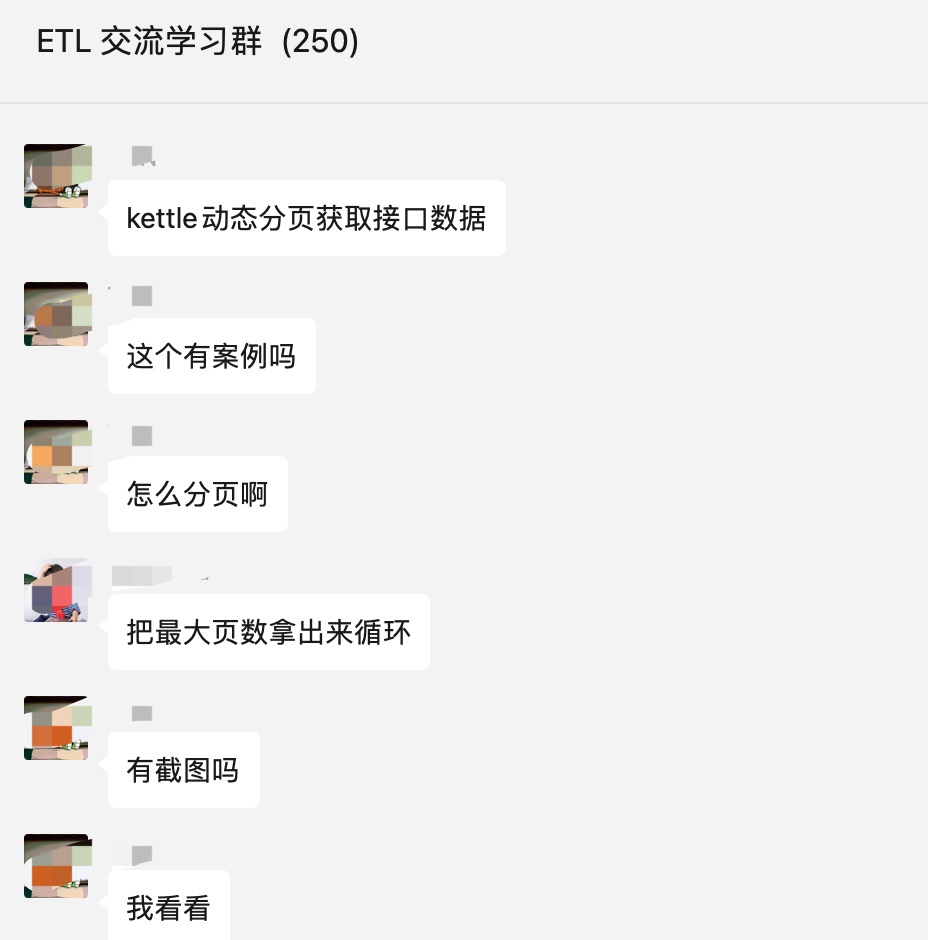
3、第一次请求http接口
1)从以前的结果获取记录步骤获取初始化的参数pageNum=1和pageSize=20
2)这里的模拟http请求使用的是写日志步骤,具体场景中使用的是http post步骤。
3)这里的模拟http响应数据落地是空步骤,具体场景中应该是json input、table output等步骤。
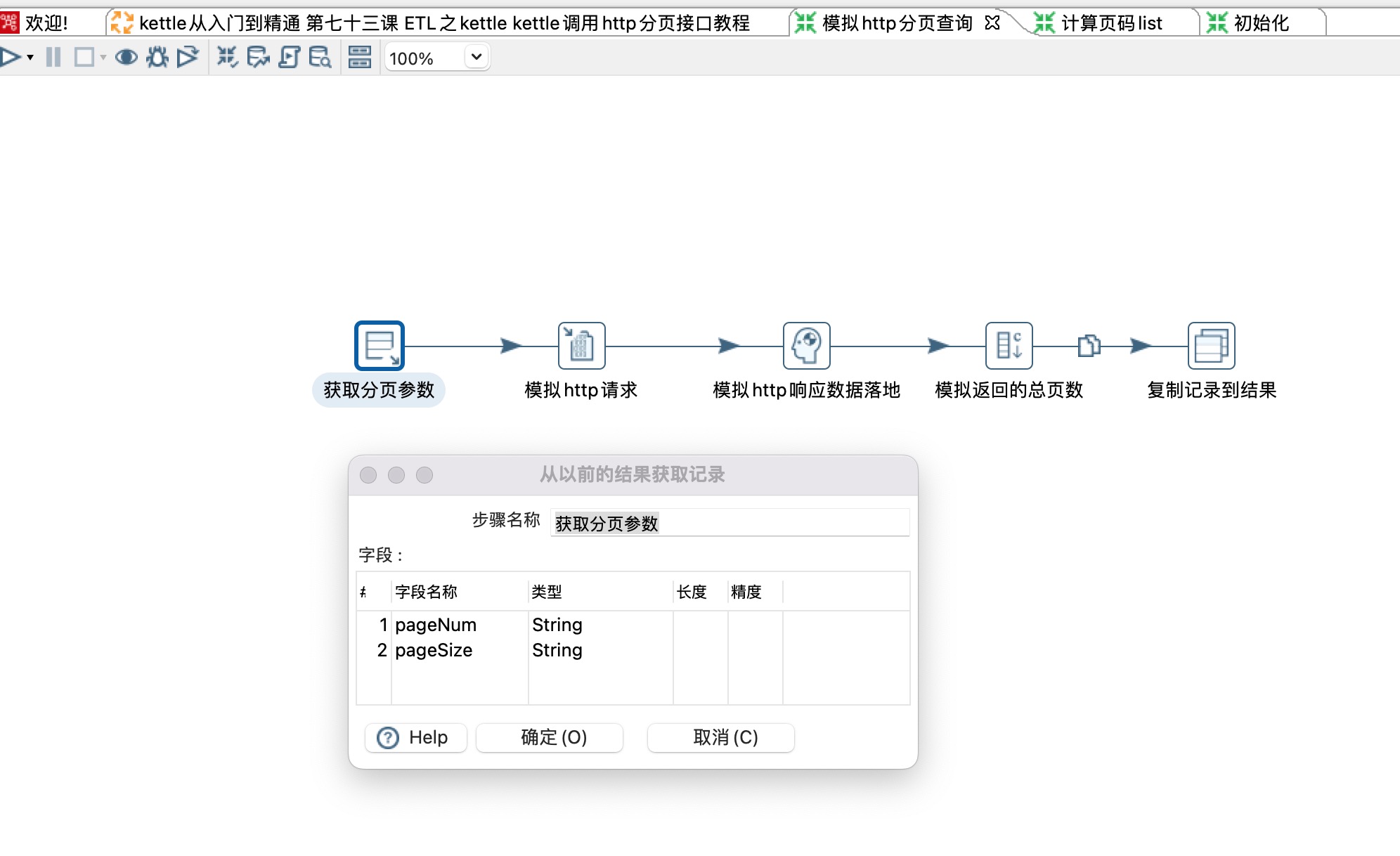
