1.2 神经网络基础
学习目标
- 知道逻辑回归的算法计算输出、损失函数
- 知道导数的计算图
- 知道逻辑回归的梯度下降算法
- 知道多样本的向量计算
应用
- 应用完成向量化运算
- 应用完成一个单神经元神经网络的结构
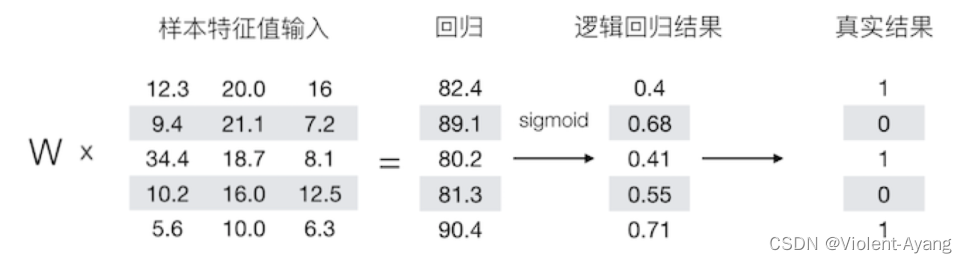
1.2.1 Logistic回归
逻辑回归是一个主要用于二分分类的算法。给定一个特征向量 x ,输出该样本属于类别1的预测概率 y ^ = P ( y = 1 ∣ x ) \hat{y} = P(y=1|x) y^=P(y=1∣x) 。
参数
- 输入的特征向量: x ∈ R n x x \in \mathbb{R}^{n_x} x∈Rnx
- 用于训练的标签: y ∈ { 0 , 1 } y \in \{0,1\} y∈{0,1}
- 参数:权重 w ∈ R n x w \in \mathbb{R}^{n_x} w∈Rnx ,偏置 b ∈ R b \in \mathbb{R} b∈R
- 输出预测结果: y ^ = σ ( w T x + b ) = σ ( θ T x ) \hat{y} = \sigma(w^T x + b) = \sigma(\theta^T x) y^=σ(wTx+b)=σ(θTx)
- Sigmoid 函数: σ ( z ) = 1 1 + e − z \sigma(z) = \frac{1}{1+e^{-z}} σ(z)=1+e−z1
性质
- 如果z的结果非常大,那么S的结果接近于1
- 如果z的结果较小或者是非常大的负数,那么S的结果接近于0
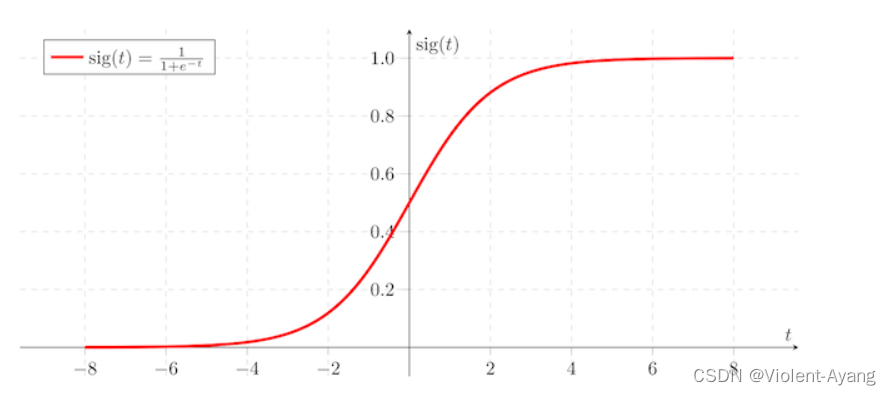
例如:
逻辑回归损失函数与代价函数
损失函数的理解
逻辑回归通常使用以下损失函数定义单个训练样本的表现:
L ( y , y ^ ) = ( y ⋅ log ( y ^ ) − ( 1 − y ) ⋅ log ( 1 − y ^ ) ) L(y, \hat{y}) = (y \cdot \log(\hat{y}) - (1 - y) \cdot \log(1 - \hat{y})) L(y,y^)=(y⋅log(y^)−(1−y)⋅log(1−y^))
