 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
- 引言
- Hive架构演进
-
- [Hive on MapReduce](#Hive on MapReduce)
- [Hive on Tez](#Hive on Tez)
- [Hive + LLAP](#Hive + LLAP)
- [Hive on MR3](#Hive on MR3)
- Hive为什么被淘汰
- 总结
引言
从实习开始算,我入行是2021年的事情,不同于之前文章中对于Lakehouse和时序数据库的讨论,事实上我完全不懂Hive,只是公有云买了个实例跑demo,看了几篇论文而已。
机缘巧合,组内有同学正在对比几个OLAP产品的性能,老板点名Hive是其中一个,本着测试之前我们心里需要有一个大致的性能预期,我便浏览了一些Hive相关的资料。在学习之前,我对Hive的印象还停留在大学时学习的老旧资料上:Hive将HiveQL转化为MapReduce作业,基于YARN和HDFS,查询需要启停容器,单行处理,文件格式查询效率低等考古知识。
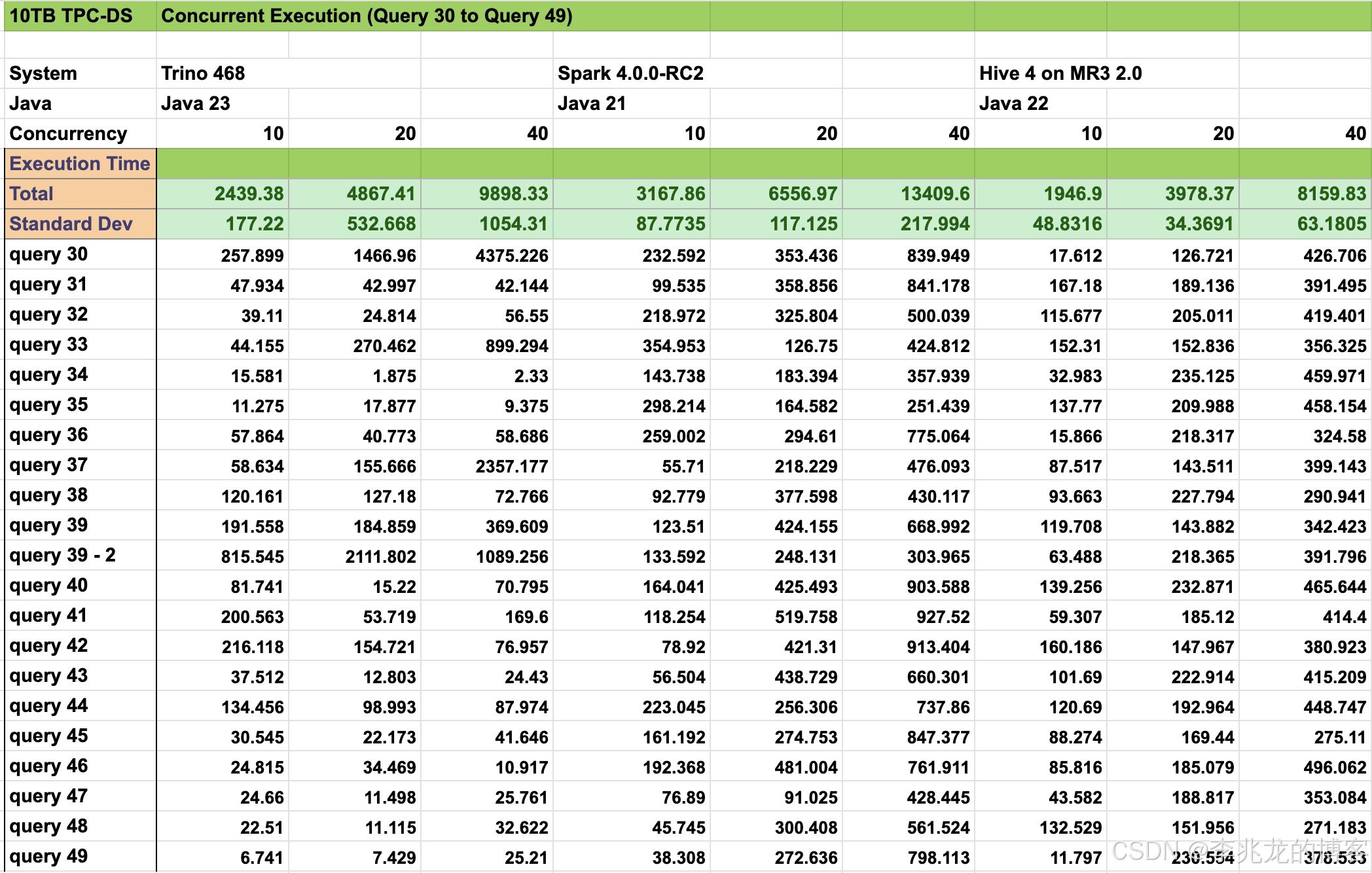
但是随着逐渐的学习,我对Hive有了新的认识,如上图所示,DataMonad开发的Hive on MR3性能在TPC-DS数据集上的表现已经可以媲美Trino,甚至很多场景的表现更优。
Apache Hive 最早是 Facebook 在 2007 年 为了让工程师不用再手写复杂 MapReduce 程序而内部开发的 SQL-on-Hadoop 系统,2008 年开源、2010 年作为 Apache 顶级项目首发,最初基于 MapReduce,主要解决的是"能不能在海量数据上先跑起来离线统计"的问题;
到了 2013 年左右,社区通过 Stinger 计划引入 Hive on Tez,用 DAG 引擎替代引擎的多轮 MapReduce,以解决"批任务能跑但太慢、延迟太高"的问题;
2016 年 Hive 2.0 加入 LLAP,用长驻进程和内存缓存,把 Hive 从纯离线拉向"准实时交互式查询",缓解 BI 场景下高并发小查询的响应问题;
