👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

python海底捞门店数据分析与可视化(数据集+源码+论文)【独一无二】
目录
一、设计要求
项目背景
本项目旨在通过数据分析和可视化的方法,对海底捞门店的营业数据进行深入的探索和理解。数据来源于Excel文件《海底捞门店数据.xlsx》。项目包括数据预处理、缺失值处理、异常值处理、重复值处理、数据转换、分组统计分析和数据可视化。
主要功能
-
数据读取与预览
- 从Excel文件中读取数据,展示数据的前几行,提供数据的基本信息,包括行列数、数据类型和非空数统计。
-
缺失值处理
- 统计数据中的缺失值总数。
- 提供两种处理缺失值的方法:删除含有缺失值的记录和用众数填充缺失值。
-
异常值处理
- 使用箱型图可视化数据,识别异常值。
- 提供两种去除异常值的方法:四分位数间距法(IQR)和3σ原则。
-
重复值处理
- 检查并删除数据中的重复值。
-
数据转换
- 将"省份"列转换为数值型数据,便于后续分析。
-
分组统计分析
- 按省份分组统计各省店铺数量。
- 按营业时长分组统计各时长区间内的店铺数量。
-
数据可视化
- 可视化各省店铺数量分布。
- 可视化营业时长分布。
- 可视化开始营业时间分布。
- 可视化结束营业时间分布。
二、设计思路
1. 导入库和设置
python
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号- 导入必要的库:
pandas用于数据处理,matplotlib和seaborn用于数据可视化。 - 设置绘图时中文字体的显示,确保中文标签能正常显示。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 " 门店 " 获取。👈👈👈
2. 读取数据
python
file_path = '海底捞门店数据.xlsx'
df = pd.read_excel(file_path, engine='openpyxl')- 从Excel文件中读取数据到一个DataFrame中。
3. 数据预览和基本信息
python