该式子的理解如下:
- 如果 y = 1 ,损失为 − log ( y ^ ) -\log(\hat{y}) −log(y^),那么要想损失越小, y ^ \hat{y} y^的值必须越大,即越趋近于或者等于 1。
- 如果 y = 0 ,损失为 log ( 1 − y ^ ) \log(1 - \hat{y}) log(1−y^),那么要想损失越小, y ^ \hat{y} y^ 的值越小,即趋近于或者等于 0。
代价函数
损失函数是在单个训练样本中定义的,它衡量了模型在单个训练样本上的表现。而代价函数(cost function)衡量的是在全体训练样本上的表现,即衡量参数 ( w ) 和 ( b ) 的效果。代价函数是所有训练样本损失的平均值,定义如下:
J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) J(w, b) = \frac{1}{m} \sum_{i=1}^{m} L(\hat{y}(i), y(i)) J(w,b)=m1i=1∑mL(y^(i),y(i))
其中 m 是训练样本的数量, y ^ ( i ) \hat{y}(i) y^(i)是模型预测的第 i i i个样本的输出, y ( i ) y(i) y(i)是第 i i i个样本的实际标签。
1.2.1.2 逻辑回归损失函数
损失函数用于衡量预测结果与真实值之间的误差。逻辑回归一般使用以下损失函数:
L ( y ^ , y ) = − ( y log ( y ^ ) + ( 1 − y ) log ( 1 − y ^ ) L(\hat{y}, y) = -(y \log(\hat{y}) + (1 - y) \log(1 - \hat{y}) L(y^,y)=−(ylog(y^)+(1−y)log(1−y^)
1.2.2 梯度下降算法
目的:使损失函数的值找到最小值。
方式:梯度下降。梯度的方向指出了函数增长最快的方向,按梯度的负方向走,函数值降低得最快。
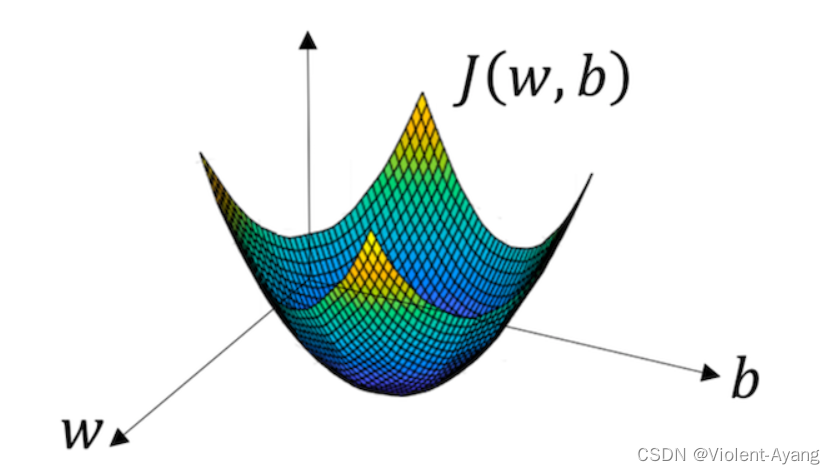
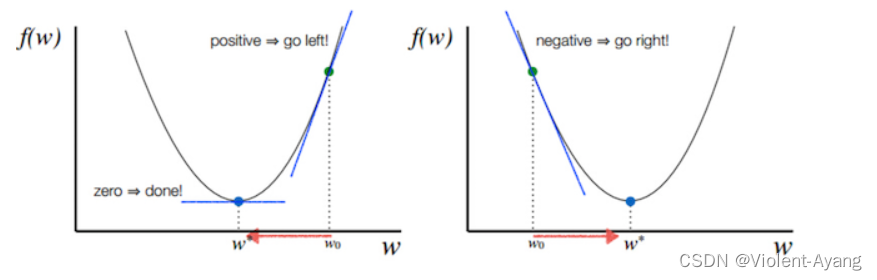