4)模拟接口返回的总页数这里使用的是增加常量,具体使用时应该从json input步骤解析出来totalNum字段。具体的业务场景总页数字段可能不叫totalNum,根据实际情况填写即可。
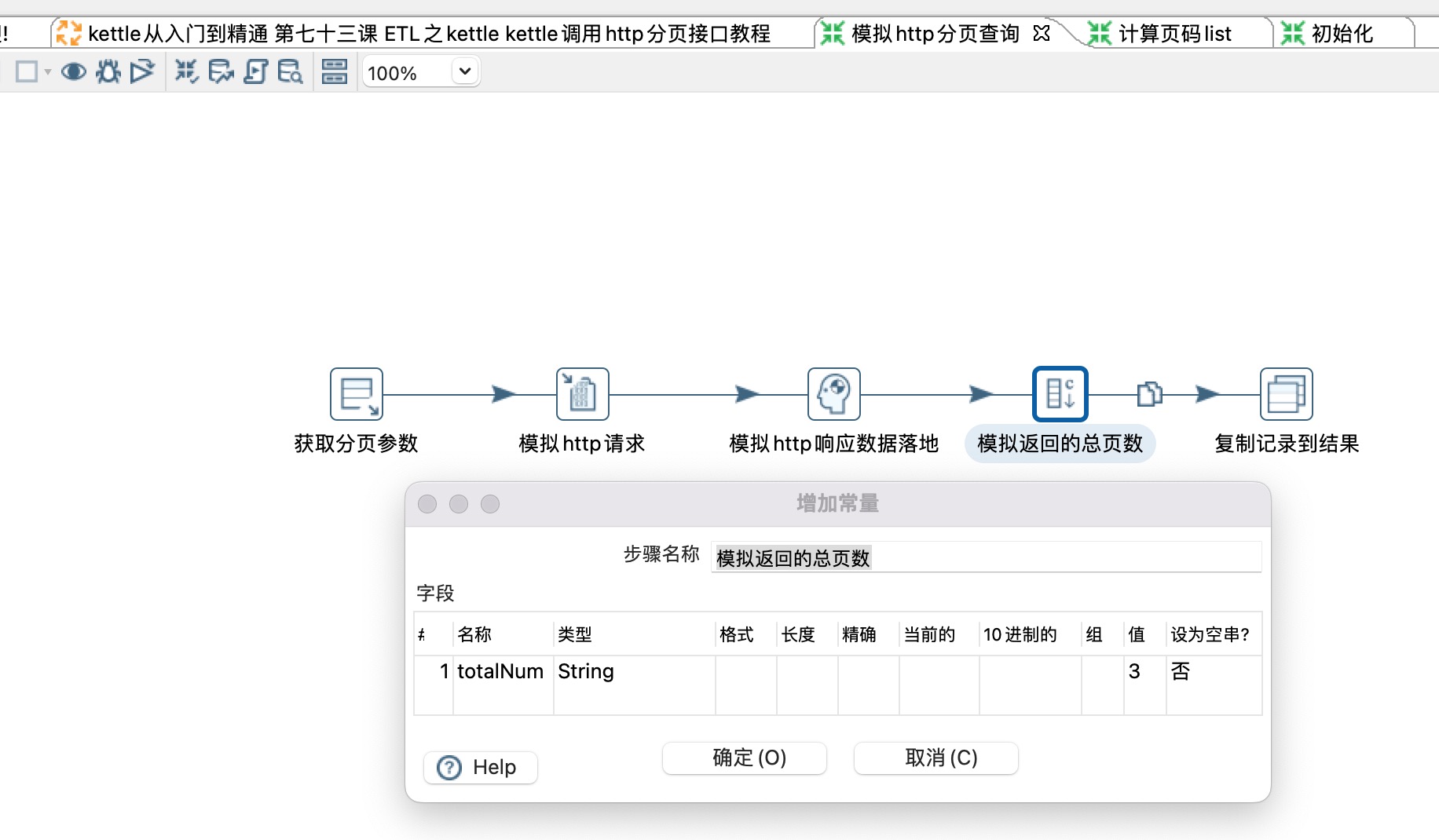
4、计算页码list
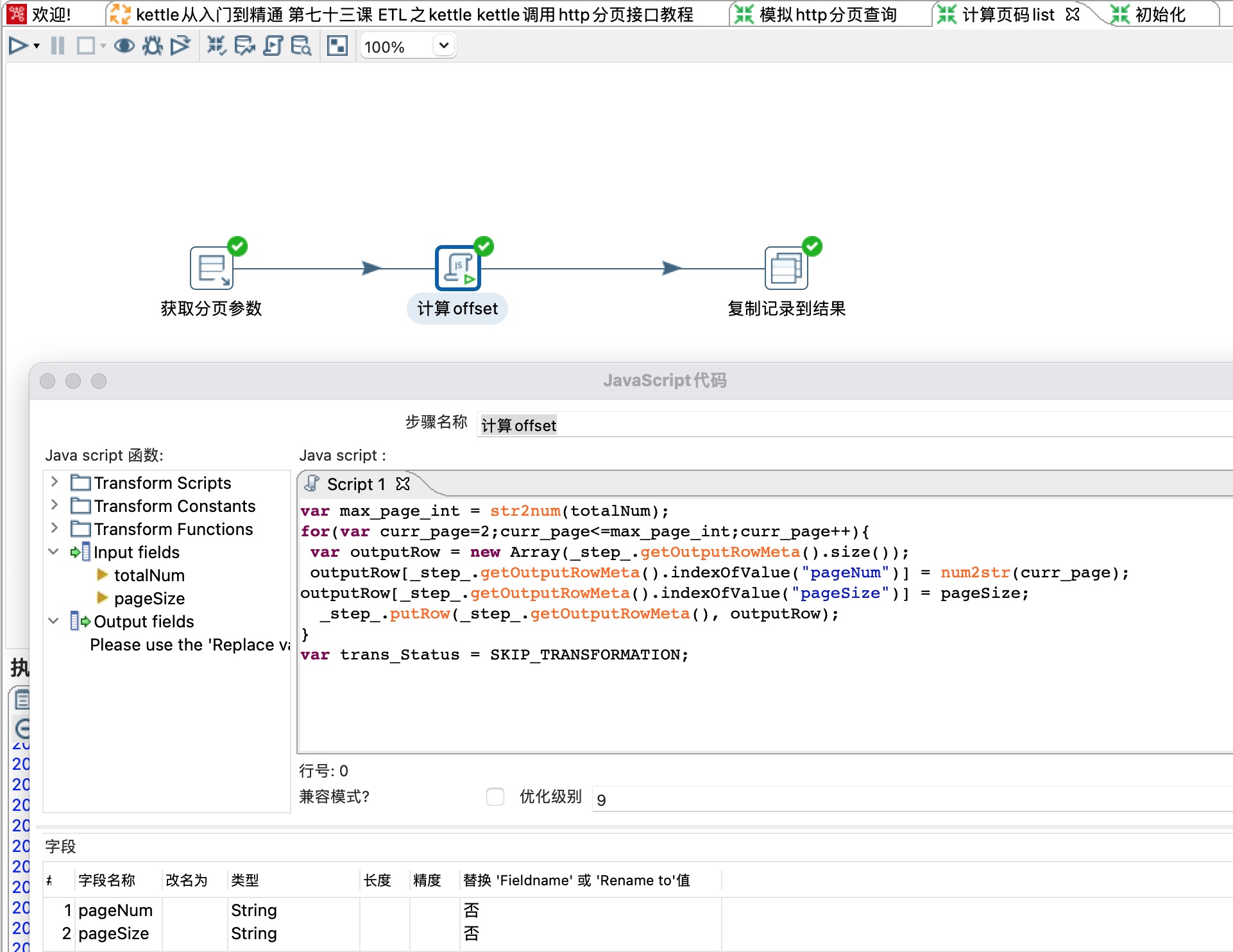
1) 这一步很重要,将单条数据变成list,如上一步的totalNum为3,这里会输出{"paggNum":"2","pageSize":"20"},{"paggNum":"3","pageSize":"20"}