而从 2015 年起开发、在 2020 年前后成熟落地的 MR3 则作为新一代执行引擎接入 Hive,让 Hive 能在 Kubernetes 等环境下运行、复用 worker、提高多租户资源利用率,解决传统 Hadoop 集群下"云原生不友好、调度粗糙"的老问题。
这十几年 Apache Hive 的演进,其实就是一部互联网数据分析架构的史诗。
Hive架构演进
Hive on MapReduce
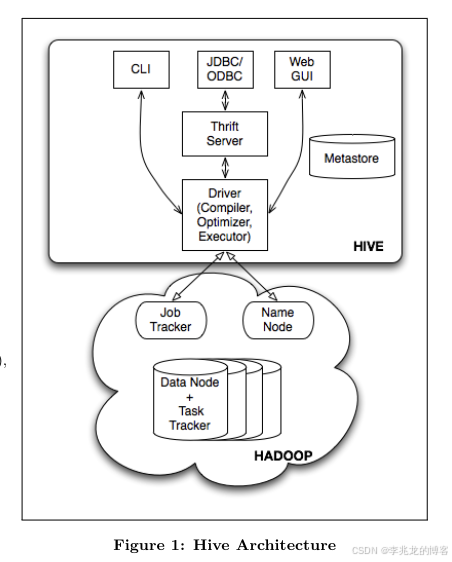
Apache Hive 34 最初基于 Hadoop MapReduce 作为查询执行引擎:用户提交 HiveQL 查询后,Hive 将其解析并翻译为一个或多个 MapReduce 作业,在 YARN 上调度执行,并读取存储在 HDFS 上的表文件。由于每个查询都需启动 MapReduce 容器(JVM),开销巨大,查询延迟往往达到分钟或小时级。
后来基于对现网的观察,发现Hive 在原有文件格式、查询规划和执行机制上暴露出短板,又引入了一系列优化方式2:
- 优化文件格式(ORC File) :针对原有 TextFile、SequenceFile、RCFile 的数据类型无关、压缩效率低、无索引等问题,ORC File 的引入几点关键改进:数据组织:水平分区为条带(默认 256MB,远大于 RCFile 的 4MB),条带内按列存储,支持条带与 HDFS 块边界对齐,减少远程数据读取;数据处理:数据类型感知,支持复杂类型(Array、Map 等)分解为子列,可针对性使用编码 / 压缩方案(如字典编码、ZLIB/Snappy 压缩);
索引支持:包含文件级、条带级、索引组级三级统计索引(最小值、最大值等)和位置指针,减少不必要数据读取;内存管理:引入内存管理器,限制并发写入时的内存占用,避免 OOM。 - 查询规划优化:解决原有规划器忽略操作间关联、产生不必要 Map 阶段 / 数据加载 / 重分区的问题:消除冗余 Map 阶段:将 Map-only 作业合并到子作业,避免中间结果重复加载;关联优化器(Correlation Optimizer):基于 YSmart 研究,识别查询中输入关联(同一表多操作)和作业流关联(操作间分区方式一致),合并多个 MapReduce 作业,减少数据移动和重复加载;算子树重构:通过 DemuxOp(分流)、MuxOp(合流)协调算子执行,确保优化后计划可执行。
- 向量查询执行引擎 :针对原有 "逐行处理" 模型无法适配现代 CPU 架构(并行性、缓存利用率低)的问题:
批处理模式:以 "行批"(默认 1024 行)为单位处理
但是在这一阶段,Hive 还是主要用于大批量批处理和离线 ETL,响应时延高,难以满足交互式分析需求。
Hive on Tez
从 Hive 0.x 到 Hive 1.x 时代,Apache 社区启动 Stinger 计划11,核心目标是用 Apache Tez 替代 MapReduce 引擎,实现DAG 执行以减少作业启动开销并提高并行度。Tez 将一个 HiveQL 查询拆分成多个 Vertex 和 Task,以 DAG 形式在集群中并行运行12。从 MapReduce 迁移到 Tez 并结合列存格式、矢量化执行,能让 Hive 查询性能提升数十倍。Hive on Tez 同时引入了代价模型优化(Cost-Based Optimizer),更智能地生成物理执行计划。
这一系列变化大幅降低了查询延迟,从13可以看到,整体性能有一倍以上的提升:
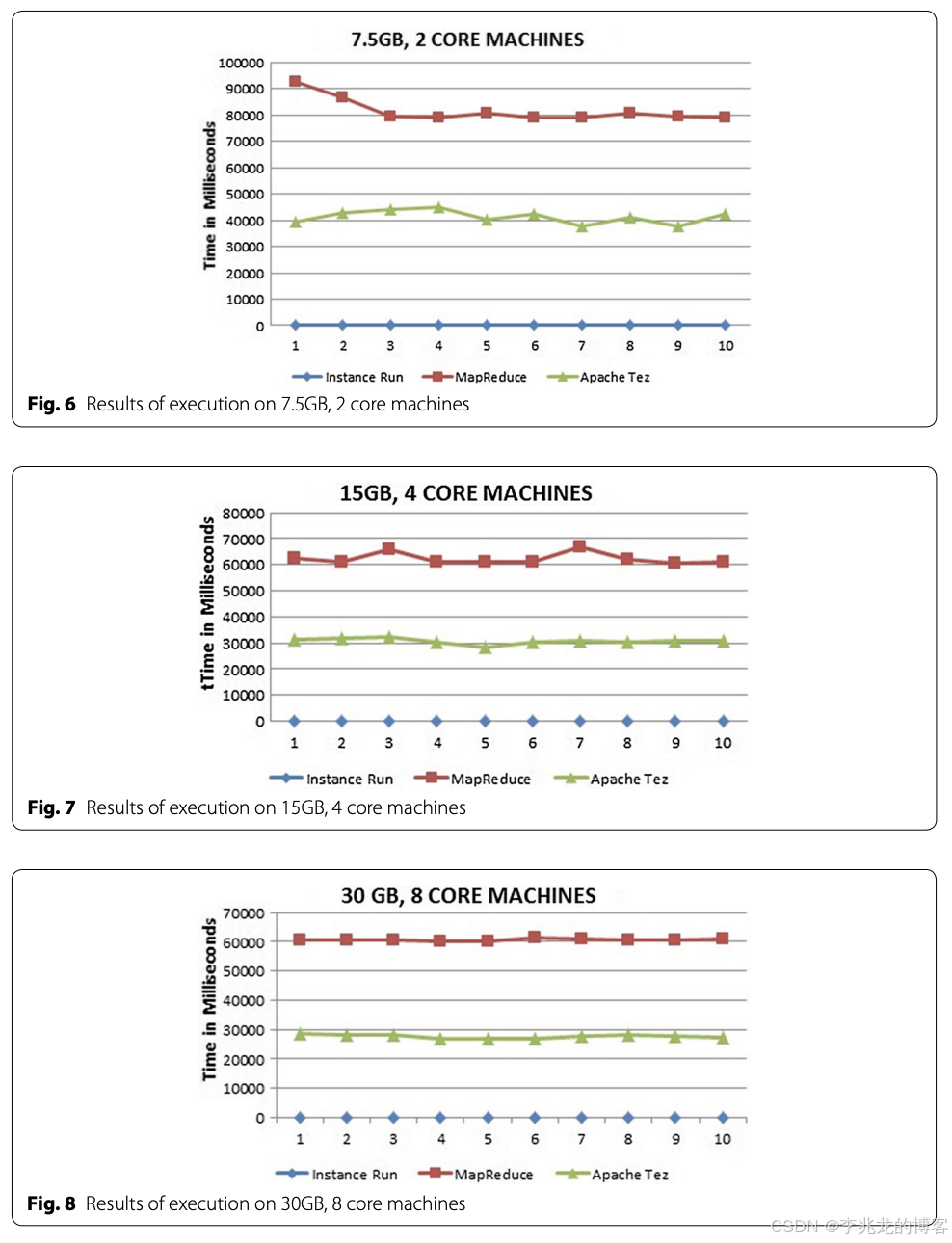
总的来说,Hive on Tez 保留了与 Hadoop 的紧密集成,可在 YARN 环境下执行,但相比 MapReduce 查询响应时延显著降低,吞吐量得到提升。
Hive + LLAP
Hive 3.x 版本引入了 LLAP(Live Long And Process)功能114,面向交互式查询场景。LLAP 在每个工作节点上启动长期驻留的多线程守护进程,负责 I/O、缓存和部分查询执行。
具体来说,LLAP 守护进程提供了异步 I/O、列块预取与缓存、及时编译优化等能力,将小查询直接在内存中处理,减少启动开销。Hive Server 启动查询时,Tez 调用 LLAP 线程执行查询片段,无需每次都申请新容器
