文章目录
- 前言
- [一、Memory allocator(moderate)](#一、Memory allocator(moderate))
- [二、Buffer cache(hard)](#二、Buffer cache(hard))
- 三、Barrier (moderate)
- 总结
前言
一个本硕双非的小菜鸡,备战24年秋招。打算尝试6.S081,将它的Lab逐一实现,并记录期间心酸历程。
代码下载
官方网站:6.S081官方网站
安装方式:
通过 APT 安装 (Debian/Ubuntu)
确保你的 debian 版本运行的是 "bullseye" 或 "sid"(在 ubuntu 上,这可以通过运行 cat /etc/debian_version 来检查),然后运行:
c
sudo apt-get install git build-essential gdb-multiarch qemu-system-misc gcc-riscv64-linux-gnu binutils-riscv64-linux-gnu ("buster"上的 QEMU 版本太旧了,所以你必须单独获取。
qemu-system-misc 修复
此时此刻,似乎软件包 qemu-system-misc 收到了一个更新,该更新破坏了它与我们内核的兼容性。如果运行 make qemu 并且脚本在 qemu-system-riscv64 -machine virt -bios none -kernel/kernel -m 128M -smp 3 -nographic -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0 之后出现挂起
,
则需要卸载该软件包并安装旧版本:
c
$ sudo apt-get remove qemu-system-misc
$ sudo apt-get install qemu-system-misc=1:4.2-3ubuntu6在 Arch 上安装
c
sudo pacman -S riscv64-linux-gnu-binutils riscv64-linux-gnu-gcc riscv64-linux-gnu-gdb qemu-arch-extra测试您的安装
若要测试安装,应能够检查以下内容:
c
$ riscv64-unknown-elf-gcc --version
riscv64-unknown-elf-gcc (GCC) 10.1.0
...
$ qemu-system-riscv64 --version
QEMU emulator version 5.1.0您还应该能够编译并运行 xv6: 要退出 qemu,请键入:Ctrl-a x。
c
# in the xv6 directory
$ make qemu
# ... lots of output ...
init: starting sh
$在本实验中,您将获得重新设计代码以提高并行性的经验。多核机器上并行性差的一个常见症状是频繁的锁争用。提高并行性通常涉及更改数据结构和锁定策略以减少争用。您将对xv6内存分配器和块缓存执行此操作。
切换分支执行操作
c
git stash
git fetch
git checkout lock
make clean一、Memory allocator(moderate)
程序user/kalloctest.c强调了xv6的内存分配器:三个进程增长和缩小地址空间,导致对kalloc和kfree的多次调用。kalloc和kfree获得kmem.lock。kalloctest打印(作为"#fetch-and-add")在acquire中由于尝试获取另一个内核已经持有的锁而进行的循环迭代次数,如kmem锁和一些其他锁。acquire中的循环迭代次数是锁争用的粗略度量。完成实验前,kalloctest的输出与此类似:
c
$ kalloctest
start test1
test1 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 83375 #acquire() 433015
lock: bcache: #fetch-and-add 0 #acquire() 1260
--- top 5 contended locks:
lock: kmem: #fetch-and-add 83375 #acquire() 433015
lock: proc: #fetch-and-add 23737 #acquire() 130718
lock: virtio_disk: #fetch-and-add 11159 #acquire() 114
lock: proc: #fetch-and-add 5937 #acquire() 130786
lock: proc: #fetch-and-add 4080 #acquire() 130786
tot= 83375
test1 FAIL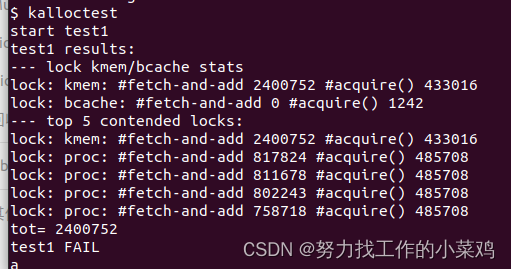
acquire为每个锁维护要获取该锁的acquire调用计数,以及acquire中循环尝试但未能设置锁的次数。kalloctest调用一个系统调用,使内核打印kmem和bcache锁(这是本实验的重点)以及5个最有具竞争的锁的计数。如果存在锁争用,则acquire循环迭代的次数将很大。系统调用返回kmem和bcache锁的循环迭代次数之和。