- 脚本如下
var max_page_int = str2num(totalNum);
for(var curr_page=2;curr_page<=max_page_int;curr_page++){
var outputRow = new Array(_step_.getOutputRowMeta().size());
outputRow[_step_.getOutputRowMeta().indexOfValue("pageNum")] = num2str(curr_page);
outputRow[_step_.getOutputRowMeta().indexOfValue("pageSize")] = pageSize;
_step_.putRow(_step_.getOutputRowMeta(), outputRow);
}
var trans_Status = SKIP_TRANSFORMATION;5、循环请求http接口(从第二页开始)
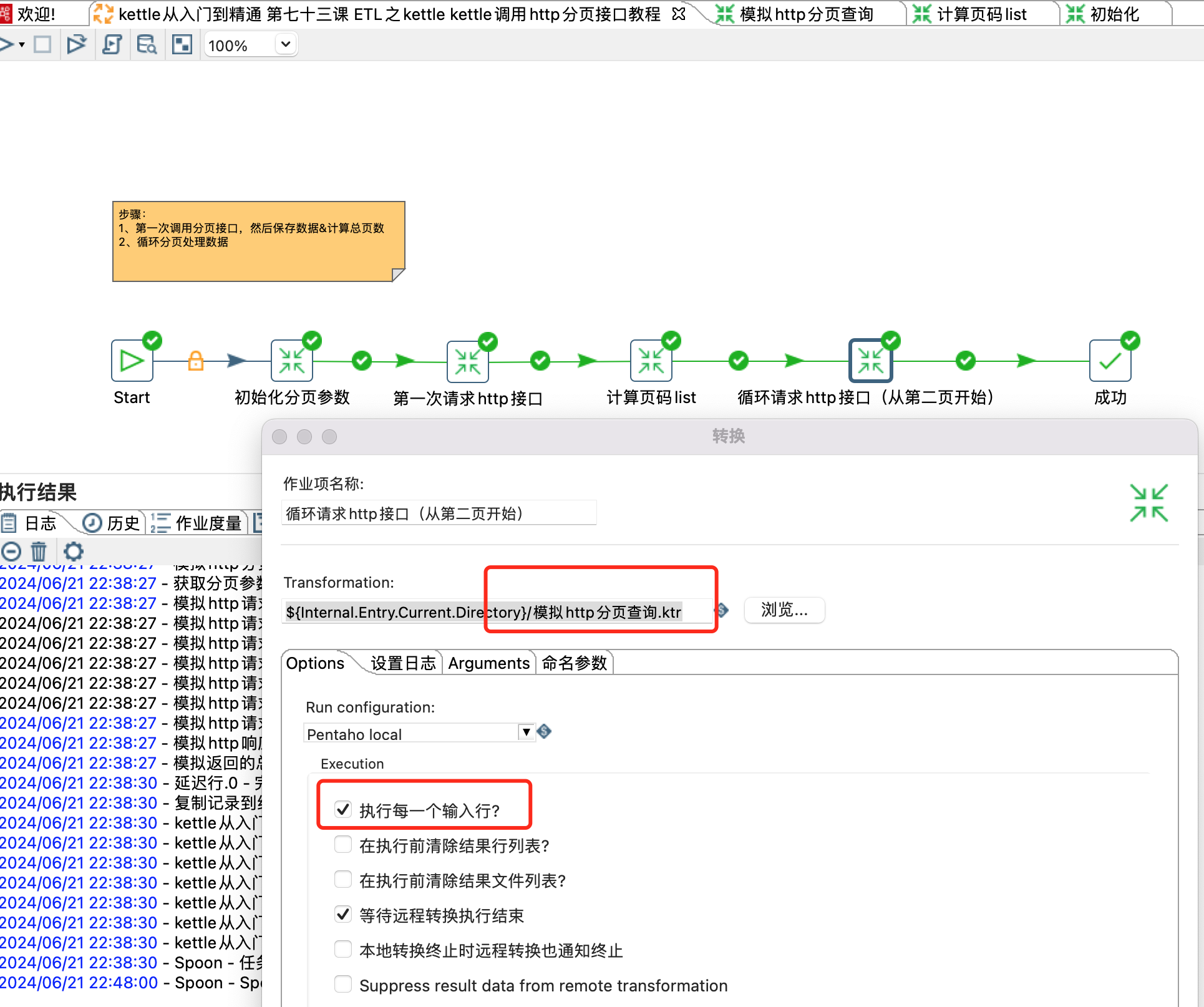
1)这里一定要勾选执行每一个输入行,勾选之后才会执行for循环操作。会循环上一步的结果{"paggNum":"2","pageSize":"20"},{"paggNum":"3","pageSize":"20"}
2)这一步调用子trans和第一次请求http接口的子trans是一样的。细心的朋友可能会发现其实只有第一次请求http接口之后才关心totalNum,之后的请求都不会关心这个totalNum。
注:kettle是个非常灵活的工具,这里只是提供了一个思路而已,大家如果有更好的实现思路,评论区或者沟通交流群告诉我。
