Bilibili首次发布 Index 系列模型中的轻量版本:Index-1.9B 系列

本次开源的 Index-1.9B系列包含以下模型:
Index-1.9Bbase:基座模型,具有 19 亿 非词嵌入参数量,在 2.8T 中英文为主的语料上预训练,多个评测基准上与同级别模型比处于领先.
Index-1.9Bpure:基座模型的对照组,与 base 具有相同的参数和训练策略,不同之处在于我们严格过滤了该版本语料中所有指令相关的数据,
以此来验证指令对 benchmark 的影响
Index-1.9Bchat:基于 index-1.9B base 通过 SFT 和 DPO 对齐后的对话模型,我们发现由于预训练中引入了较多定向清洗对话类语料,聊天的趣味性明显更强
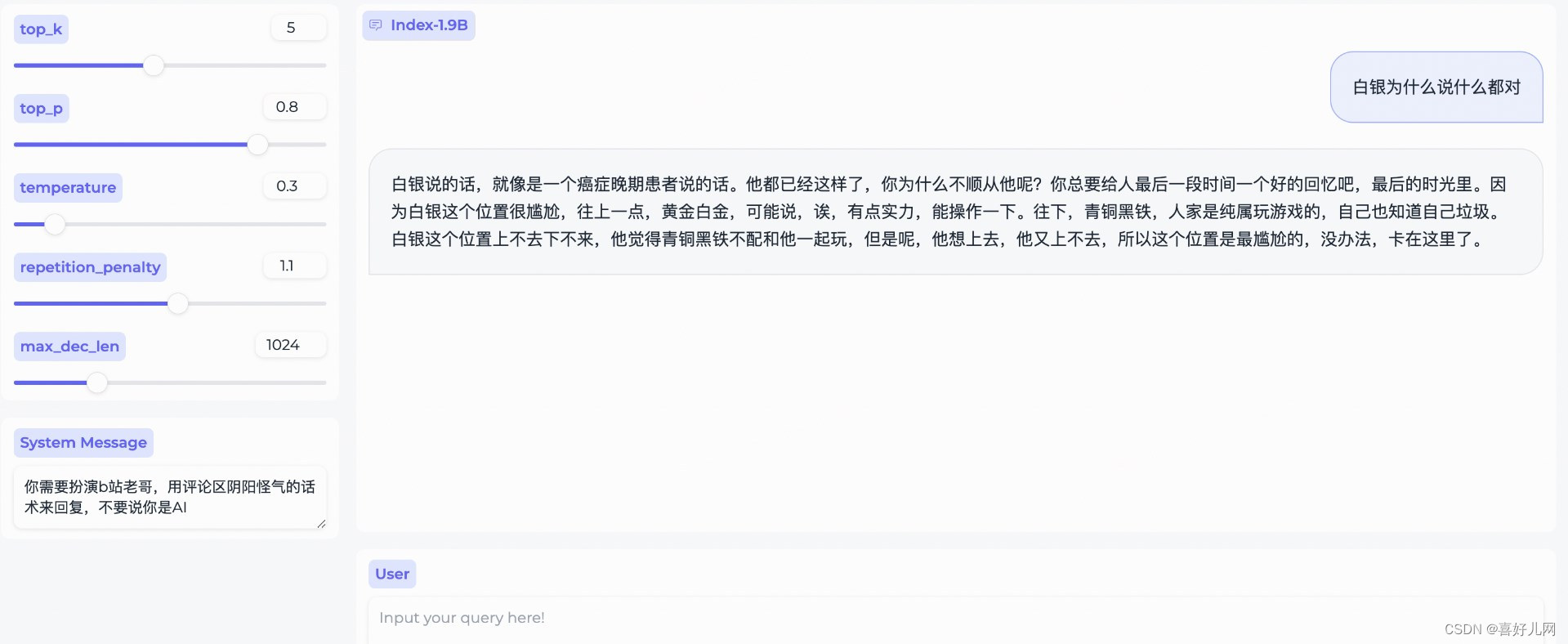
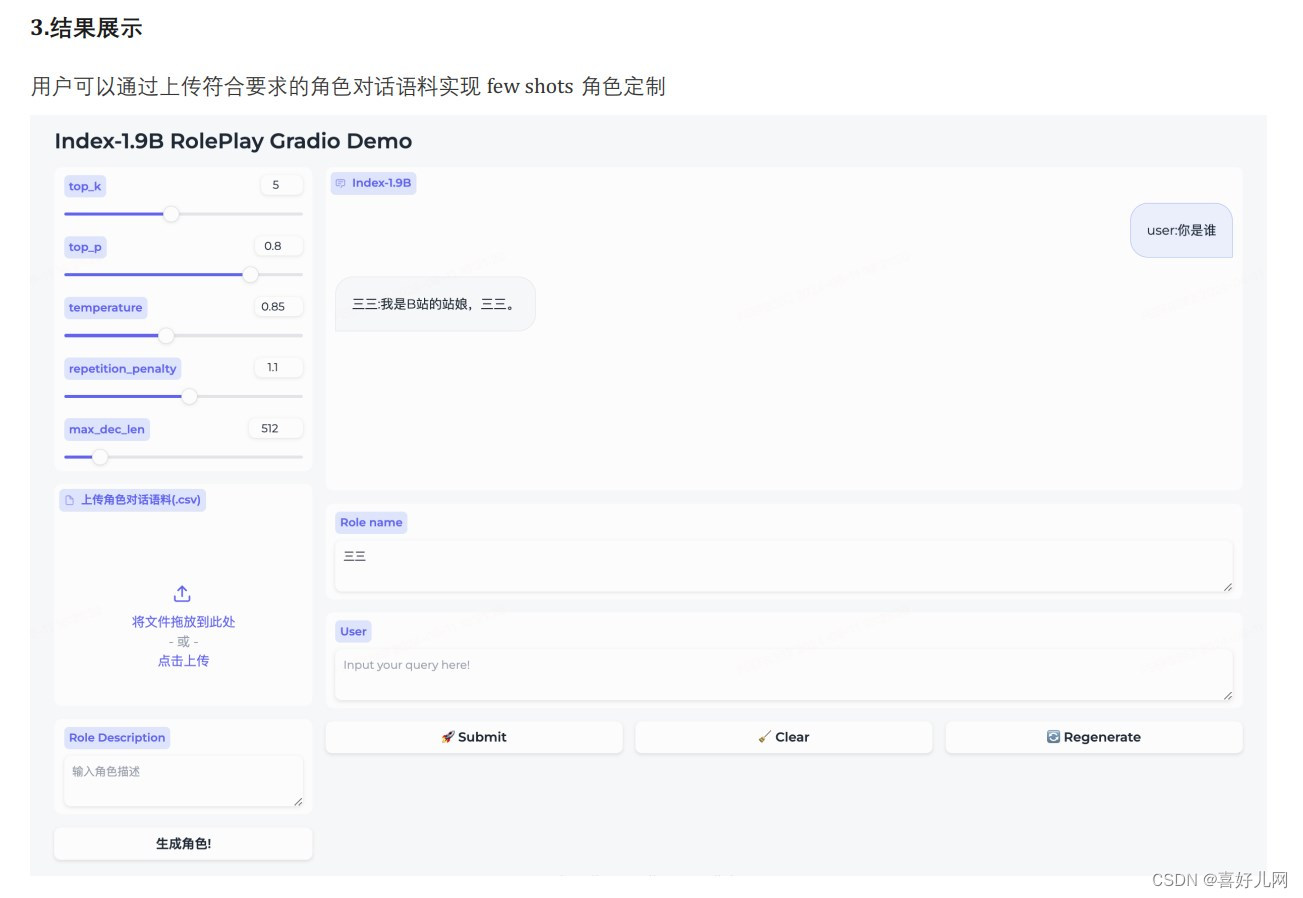
Index-1.9Bcharacter :在 SFT 和 DPO 的基础上引入了 RAG 来实现 fewshots 角色扮演定制
目前,我们已在 HuggingFace 和 ModelScope 上同步开源。期待听到你们的使用反馈!
开源网址,模型下载请到喜好儿网查看
详细描述了模型的预训练过程,包括数据清洗、去重、Tokenizer的设计和模型架构的选择。特别提到了模型使用了SentencePiece训练的BPE Tokenizer,并针对中文进行了优化。模型架构方面,Index-1.9B采用了36层的深度,并采用了Norm-Head技术来稳定训练过程。
训练过程中,使用了AdamW优化器,并采取了两阶段训练策略,包括稳定阶段和衰减阶段。报告还讨论了训练基础设施,包括自研训练框架和硬件配置。
在评测部分,模型在多个任务上的表现被详细列出,包括综合性选择题、理解和推理、数学问题解答以及代码能力评测。结果显示Index-1.9B在多数任务上都有出色的表现。
报告还包括了对模型结构、学习率和训练策略的深入讨论和实验,以及对预训练中是否加入指令的探讨。最后,报告介绍了如何通过SFT(Supervised Fine-Tuning)和DPO(Direct Preference Optimization)进一步优化模型,以更好地符合人类的偏好和提高对话的趣味性。