。LLAP 模型允许多个查询并发使用缓存数据,显著改善多租户下的响应速度。
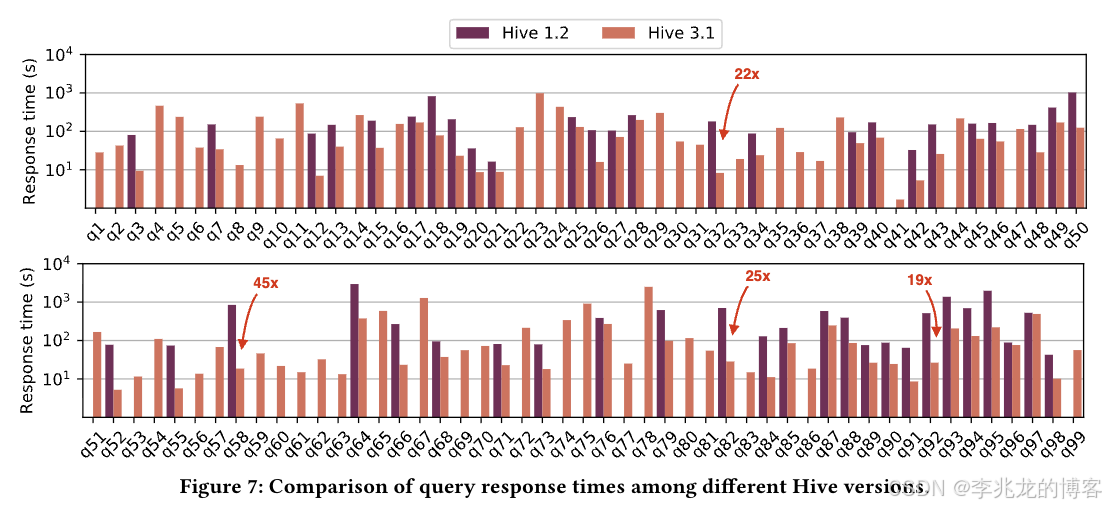
如上所示,TPC-DS的数据集下,LLAP 使 Hive 延迟降低了一个以上的数量级,并提供 ACID事务(Snapshot Isolation )的支持。需要注意的是,LLAP 只是 Hive on Tez 的一个可选增强层(由 YARN 容器粗粒度分配资源),不改变底层存储和元数据模型,只是对执行引擎的优化补充。
Hive on MR3
近年来,Apache Hive 又出现了新的执行选项:Hive on MR3。MR3 是由 DataMonad 开发的执行引擎,可作为替代 Tez 的后端运行 Hive 查询。
在15中提到,在Hive on MR3之前Hive相对于Presto最大的劣势不是性能,而是易于安装。
Hive on MR3在单个进程中统一管理多查询调度、支持 Kubernetes 容器部署,以及内建的容错与弹性伸缩机制。例如,Hive on MR3 可在 Hadoop、Kubernetes 或独立模式运行,无需部署 ZooKeeper 或依赖复杂的 YARN 配置。
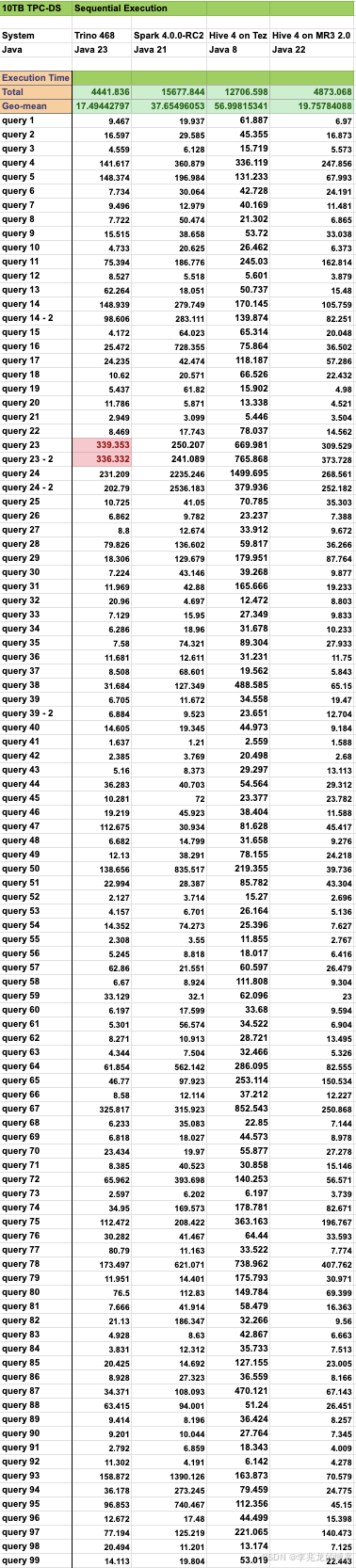
性能方面,5也可以看到TPC-DS下整体性能相当优秀,整体超过Spark和Trino,远超传统 Hive on Tez 的表现。此外,MR3 对并发查询进行了优化:一个 MR3 进程即可同时处理多个 Hive 查询,避免了 LLAP 需要为每查询分配固定线程池的问题。
综上,Hive on MR3 进一步提升了 Hive 的性能和易用性,使其更适合现代容器化和云原生环境。
Hive为什么被淘汰
从时序数据的角度讲,我们见到的很多客户从Hive向时序数据库迁移,理由基本集中在查询性能,实时性,可维护性等方面。