对于本实验,您必须使用具有多个内核的专用空载机器。如果你使用一台正在做其他事情的机器,kalloctest打印的计数将毫无意义。你可以使用专用的Athena 工作站或你自己的笔记本电脑,但不要使用拨号机。
kalloctest中锁争用的根本原因是kalloc()有一个空闲列表,由一个锁保护。要消除锁争用,您必须重新设计内存分配器,以避免使用单个锁和列表。基本思想是为每个CPU维护一个空闲列表,每个列表都有自己的锁。因为每个CPU将在不同的列表上运行,不同CPU上的分配和释放可以并行运行。主要的挑战将是处理一个CPU的空闲列表为空,而另一个CPU的列表有空闲内存的情况;在这种情况下,一个CPU必须"窃取"另一个CPU空闲列表的一部分。窃取可能会引入锁争用,但这种情况希望不会经常发生。
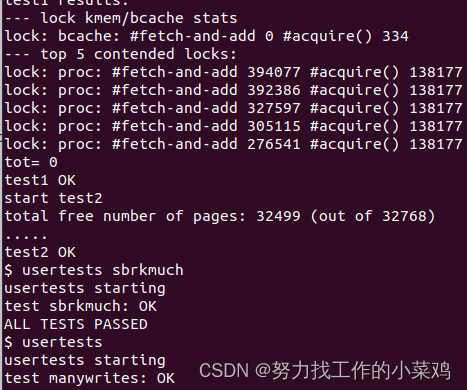
您的工作是实现每个CPU的空闲列表,并在CPU的空闲列表为空时进行窃取。所有锁的命名必须以"kmem"开头。也就是说,您应该为每个锁调用initlock,并传递一个以"kmem"开头的名称。运行kalloctest以查看您的实现是否减少了锁争用。要检查它是否仍然可以分配所有内存,请运行usertests sbrkmuch。您的输出将与下面所示的类似,在kmem锁上的争用总数将大大减少,尽管具体的数字会有所不同。确保usertests中的所有测试都通过。评分应该表明考试通过。
c
$ kalloctest
start test1
test1 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 0 #acquire() 42843
lock: kmem: #fetch-and-add 0 #acquire() 198674
lock: kmem: #fetch-and-add 0 #acquire() 191534
lock: bcache: #fetch-and-add 0 #acquire() 1242
--- top 5 contended locks:
lock: proc: #fetch-and-add 43861 #acquire() 117281
lock: virtio_disk: #fetch-and-add 5347 #acquire() 114
lock: proc: #fetch-and-add 4856 #acquire() 117312
lock: proc: #fetch-and-add 4168 #acquire() 117316
lock: proc: #fetch-and-add 2797 #acquire() 117266
tot= 0
test1 OK
start test2
total free number of pages: 32499 (out of 32768)
.....
test2 OK
$ usertests sbrkmuch
usertests starting
test sbrkmuch: OK
ALL TESTS PASSED
$ usertests
...
ALL TESTS PASSED
$提示:
- 您可以使用kernel/param.h中的常量NCPU
- 让freerange将所有可用内存分配给运行freerange的CPU。
- 函数cpuid返回当前的核心编号,但只有在中断关闭时调用它并使用其结果才是安全的。您应该使用push_off()和pop_off()来关闭和打开中断。
- 看看kernel/sprintf.c中的snprintf函数,了解字符串如何进行格式化。尽管可以将所有锁命名为"kmem"。
解析
有点乱,捋一捋。主要是将锁细粒化,能够按CPU进行划分,如果发现自己的空闲内存没有了,就去占用其他的CPU的空闲内存。
那么首先,先为每一个CPU定义一个数组,数组中存储每个CPU拥有的自己的锁和空闲资源列表。
所以首先我们需要搞一个结构体来存储上下文。因为这是用户级线程,不需要设计用户栈和内核栈,用户页表和内核页表等等切换。
c
//kalloc/kalloc.c
//kernel/param.h中的常量NCPU
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];第二步,为每个锁调用initlock,并传递一个以"kmem"开头的名称。
c
//kalloc/kalloc.c
void
kinit()
{
char lockname[8];
for(int i = 0;i < NCPU; i++) {
snprintf(lockname, sizeof(lockname), "kmem_%d", i);
initlock(&kmem[i].lock, lockname);
}
freerange(end, (void*)PHYSTOP);
}然后修改kfree,使用cpuid()和它返回的结果时必须关中断
c
//kalloc/kalloc.c
void
kfree(void *pa)
{
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
// Fill with junk to catch dangling refs.