print("数据预览:")
# 代码略....👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 "门店" 获取。👈👈👈
print("缺失值总数:")
print(df.isnull().sum())
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 " 门店 " 获取。👈👈👈

- 打印数据的前几行,显示数据的基本信息(行列数、数据类型和非空数)。
- 统计缺失值的总数。
4. 处理缺失值
python
# 删除含有缺失值的记录
# 代码略....
print(df_dropna.isnull().sum())
# 用众数填充缺失值
df_fillna = df.fillna(df.mode().iloc[0])
# 代码略....👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 "门店" 获取。👈👈👈
print(df_fillna.isnull().sum())- 处理缺失值的方法包括:
- 删除含有缺失值的记录。
- 用众数填充缺失值。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 " 门店 " 获取。👈👈👈
5. 处理异常值
python
# 箱型图识别异常值
plt.figure(figsize=(10, 6))
# 代码略....
plt.show()
# 四分位数间距法去除异常值
# 代码略....👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 "门店" 获取。👈👈👈
IQR = Q3 - Q1
df_no_outliers = df[~((df['营业时长'] < (Q1 - 1.5 * IQR)) | (df['营业时长'] > (Q3 + 1.5 * IQR)))]
print("去除异常值后的数据行列数: ", df_no_outliers.shape)
# 3σ原则去除异常值
mean = df['营业时长'].mean()