从查询性能的角度讲,可以说现代OLAP在数据布局相同的情况下计算性能很难拉开较大的差距,之前的文章提到过计算引擎组件化(Velox,Apache DataFusion,Apache Calcite,Apache Arrow Acero )已经使得几乎全部大小厂商的分析性能都不会有较大的差距,更多的性能差异在数据布局上。时序数据库可以基于用户的写入查询特征使用Compaction组件持续的修改数据布局,并基于SSD对象存储两级平衡性能和成本,相对通用OLAP有易用性和性能的优势。
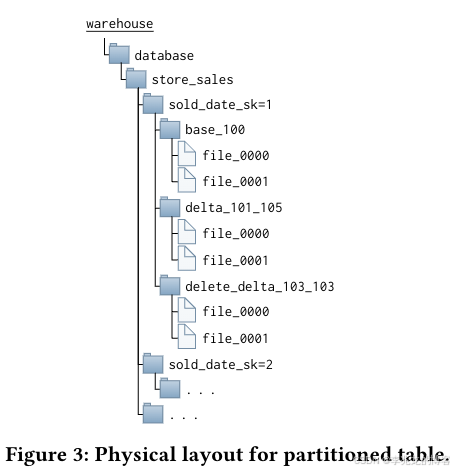
从实时性的角度讲,Hive虽然支持Insert写入单行数据,但是Hive每个事物都会携带全局事务标识符,并写入文件,为了实现快照隔离,HS2在执行查询时会获取需要读取的数据的逻辑快照。该快照由一个事务列表表示,其中包含当时已分配的最高事务ID(即高水位线),以及其下的未完成和已中止事务集,然后合并全部的事务。虽然有Compaction可以合并,但是实时数据查询依旧很慢。
简单来说,虽然Hive支持 ACID 事务,但并不是为了 OLTP 场景设计。可以在一次事务里更新数百万行,但不能支撑每小时数百万个事务,如果业务是每条事件、每次点击都要实时写一条记录,延迟和小文件/compaction 压力都会爆炸。
正如Apache Pimon18诞生的原因:
2023年,Lakehouse架构进行了诸多改进。2020年,阿里云尝试将Apache Flink集成到Apache Iceberg中。Apache Iceberg是一款优秀的Lakehouse格式,它拥有简洁的架构、开放的生态系统和简洁的设计。Apache Flink集成到Apache Iceberg后,Apache Iceberg能够读写Apache Flink中的数据流。我们也向Apache Iceberg社区推广了数据流更新功能。然而,
这种集成也遇到了一些问题。Apache Iceberg是为批处理而设计的,为了适应不同的计算引擎,其简洁的架构必须得以保留。这限制了内核对数据流更新的改进。目前,Apache Flink中的数据无法实时写入Apache Iceberg。我们建议您使用1小时数据更新的服务级别协议(SLA)。