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
push_off(); // 关中断
int id = cpuid();
acquire(&kmem[id].lock);
r->next = kmem[id].freelist;
kmem[id].freelist = r;
release(&kmem[id].lock);
pop_off(); //开中断
}最后修改kalloc.c,使得在当前CPU的空闲列表没有可分配内存时窃取其他内存的
c
//kalloc/kalloc.c
void *
kalloc(void)
{
struct run *r;
push_off();// 关中断
int id = cpuid();
acquire(&kmem[id].lock);
r = kmem[id].freelist;
if(r)
kmem[id].freelist = r->next;
else {
int antid; // another id
// 遍历所有CPU的空闲列表
for(antid = 0; antid < NCPU; ++antid) {
if(antid == id)
continue;
acquire(&kmem[antid].lock);
r = kmem[antid].freelist;
if(r) {
kmem[antid].freelist = r->next;
release(&kmem[antid].lock);
break;
}
release(&kmem[antid].lock);
}
}
release(&kmem[id].lock);
pop_off(); //开中断
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}没啥问题
二、Buffer cache(hard)
这一半作业独立于前一半;不管你是否完成了前半部分,你都可以完成这半部分(并通过测试)。
如果多个进程密集地使用文件系统,它们可能会争夺bcache.lock,它保护kernel/bio.c中的磁盘块缓存。bcachetest创建多个进程,这些进程重复读取不同的文件,以便在bcache.lock上生成争用;(在完成本实验之前)其输出如下所示:
c
$ bcachetest
start test0
test0 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 0 #acquire() 33035
lock: bcache: #fetch-and-add 16142 #acquire() 65978
--- top 5 contended locks:
lock: virtio_disk: #fetch-and-add 162870 #acquire() 1188
lock: proc: #fetch-and-add 51936 #acquire() 73732
lock: bcache: #fetch-and-add 16142 #acquire() 65978
lock: uart: #fetch-and-add 7505 #acquire() 117
lock: proc: #fetch-and-add 6937 #acquire() 73420
tot= 16142
test0: FAIL
start test1
test1 OK您可能会看到不同的输出,但bcache锁的acquire循环迭代次数将很高。如果查看kernel/bio.c中的代码,您将看到bcache.lock保护已缓存的块缓冲区的列表、每个块缓冲区中的引用计数(b->refcnt)以及缓存块的标识(b->dev和b->blockno)。
修改块缓存,以便在运行bcachetest时,bcache(buffer cache的缩写)中所有锁的acquire循环迭代次数接近于零。理想情况下,块缓存中涉及的所有锁的计数总和应为零,但只要总和小于500就可以。修改bget和brelse,以便bcache中不同块的并发查找和释放不太可能在锁上发生冲突(例如,不必全部等待bcache.lock)。你必须保护每个块最多缓存一个副本的不变量。完成后,您的输出应该与下面显示的类似(尽管不完全相同)。确保usertests仍然通过。完成后,make grade应该通过所有测试。
c
$ bcachetest
start test0
test0 results:
--- lock kmem/bcache stats
lock: kmem: #fetch-and-add 0 #acquire() 32954
lock: kmem: #fetch-and-add 0 #acquire() 75
lock: kmem: #fetch-and-add 0 #acquire() 73
lock: bcache: #fetch-and-add 0 #acquire() 85
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4159
lock: bcache.bucket: #fetch-and-add 0 #acquire() 2118
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4274
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4326
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6334
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6321
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6704
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6696
lock: bcache.bucket: #fetch-and-add 0 #acquire() 7757
lock: bcache.bucket: #fetch-and-add 0 #acquire() 6199
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4136
lock: bcache.bucket: #fetch-and-add 0 #acquire() 4136
lock: bcache.bucket: #fetch-and-add 0 #acquire() 2123
--- top 5 contended locks:
lock: virtio_disk: #fetch-and-add 158235 #acquire() 1193
lock: proc: #fetch-and-add 117563 #acquire() 3708493
lock: proc: #fetch-and-add 65921 #acquire() 3710254
lock: proc: #fetch-and-add 44090 #acquire() 3708607
lock: proc: #fetch-and-add 43252 #acquire() 3708521
tot= 128
test0: OK
start test1
test1 OK
$ usertests
...
