题目:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
来源: ICLR 2022
模型名称: LoRA
论文链接: https://arxiv.org/abs/2106.09685
项目链接: https://github.com/microsoft/LoRA
文章目录
- 摘要
- 引言
- 问题定义
- 现有方法的问题
- 方法
-
- [将 LORA 应用于 Transformer](#将 LORA 应用于 Transformer)
- 实验
- 思考
- 结论
- [future work](#future work)
摘要
随着模型越来越大,全量微调变得越来越不可行。作者提出了低秩适配器(LoRA),它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层中,大大减少了下游任务的可训练参数的数量。在GPT-3 175B使用Adam上,与全量微调相比,LoRA减少了10,000倍参数量,减少了3倍GPU内存消耗。
🧐与Adapter相比,没有额外的推理延迟
引言
由于全量微调大模型比较不现实,因此除了每个任务的预训练模型之外,只需要存储和加载少量特定于任务的参数,大大提高了部署时的运行效率。
已有的方法引进了推理延迟,要么增加了模型的深度,要么减少了模型可以输入的序列长度,更重要的是,这些方法通常无法匹配微调基线,从而在效率和模型质量之间进行权衡。【adpter增加了深度,pormpt、prefix-tuning减少了模型可以接受的输入序列长度】
🧐We take inspiration from Li et al. (2018a); Aghajanyan et al. (2020) which show that the learned over-parametrized models in fact reside on a low intrinsic dimension. We hypothesize that the change in weights during model adaptation also has a low "intrinsic rank", leading to our proposed Low-Rank Adaptation (LoRA) approach.
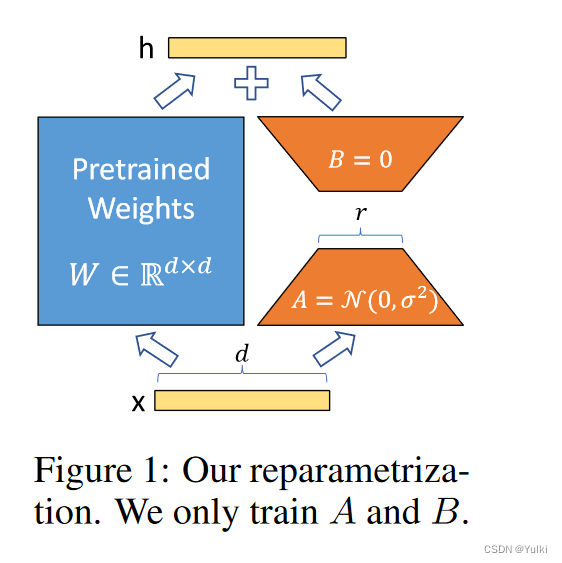
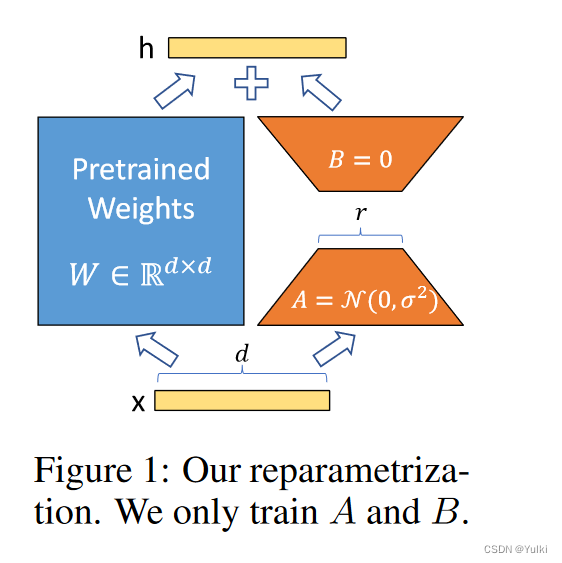
r = 1 or 2 d可以等于12,288
LoRA几个优势:
- 【基础模型不动,只修改A或者B】预训练模型可以共享并用于构建许多用于不同任务的小型 LoRA 模块。我们可以通过替换图1中的矩阵A和B来冻结共享模型并有效地切换任务,从而显着降低存储需求和任务切换开销。
- 【训练更高效】LoRA 使训练更加高效,并将硬件进入门槛降低了多达 3 倍,因为我们不需要计算梯度或维护大多数参数的优化器状态。相反,我们只优化注入的、小得多的低秩矩阵。
- 【推理更加高效】我们简单的线性设计使我们能够在部署时将可训练矩阵与冻结权重合并,通过构造,与完全微调的模型相比,不会引入推理延迟。
- 【可以与别的方法一起使用】LoRA 与许多现有方法正交,并且可以与其中许多方法相结合,例如前缀调整。
问题定义
下面是对语言建模问题的简要描述,特别是在给定特定任务提示的情况下条件概率的最大化。
预训练好的模型: P Φ ( y ∣ x ) P_Φ(y|x) PΦ(y∣x)
下游数据集: Z = { ( x i , y i ) } i = 1 , ... , N \mathcal{Z}=\{(x_i,y_i)\}_{i=1,\ldots,N} Z={(xi,yi)}i=1,...,N