与其他企业一样,阿里云也尝试将Apache Flink与Apache Hudi集成。Apache Hudi是为Spark引入的,是一种增强Spark upsert功能的格式。将 Apache Flink 与 Apache Hudi 集成后,使用 Spark 更新 Apache Hudi 中数据的时间从数小时缩短至 10 分钟。然而,Apache Hudi 是为批处理而设计的,并不适用于流式计算和流式更新。这给未来的架构设计带来了挑战。我们建议您使用 10 分钟的数据更新服务级别协议 (SLA)。
为了解决上述问题,我们设计了一种新的流式数据湖格式------Apache Paimon(原名 Flink Table Store)。Apache Paimon 创新性地结合了湖格式和日志结构合并树 (LSM 树),将实时流式更新引入湖架构。Apache Paimon 可以更好地与 Apache Flink 和 Spark 集成。
由于 Apache Flink 和 Spark 的更佳集成,Apache Paimon 原生支持 Apache Flink 提供的流式处理和 Spark 提供的批处理。Apache Paimon 提供强大的流式读写能力,以及延迟仅为 1 到 5 分钟的流式湖存储。
Hive Streaming Data Ingest也和上述 StreamHouse 有相同的问题,实时性。正如我前两篇文章提到的1920,现代时序数据库可以做到10s秒级别,甚至高吞吐kb级别写入与写入即可见的高效读取,也可以在成本和性能之间做权衡,非常适合于云监控,自定义监控,物联网,车联网,金融,日志等典型时序场景。
正如开头所述,我不懂Hive,所以我在知乎上提了一个问题:为什么Hive正在被淘汰?
让我们一起看看真正运营过Hive的前辈有哪些见解。
写到这里,似乎如何做Hive的性能测试已经有思路了,流式写入数据,等待时序数据库Compaction结束后的分析性查询和实时的点查肯定是性能非常好的,毕竟有一堆索引,缓存和Compact把点查数据聚集在一个RowGroup甚至与一个Page。
总结
机房里的老服务器逐渐退役,
