在测试环境有定时任务会定期将flume采集的数据load到hive表中,在查看yarn application过程中发现load操作没有执行,且后续的任务在上一个任务执行结束后很久才开始。感觉像是阻塞一样,于是手动执行相关脚本,发现也是会卡住,不能正常执行load操作。于是监控相关任务日志,在重新提交命令发现日志报如下问题:

在日志中能大致了解跟锁相关,于是查询相关资料显示:在Hive中,当多个用户同时对同一张表进行读写操作时,可能会出现表被锁定的情况。这意味着其他用户无法对这张表进行写操作,从而导致任务阻塞或失败。为了解决这个问题,Hive提供了一种机制来解除表锁定,即通过使用unlock table命令来释放表锁。
于是在客户端执行如下命令:
bash
show locks;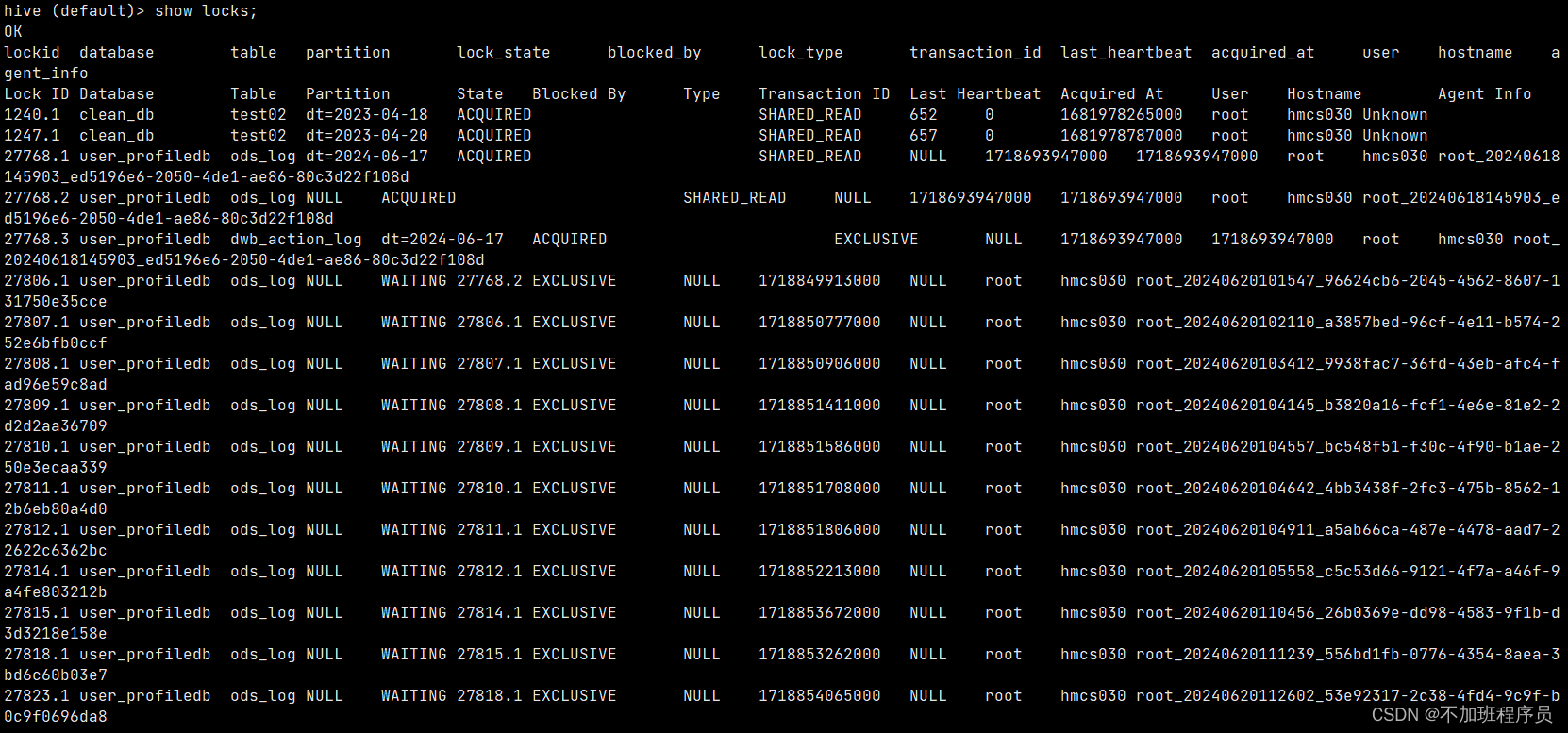
发现有很多事务锁事件存在,于是再进行该表的插入操作时会显示等待,但是目前不需要阻塞,以前的任务可以直接放弃,所以手动执行解锁操作:
bash
unlock table user_profiledb.ods_log;
搜索相关资料显示可以通过修改配置完成于是:
bash
set hive.support.concurrency=false;这个是hive的锁机制,可以暂时关掉,默认是true。关掉之后就可以操作表了,操作之后可以再把它设置为true。但是会有遗留问题,我们会发现那个锁依旧没掉!
这时候需要去执行
bash
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager;然后在进行show locks;时发现已经不存在事务锁了。
问题解决。