ALL TESTS PASSED
$请将你所有的锁以"bcache"开头进行命名。也就是说,您应该为每个锁调用initlock,并传递一个以"bcache"开头的名称。
减少块缓存中的争用比kalloc更复杂,因为bcache缓冲区真正的在进程(以及CPU)之间共享。对于kalloc,可以通过给每个CPU设置自己的分配器来消除大部分争用;这对块缓存不起作用。我们建议您使用每个哈希桶都有一个锁的哈希表在缓存中查找块号。
在您的解决方案中,以下是一些存在锁冲突但可以接受的情形:
- 当两个进程同时使用相同的块号时。bcachetest test0始终不会这样做。
- 当两个进程同时在cache中未命中时,需要找到一个未使用的块进行替换。bcachetest test0始终不会这样做。
- 在你用来划分块和锁的方案中某些块可能会发生冲突,当两个进程同时使用冲突的块时。例如,如果两个进程使用的块,其块号散列到哈希表中相同的槽。bcachetest test0可能会执行此操作,具体取决于您的设计,但您应该尝试调整方案的细节以避免冲突(例如,更改哈希表的大小)。
bcachetest的test1使用的块比缓冲区更多,并且执行大量文件系统代码路径。
提示:
- 请阅读xv6手册中对块缓存的描述(第8.1-8.3节)
- 可以使用固定数量的散列桶,而不动态调整哈希表的大小。使用素数个存储桶(例如13)来降低散列冲突的可能性。
- 在哈希表中搜索缓冲区并在找不到缓冲区时为该缓冲区分配条目必须是原子的。
- 删除保存了所有缓冲区的列表(bcache.head等),改为标记上次使用时间的时间戳缓冲区(即使用kernel/trap.c中的ticks)。通过此更改,brelse不需要获取bcache锁,并且bget可以根据时间戳选择最近使用最少的块。
- 可以在bget中串行化回收(即bget中的一部分:当缓存中的查找未命中时,它选择要复用的缓冲区)。
- 在某些情况下,您的解决方案可能需要持有两个锁;例如,在回收过程中,您可能需要持有bcache锁和每个bucket(散列桶)一个锁。确保避免死锁。
- 替换块时,您可能会将struct buf从一个bucket移动到另一个bucket,因为新块散列到不同的bucket。您可能会遇到一个棘手的情况:新块可能会散列到与旧块相同的bucket中。在这种情况下,请确保避免死锁。
- 一些调试技巧:实现bucket锁,但将全局bcache.lock的acquire/release保留在bget的开头/结尾,以串行化代码。一旦您确定它在没有竞争条件的情况下是正确的,请移除全局锁并处理并发性问题。您还可以运行make CPUS=1 qemu以使用一个内核进行测试。
解析:
真的麻烦的一道题,看了好几遍才大概懂这题是什么意思。
主要是块缓存之前是由一个大锁bcache.lock保护,所以当多进程在密集地使用文件系统会高频次访问这个缓存区,因此这里的锁被 accquire的次数会非常多。
解决的办法是将将整个缓存区用哈希桶分块,然后对每个块进行上锁与解锁,这样访问其中一个缓存块就不会把整个缓存区都锁上了,可以提升并行运行效率。
首先定义哈希桶结构,并在bcache中删除全局缓冲区链表,改为使用素数个散列桶
c
//kalloc/bio.c
#define NBUCKET 13 //哈希表的桶数量
#define HASH(id) (id % NBUCKET) //计算得到哈希表中相应桶的索引
struct hashbuf {
struct buf head; //头节点
struct spinlock lock; //锁
};
struct {
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// Sorted by how recently the buffer was used.
// head.next is most recent, head.prev is least.
struct hashbuf buckets[NBUCKET]; // 散列桶
} bcache;这个NBUCKET为5。也就是有五个散列桶
所以需要队插入操作上锁,来使得每次插入只有一个进程使用。
看源代码notxv6/ph.c中一共有五个散列桶,那就来五个
c
// notxv6/ph.c
pthread_mutex_t lock[NBUCKET];然后在put函数与get函数中添加上锁与解锁语句
c
// notxv6/ph.c
static
void put(int key, int value)
{
int i = key % NBUCKET;
pthread_mutex_lock(&lock[i]);
// is the key already present?
struct entry *e = 0;
for (e = table[i]; e != 0; e = e->next) {
if (e->key == key)
break;
}
if(e){
// update the existing key.
e->value = value;
} else {
// the new is new.
insert(key, value, &table[i], table[i]);
}
pthread_mutex_unlock(&lock[i]);
}
static struct entry*
get(int key)
{
int i = key % NBUCKET;
pthread_mutex_lock(&lock[i]);
struct entry *e = 0;
for (e = table[i]; e != 0; e = e->next) {
if (e->key == key) break;
}
pthread_mutex_unlock(&lock[i]);
return e;
}最后记得在main函数中初始化
c
......