旧集群被归档到只读文档,
在"历史系统"的标题下,
写着简短的一行:
我们曾用 Hive 构建过第一代数据平台。
于是,当夜深人静,
只有风吹过关机的机架,
还隐约带着当年任务队列轰鸣的回声。
若以荷马之笔记录,
Hive 的故事大概会如此收束:
它是最早举起火把的人,
为大数据时代照亮了第一条路;
它经历了从 MapReduce 到 Tez、LLAP、MR3 的锤炼,
一次次试图追上更快、更轻的后辈;
但当世界驶入云原生与湖仓一体的航道,
这位老英雄终究难以再领军冲锋,
更多时候,只是寂静地站在历史时间线的一端,
看着自己当年开辟的道路,
被一代又一代新的引擎踩踏、拓宽。
于是我们一边赞颂:
若无当年之 Hive,何来今日之数据文明?
一边又不免惋惜:
当新的诸神在云端宴饮,
很少有人还记得,
第一盏点亮黑暗机房的火,
是由谁举起。
参考:
- Apache Hive: From MapReduce to Enterprise-grade Big Data Warehousing
- Major Technical Advancements in Apache Hive
- Hive -- A Petabyte Scale Data Warehouse Using Hadoop
- Hive - A Warehousing Solution Over a Map-Reduce Framework
- TPC-DS Benchmark: Trino 468, Spark 4.0.0-RC2, and Hive 4 on MR3 2.0
- Hive on MR3 0.2 vs Hive-LLAP
- Optimizing Query Compilation in Hive 4 on MR3
- COC Asia 2025|得帆云 ETL:顺应 Hive 新特性,重塑数据管道的未来
- Hive 为什么被放弃
- Apache Hive 还有未来吗?
- Stinger Intiative - Making Apache Hive 100 Times Faster
- AWS 什么是 Apache Hive?