全量微调中优化目标: max Φ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( P Φ ( y t ∣ x , y < t ) ) \max\limits_{\Phi}\sum_{(x,y)\in\mathcal{Z}}\sum_{t=1}^{|y|}\log\left(P_{\Phi}(y_t|x,y_{<t})\right) Φmax∑(x,y)∈Z∑t=1∣y∣log(PΦ(yt∣x,y<t))
LoRA优化目标: max Θ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( p Φ 0 + Δ Φ ( Θ ) ( y t ∣ x , y < t ) ) \max\limits_{\Theta}\sum_{(x,y)\in\mathcal{Z}}\sum\limits_{t=1}^{|y|}\log\left(p_{\Phi_0+\Delta\Phi(\Theta)}(y_t|x,y_{<t})\right) Θmax∑(x,y)∈Zt=1∑∣y∣log(pΦ0+ΔΦ(Θ)(yt∣x,y<t))
当预训练模型为GPT-3 175B时,可训练参数个数| θ ∣ θ| θ∣可小至 ∣ Φ 0 ∣ |Φ_0| ∣Φ0∣ 的 0.01%。
现有方法的问题
增加adapter层,对现有的输入层的结构进行调整
**adapter层引入推理延迟。**虽然可以通过修剪层或利用多任务设置来减少总体延迟(,但没有直接的方法可以绕过适配器层中的额外计算。这似乎不是问题,因为适配器层被设计为具有很少的参数(有时<原始模型的 1%),并且具有小的瓶颈尺寸,这限制了它们可以添加的 FLOPs。然而,大型神经网络依赖硬件并行性来保持低延迟,并且适配器层必须按顺序处理。这对在线推理设置产生了影响,其中批量大小通常小至 1。
直接优化Prompt很难。 我们观察到prefix tuning很难优化,并且其性能在可训练参数中非单调变化,证实了原始论文中的类似观察结果。更重要的是,缩短了可以训练的长度。

方法
动机:矩阵大部分都是满秩的,当适应特定任务时,预训练的语言模型具有较低的"内在维度",尽管随机投影到较小的子空间,但仍然可以有效地学习。
【重要的图不能只看一遍】
前向传播
h = W 0 x + Δ W x = W 0 x + B A x h=W_0x+\Delta Wx=W_0x+BAx h=W0x+ΔWx=W0x+BAx
B ∈ R d × r B\in\mathbb{R}^{d\times r} B∈Rd×r , A ∈ R r × k A\in\mathbb{R}^{r\times k} A∈Rr×k, r < < m i n ( d , k ) r<<min(d,k) r<<min(d,k),在进行微调的时候 W 0 W_0 W0冻结,仅训练 Δ W ΔW ΔW
全量微调的推广
我们通过将LoRA等级r设置为预训练权重矩阵的等级来粗略地恢复完全微调的表现力。
无额外推理延迟
对于不同的任务,只是需要不同的BA罢了。 W = W 0 + B A W = W_0 + BA W=W0+BA
将 LORA 应用于 Transformer
这里只是考虑了将LoRA方法应用到Transformer中的注意力权重计算上,没有应用到其他层。
We leave the empirical investigation of adapting the MLP layers, LayerNorm layers, and biases to a future work.