函数的梯度(gradient)指出了函数的最陡增长方向。梯度的方向走,函数增长得就越快。那么按梯度的负方向走,函数值自然就降低得最快了。模型的训练目标即是寻找合适的 w 与 b 以最小化代价函数值。假设 w 与 b 都是一维实数,那么可以得到如下的 J 关于 w 与 b 的图:
参数更新公式:
w : = w − α d J ( w , b ) d w w := w - \alpha \frac{dJ(w, b)}{dw} w:=w−αdwdJ(w,b)
b : = b − α d J ( w , b ) d b b := b - \alpha \frac{dJ(w, b)}{db} b:=b−αdbdJ(w,b)
其中 α \alpha α 表示学习速率。
注:其中 α 表示学习速率,即每次更新的 w 的步伐长度。当 w 大于最优解 w′ 时,导数大于 0,那么 w 就会向更小的方向更新。反之当 w 小于最优解 w′ 时,导数小于 0,那么 w 就会向更大的方向更新。迭代直到收敛。
通过平面来理解梯度下降过程:
1.2.3 导数
导数可以理解为某一点处的斜率。导数的计算可以通过导数计算图来辅助理解。
- 各点处的导数值一样
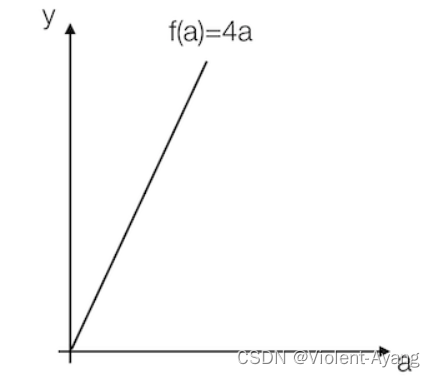
我们看到这里有一条直线,这条直线的斜率为4。我们来计算一个例子
例:取一点为a=2,那么y的值为8,我们稍微增加a的值为a=2.001,那么y的值为8.004,也就是当a增加了0.001,随后y增加了0.004,即4倍
那么我们的这个斜率可以理解为当一个点偏移一个不可估量的小的值,所增加的为4倍。
- 各点的导数值不全一致
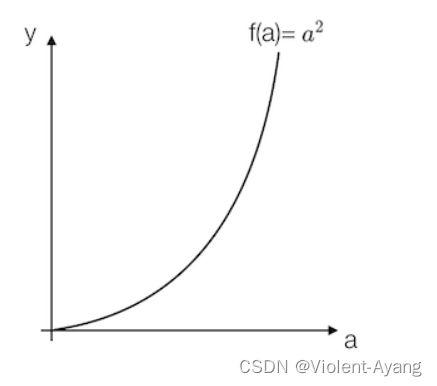 例:取一点为a=2,那么y的值为4,我们稍微增加a的值为a=2.001,那么y的值约等于4.004(4.004001),也就是当a增加了0.001,随后y增加了4倍
例:取一点为a=2,那么y的值为4,我们稍微增加a的值为a=2.001,那么y的值约等于4.004(4.004001),也就是当a增加了0.001,随后y增加了4倍