- Analyzing performance of Apache Tez and MapReduce with hadoop multinode cluster on Amazon cloud
- Apache Hive : LLAP
- Why you should run Hive on Kubernetes, even in a Hadoop cluster
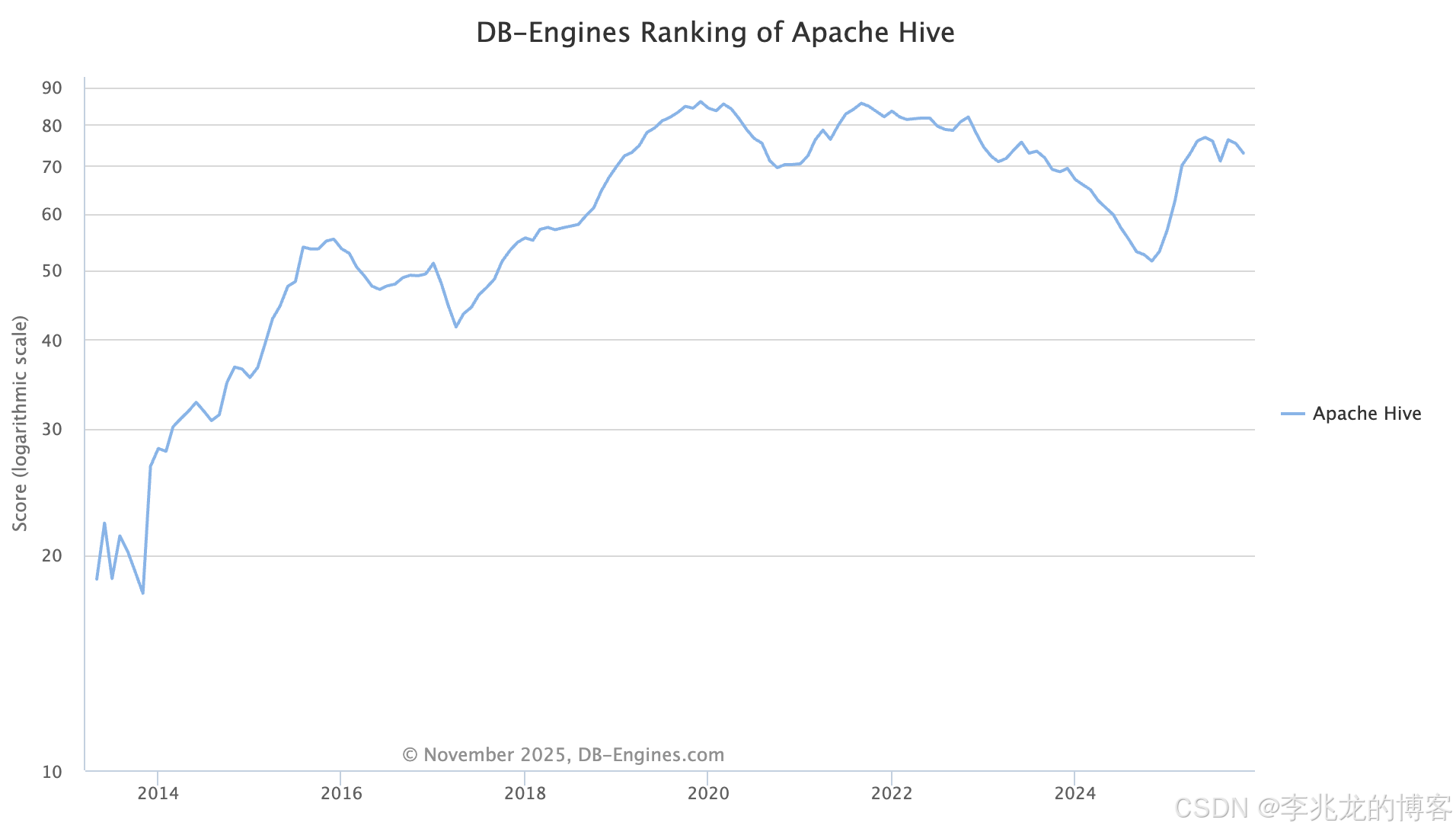
- Apache Hive Trend
- Apache Paimon: Streaming Lakehouse is Coming
- Apache Hive : Streaming Data Ingest
- 从一到无穷大 #60 时序数据库到底有多实时?
- 从一到无穷大 #59 实时OLAP系统到底有多实时?