# 代码略....👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 "门店" 获取。👈👈👈
print("3σ原则去除异常值后的数据行列数: ", df_no_outliers_sigma.shape)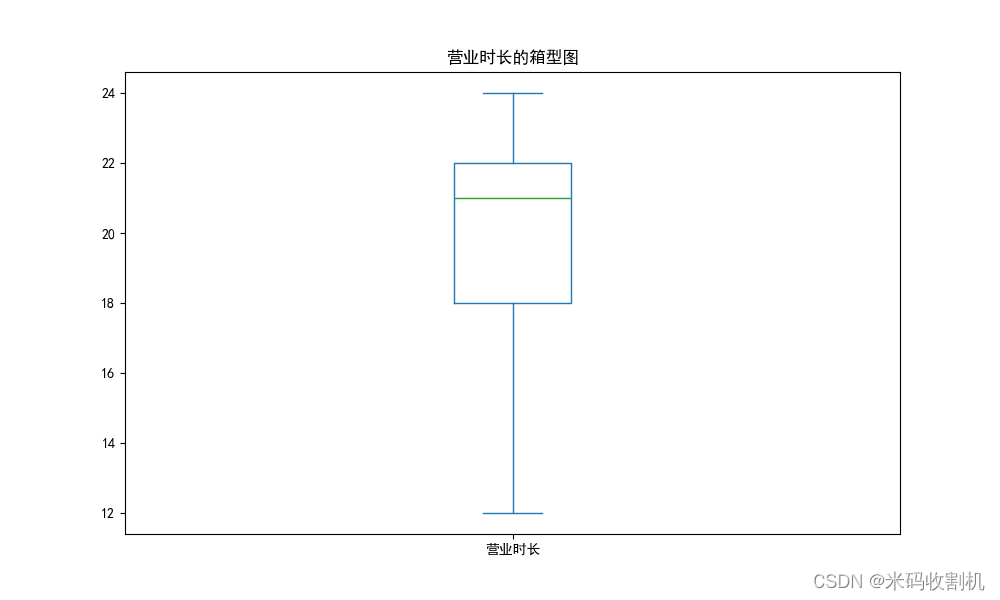
- 使用箱型图可视化数据,识别异常值。
- 使用四分位数间距法(IQR)和3σ原则去除异常值。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 " 门店 " 获取。👈👈👈

6. 处理重复值
python
df_no_duplicates = df.drop_duplicates()
print("删除重复值后的数据行列数: ", df_no_duplicates.shape)- 删除重复值。
7. 数据转换
python
# 代码略....👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 "门店" 获取。👈👈👈
print("转换后的数据预览:")
print(df.head())- 将"省份"列转换为数值型数据,便于后续分析。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 " 门店 " 获取。👈👈👈
8. 数据分组和统计分析
python
# 按省份分组统计各省店铺数量
# 代码略....👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 "门店" 获取。👈👈👈
print("按省份分组统计:")
print(province_group)
python
# 按营业时间长度分组统计
time_group = df.groupby('营业时长')['店名'].count().reset_index()
# 代码略....👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 "门店" 获取。👈👈👈
print("按营业时间长度分组统计:")
print(time_group)