// notxv6/ph.c
int
main(int argc, char *argv[])
{
pthread_t *tha;
void *value;
double t1, t0;
for (int i = 0; i < NBUCKET; i++) {
pthread_mutex_init(&lock[i], NULL);
}
......很简单

三、Barrier (moderate)
在本作业中,您将实现一个屏障(Barrier):应用程序中的一个点,所有参与的线程在此点上必须等待,直到所有其他参与线程也达到该点。您将使用pthread条件变量,这是一种序列协调技术,类似于xv6的sleep和wakeup。
您应该在真正的计算机(不是xv6,不是qemu)上完成此任务。
文件notxv6/barrier.c包含一个残缺的屏障实现。
c
$ make barrier
$ ./barrier 2
barrier: notxv6/barrier.c:42: thread: Assertion `i == t' failed.2指定在屏障上同步的线程数(barrier.c中的nthread)。每个线程执行一个循环。在每次循环迭代中,线程都会调用barrier(),然后以随机微秒数休眠。如果一个线程在另一个线程到达屏障之前离开屏障将触发断言(assert)。期望的行为是每个线程在barrier()中阻塞,直到nthreads的所有线程都调用了barrier()。
您的目标是实现期望的屏障行为。除了在ph作业中看到的lock原语外,还需要以下新的pthread原语;详情请看这里和这里。
确保您的方案通过make grade的barrier测试。
pthread_cond_wait在调用时释放mutex,并在返回前重新获取mutex。
我们已经为您提供了barrier_init()。您的工作是实现barrier(),这样panic就不会发生。我们为您定义了struct barrier;它的字段供您使用。
有两个问题使您的任务变得复杂:
- 你必须处理一系列的barrier调用,我们称每一连串的调用为一轮(round)。bstate.round记录当前轮数。每次当所有线程都到达屏障时,都应增加bstate.round。
- 您必须处理这样的情况:一个线程在其他线程退出barrier之前进入了下一轮循环。特别是,您在前后两轮中重复使用bstate.nthread变量。确保在前一轮仍在使用bstate.nthread时,离开barrier并循环运行的线程不会增加bstate.nthread。
使用一个、两个和两个以上的线程测试代码。
解析:
这个实验的意思就是添加一个同步节点。当所有进程都到达了这个节点就唤醒所有进程继续执行,没全到就到达的进程会被休眠。
最主要的是这个给出的结构体
c
// notxv6/barrier.c
struct barrier {
pthread_mutex_t barrier_mutex; //互斥锁,用于保护共享资源的访问,确保在修改共享数据时只有一个线程可以访问
pthread_cond_t barrier_cond; //一个条件变量,用于线程间的同步。当一个线程到达障碍物时,如果其他线程还没有到达,它会在这个条件变量上等待
int nthread; // Number of threads that have reached this round of the barrier
//这个整数变量记录了已经到达当前轮次障碍物的线程数量。当这个数量等于参与同步的线程总数时,所有线程都到达了障碍物
int round; // Barrier round
//这个整数变量用于跟踪障碍物的轮次。每次所有线程都到达障碍物时,round 会增加,表示进入下一轮
} bstate;则:
c
// notxv6/barrier.c
static void
barrier()
{
// YOUR CODE HERE
//
// Block until all threads have called barrier() and
// then increment bstate.round.
//
pthread_mutex_lock(&bstate.barrier_mutex); //上锁
bstate.nthread++;
if (bstate.nthread == nthread) {
bstate.round++; //增加 round 的值
bstate.nthread = 0; //重置 nthread
pthread_cond_broadcast(&bstate.barrier_cond); //唤醒所有等待的线程
} else {
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex); //在cond上进入睡眠,释放锁mutex
}
pthread_mutex_unlock(&bstate.barrier_mutex); //解锁
}比较简单的

总结
这个实验主要是关于进程的使用,感觉意犹未尽,比起前面的确实是难度不高。