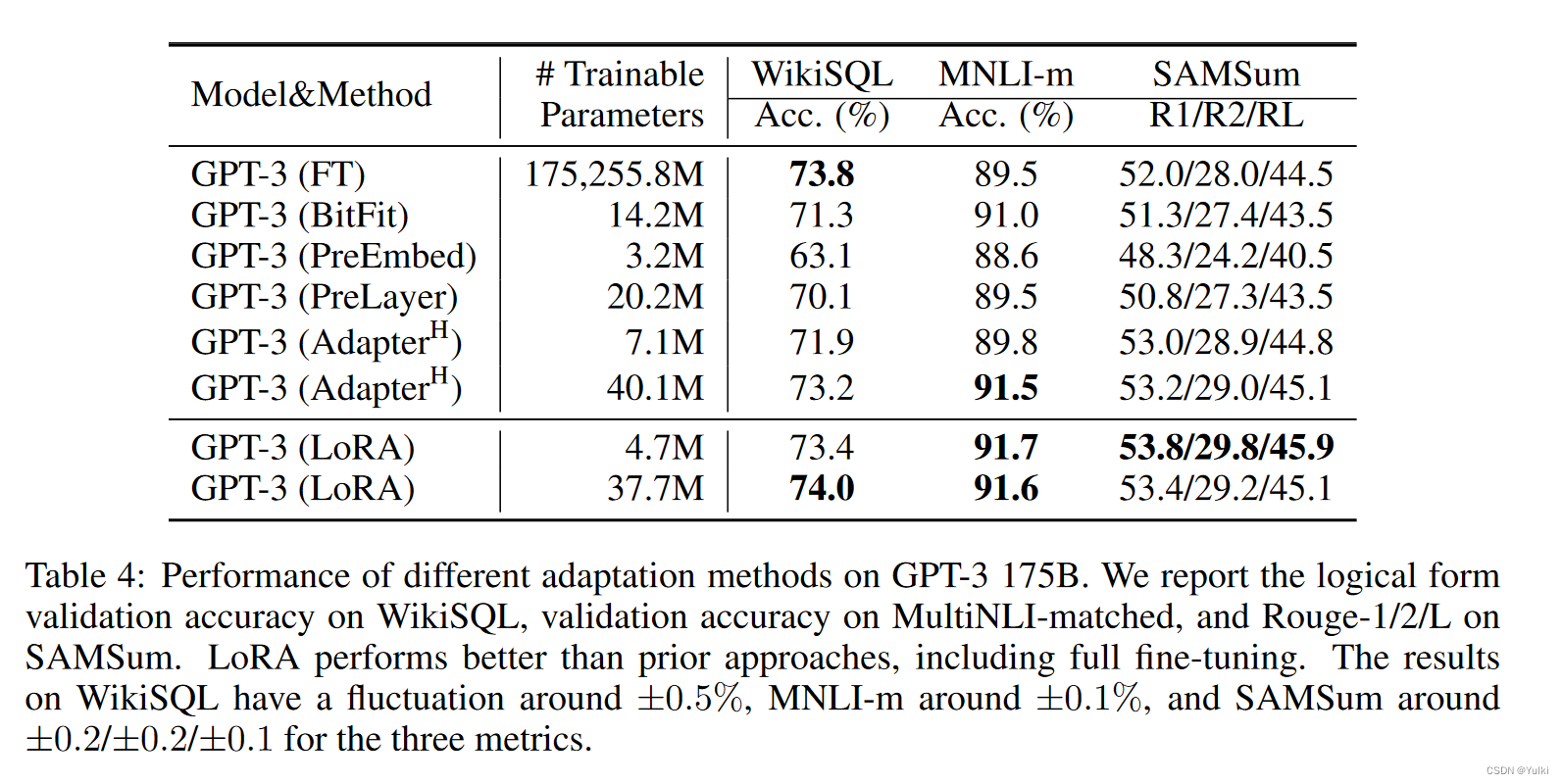
对于GPT-3 175B来哦说,VRAM从1.2TB减少到350GB,r=4的时候,checkpoint的大小从350GB减小到35MB
LoRA 也有其局限性。例如,如果选择将 A 和 B 吸收到 W 中以消除额外的推理延迟,**那么在一次前向传递中将不同 A 和 B 的不同任务的输入批量输入并不简单。**尽管在延迟不重要的情况下,可以不合并权重并动态选择用于批量样本的 LoRA 模块。
实验
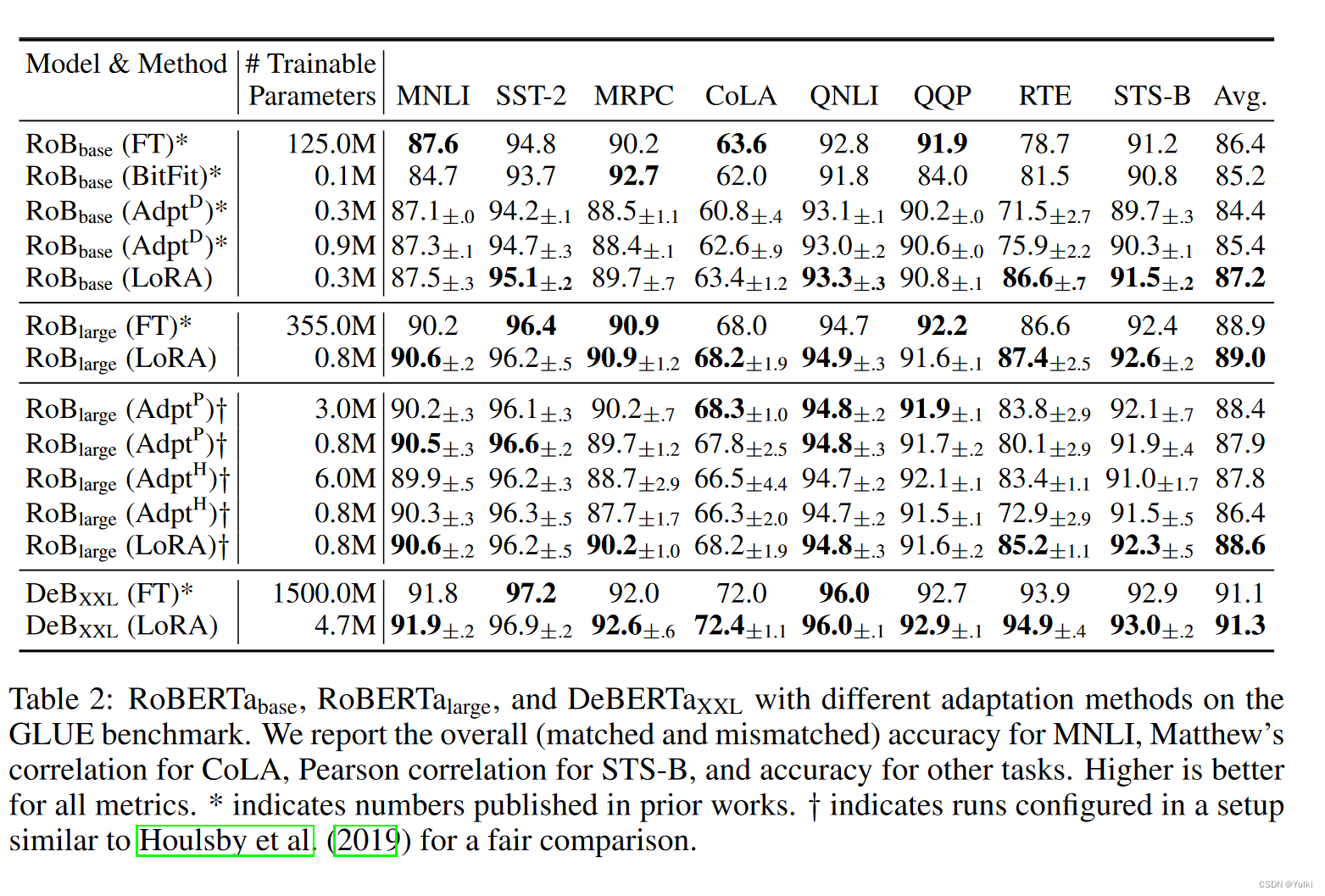
AdapterH:有两个完全连接的层,其中适配器层存在偏差,中间存在非线性。
AdapterL:仅在 MLP 模块和 LayerNorm 之后
LoRA:为了简化实验,只在Wq和Wv上面进行了应用, ∣ Θ ∣ = 2 × L L o R A × d m o d e l × r |Θ| = 2 × L_{LoRA} × d_model × r ∣Θ∣=2×LLoRA×dmodel×r


思考
请注意,低秩结构不仅降低了硬件进入门槛,使我们能够并行运行多个实验,而且还可以更好地解释更新权重与预训练权重的相关性
需要思考一下几个问题:
- 给定参数预算约束,我们应该调整预训练 Transformer 中的哪个权重矩阵子集来最大化下游性能?
- "最优"适应矩阵 ΔW 真的是非满秩的吗?如果是这样,在实践中使用多大的r比较好?
