一、概念
缓冲区,也称为缓存,是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,用来缓冲输入或输出的数据。这个保留的空间称为缓冲区。
缓冲区的主要作用就是提高效率:
- 提高使用者的效率(将数据交给缓冲区后就认为把数据发完了)
- 提高发送的效率(积累一部分数据后再统一发送(刷新策略:行刷新、全刷新等))
二、刷新方案
缓冲区由于能够暂存数据,必定要有一定的刷新方式:
一般策略:
- 无缓冲(立即刷新)
- 行缓冲(行刷新)
- 全缓冲(缓冲区满了,再刷新)
- ······
特殊情况:
- 强制刷新
- 进程退出时,一般需要进行刷新缓冲区
注:
一般对于显示器文件,我们的缓冲策略是行缓冲(行刷新)。
一般对于磁盘上的文件,我们的缓冲策略是全缓冲(缓冲写满,再刷新)。
三、用户缓冲区(语言级缓冲区)
1.
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
#include<string.h>
int main()
{
printf("C: printf\n");
fprintf(stdout, "C: fprintf\n");
const char* str = "system call: write\n";
write(1, str, strlen(str) );
return 0;
}

2.
我们可以看到,在fork一个子进程后,运行结果就改变了:
对于fork不了解的同学,可以查看该篇博客学习:
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
#include<string.h>
int main()
{
printf("C: printf\n");
fprintf(stdout, "C: fprintf\n");
const char* str = "system call: write\n";
write(1, str, strlen(str) );
fork();
return 0;
}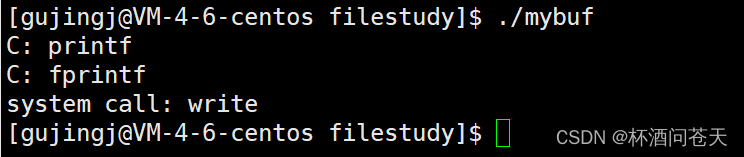
我们知道fork之后的子进程并不会从头开始执行代码,而是从fork时的代码开始执行。那么为什么会出现fork之前的代码的输出语句出现两次的情况呢?
- 当我们直接向显示器打印的时候,显示器文件的刷新方式是行刷新, 而且代码输出的所有字符串都带有"\n",说明数据全部已经被刷新,包括系统调用system call。
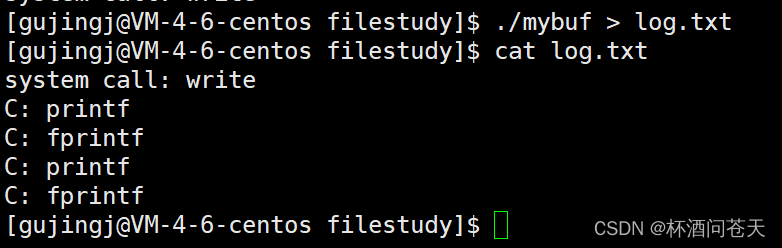
- 当我们进行输出重定向到log.txt,本质是向磁盘文件中写入(而不是显示器),所以我们系统对于数据的刷新方式已经由行刷新变成了全缓冲。
- 全缓冲意味着缓冲区变大,实际写入的数据不足以把缓冲区写满,那么fork执行的时候,数据依旧在缓冲区中。
- 我们所谈的"缓冲区"(用户缓冲区),和操作系统是没有关系的,只和C语言本身有关。我们日常用得最多的其实是C/C++提供的语言级别的缓冲区。
- C/C++提供的缓冲区,里面一定保存的是用户的数据,属于当前进程在运行时自己的数据。如果我们把数据交给了操作系统,那么这个数据就属于操作系统,和进程没关系了。
- 当进程退出时,一般要进行刷新缓冲区,即使数据没有满足刷新条件!
- 刷新缓冲区属于"清空"/"写入"操作,上面的缓冲区是属于进程自己的数据,fork时数据还在,fork后不管是父子进程总有一个进程先退出,则总有一个先刷新,那么就总有一个先进行类似于"清空"或"写入",而父子进程默认情况下数据共享,一方写入则发生写时拷贝 ,所以我们的数据出现了两份。( fork立马退出,任意一个进程在退出的时候,刷新缓冲区,就要发送写时拷贝)
- write系统调用,没有使用C的缓冲区。直接写入到操作系统,不属于进程,不发生写时拷贝。
而从C缓冲区写入操作系统的这个工作叫做刷新。
注:
我们已知:任何情况下,我们输入输出的时候,都要有一个FILE,FILE是一个结构体,FILE里面包含了fd。
如果对fd不了解的同学,可以参考:文件描述符fd
此外,FILE结构体里面也包含了缓冲区。
任何一个文件都要在C标准库中通过FILE来创建一个属于它自己的文件级别的用户级缓冲区。