取一点为a=5,那么y的值为25,我们稍微增加a的值为a=5.001,那么y的值约等于25.01(25.010001),也就是当a增加了0.001,随后y增加了10倍
可以得出该函数的导数2为2a。
- 更多函数的导数结果
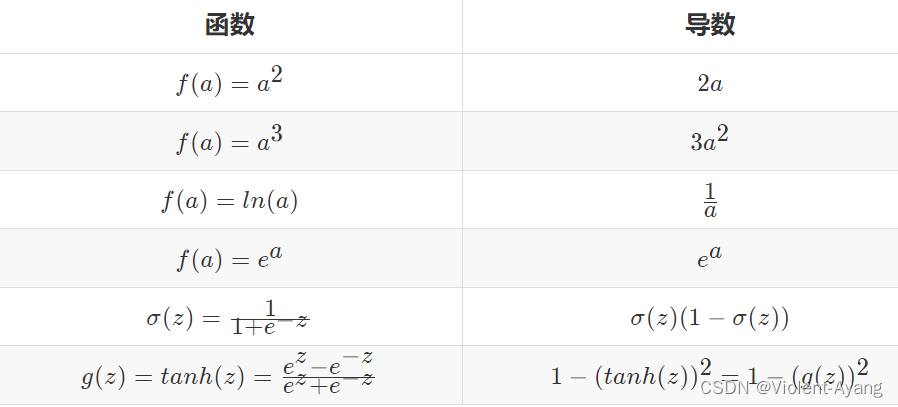
1.2.3.1 导数计算图
导数计算图说明了含有多个变量的函数导数的计算流程。
那么接下来我们来看看含有多个变量的到导数流程图,假设
𝐽(𝑎,𝑏,𝑐)=3(𝑎+b𝑐)
我们以下面的流程图代替
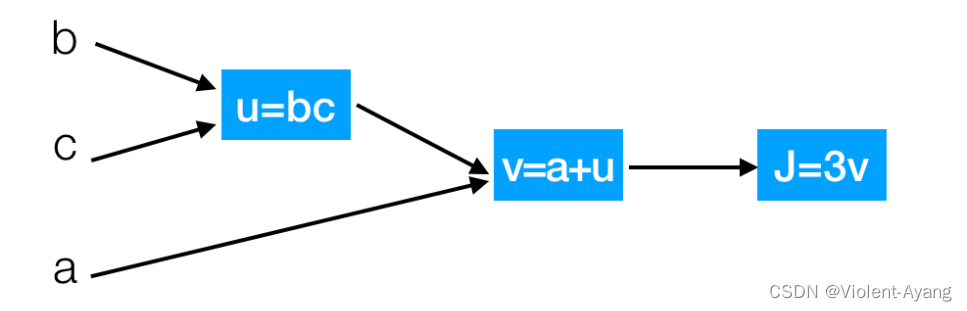
这样就相当于从左到右计算出结果,然后从后往前计算出导数
1.2.3.2 逻辑回归的梯度下降
逻辑回归的梯度下降过程涉及到计算损失函数相对于参数的导数,并更新参数以最小化损失。
1.2.4 向量化编程
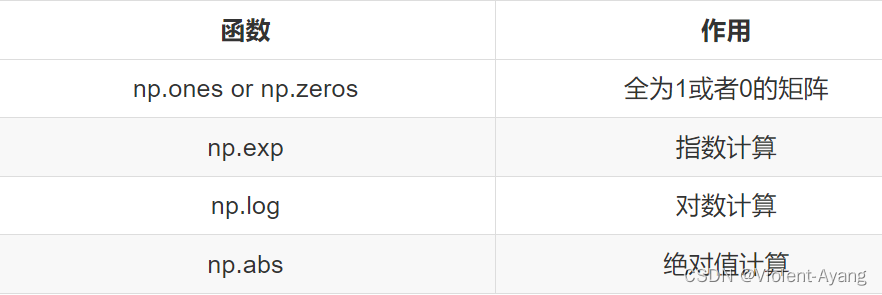
向量化编程避免了显式的循环,利用如Numpy这类库进行高效的数组运算。
python
import numpy as np
import time
a = np.random.rand(100000)
b = np.random.rand(100000)- 第一种方法
python
# 第一种for 循环
c = 0
start = time.time()
for i in range(100000):
c += a[i]*b[i]
end = time.time()
print("计算所用时间%s " % str(1000*(end-start)) + "ms")- 第二种向量化方式使用np.dot
python
# 向量化运算
start = time.time()
c = np.dot(a, b)
end = time.time()
print("计算所用时间%s " % str(1000*(end-start)) + "ms")Numpy能够充分的利用并行化,Numpy当中提供了很多函数使用
1.2.5 正向传播与反向传播
正向传播是指从输入到输出的计算过程,而反向传播是误差从输出层反向传递到输入层的过程,用于计算和更新网络中的参数。