- ΔW 和 W 之间有什么关系? ΔW 与 W 高度相关吗? ΔW 与 W 相比有多大
作者认为对问题(2)和(3)的回答揭示了使用预训练语言模型进行下游任务的基本原则,这是 NLP 的一个关键主题。


后面的实验就没怎么关注,也没看懂
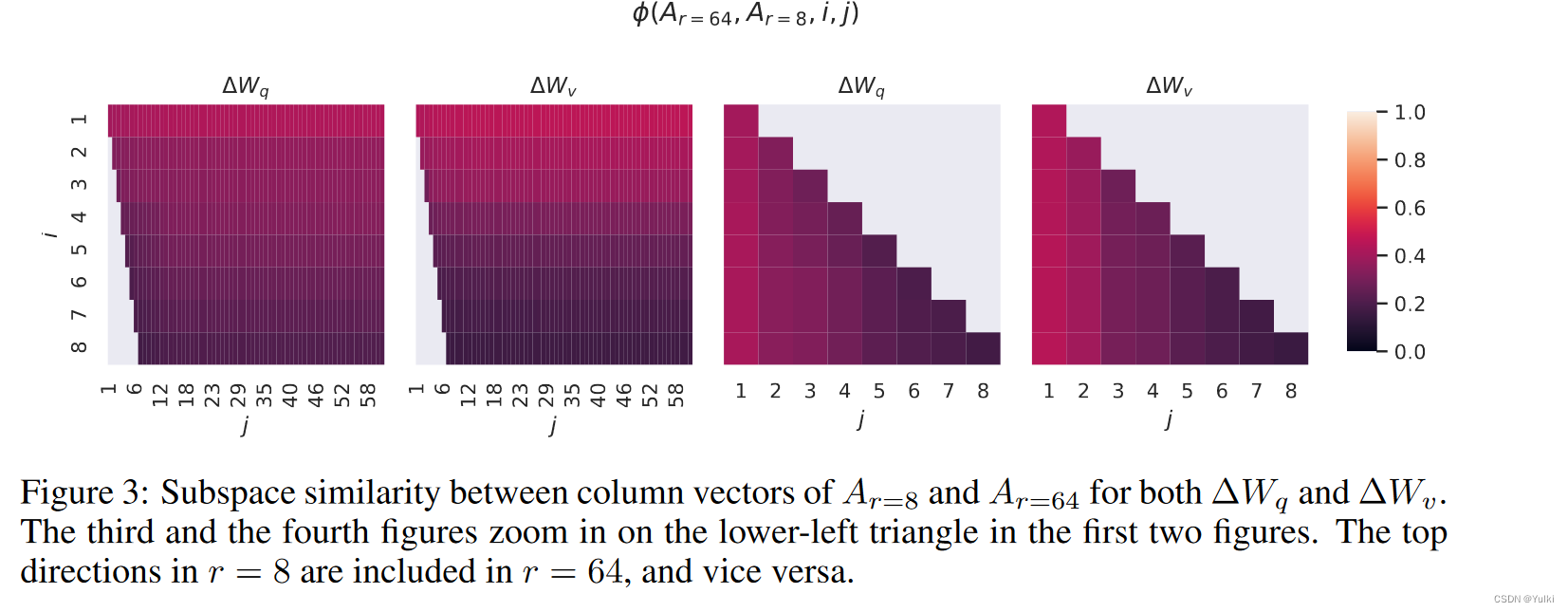


结论
一种有效的适应策略,既不会引入推理延迟,也不会减少输入序列长度,同时保持高模型质量。重要的是,当它部署为服务时,通过共享绝大多数模型参数,可以实现快速任务切换。虽然我们专注于 Transformer 语言模型,但所提出的原理通常适用于任何具有密集层的神经网络。
future work
- Similarly, combining LoRA with other tensor product-based methods could potentially improve its parameter efficiency, which we leave to future work.
- LoRA 可以与其他有效的适应方法相结合,有可能提供正交改进
- 微调或 LoRA 背后的机制尚不清楚------如何将预训练过程中学到的特征转化为在下游任务上表现出色?我们相信 LoRA 比完全微调更容易回答这个问题。
- 我们主要依靠启发式方法来选择应用 LoRA 的权重矩阵。有没有更有原则性的方法来做?
- Finally, the rank-deficiency of ∆W suggests that W could be rank-deficient as well, which can also be a source of inspiration for future works.