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 " 门店 " 获取。👈👈👈
- 按省份和营业时长分组,统计各组的店铺数量。
9. 数据可视化
python
# 店铺数量按省份分布
plt.figure(figsize=(14, 7))
# 代码略....
# 代码略....
plt.show()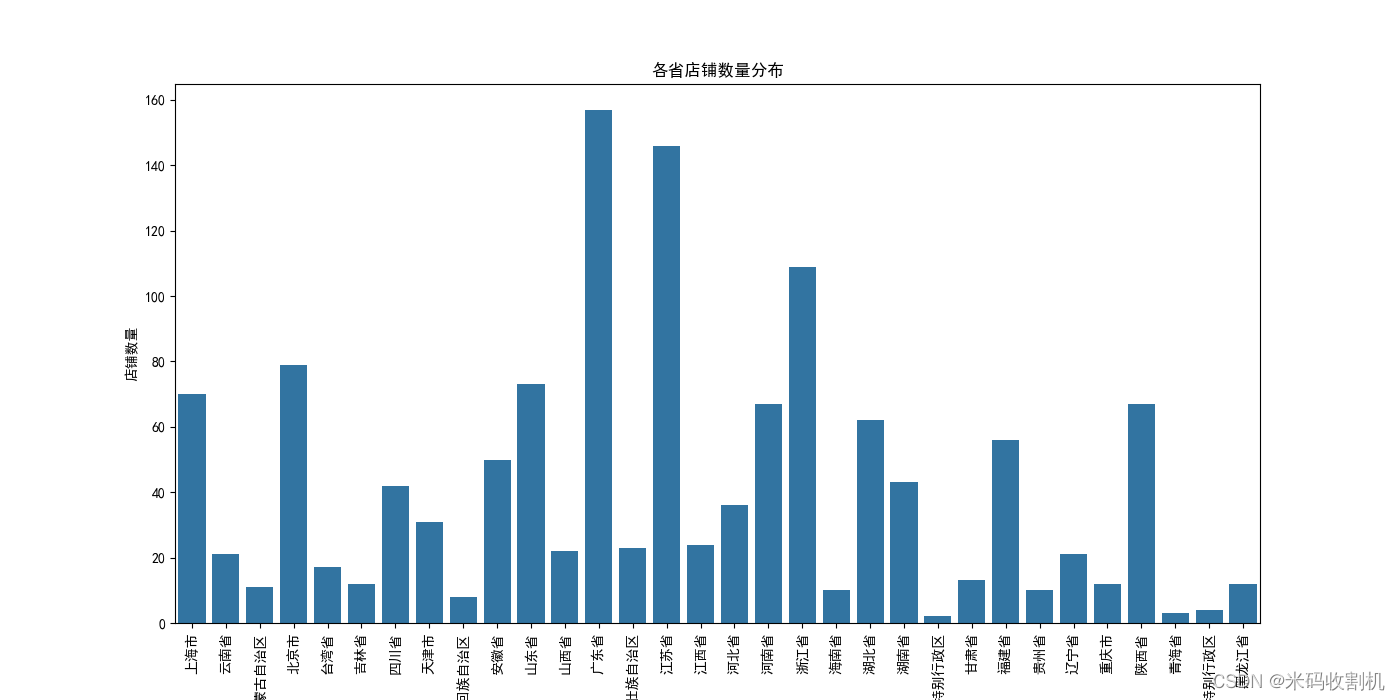
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 " 门店 " 获取。👈👈👈
python
# 营业时长分布
plt.figure(figsize=(10, 6))
# 代码略....
# 代码略....
plt.show()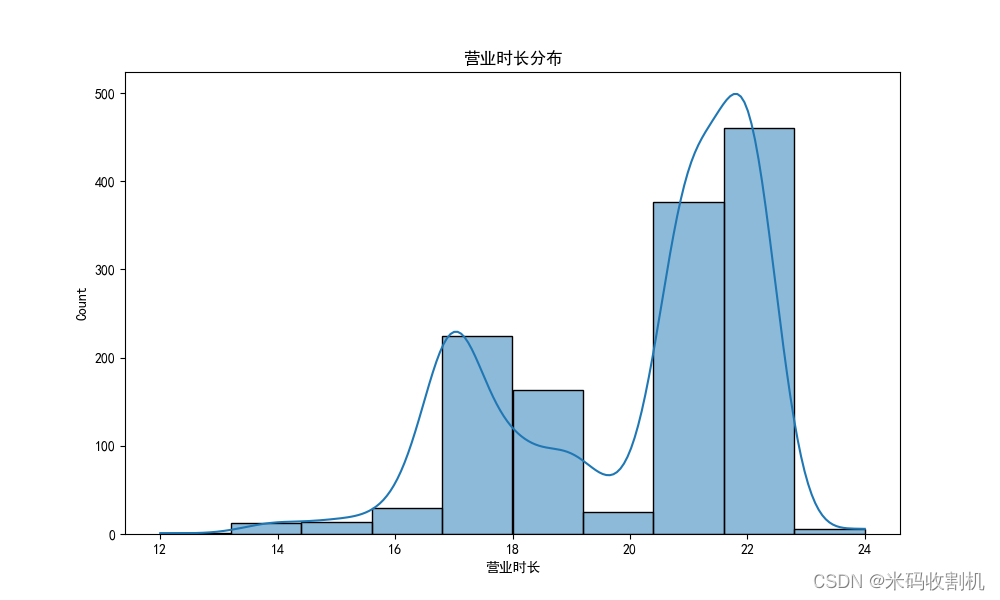
python
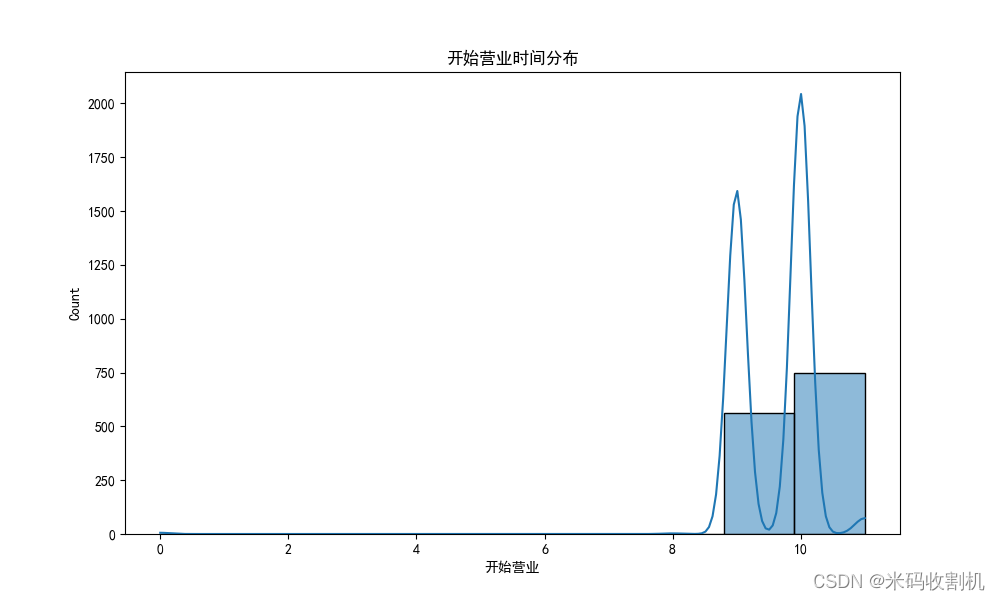
# 开始营业时间分布
plt.figure(figsize=(10, 6))
# 代码略....
# 代码略....
plt.show()👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 " 门店 " 获取。👈👈👈
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 " 门店 " 获取。👈👈👈
python
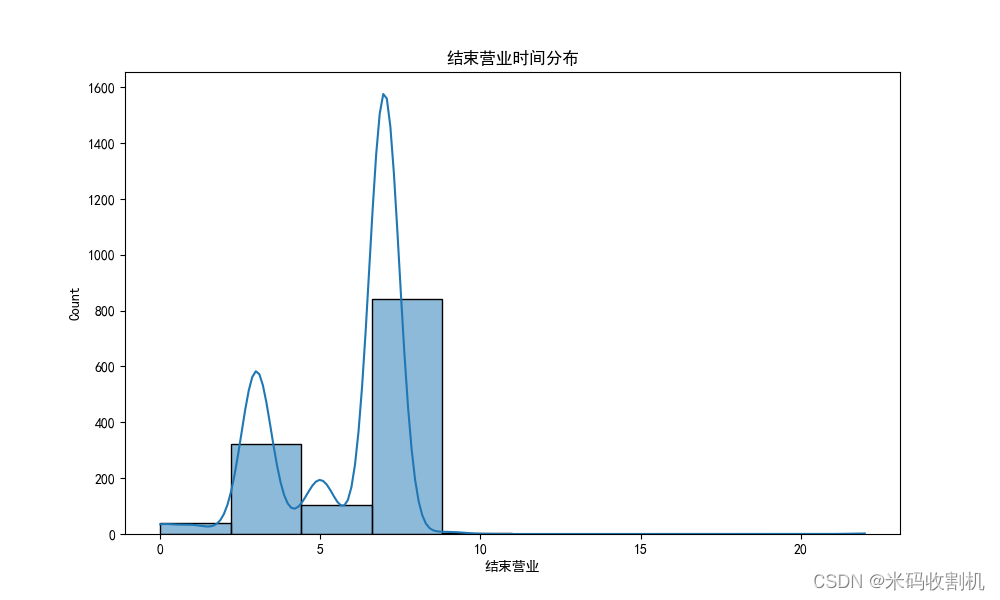
# 结束营业时间分布
# 代码略....
# 代码略....
plt.show()- 可视化数据,展示各省店铺数量分布、营业时长分布、开始营业时间分布和结束营业时间分布。
总结
这段代码通过读取、预览、处理和分析数据,最后进行可视化展示。其设计思路清晰、结构完整,覆盖了数据处理和分析的多个方面,包括缺失值处理、异常值处理、重复值处理、数据转换、数据分组统计和数据可视化。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 " 门店 " 获取。👈👈👈