以下通过案例(根据行为习惯预测年龄)帮助我们深入理解梯度提升决策树(GBDT)的训练过程
假设训练集有4个人(A、B、C、D),他们的年龄分别是14、16、24、26。其中A、B分别是高一和高三学生;C、D分别是应届毕业生和工作两年的员工
下面我们将分别使用回归树和GBDT,通过他们的日常行为习惯(购物、上网等)预测每个人的年龄
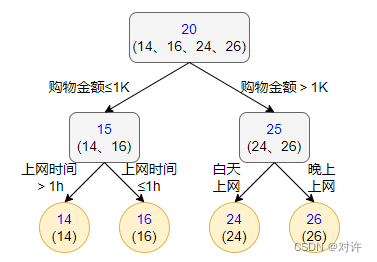
1、使用回归树训练
回归树训练得到的结果如图所示:
2、使用GBDT训练
由于我们的样本数据较少,所以我们限定叶子节点最多为2(即每棵树都只有一个分枝),并且限定树的棵树为2
梯度提升决策树(GBDT)的训练过程如下:
1) 第一棵树:假设初始值为平均年龄20,得到的结果如图所示:
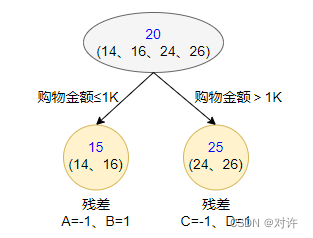
上图中,A、B的购物金额不超过1k,C、D的购物金额超过1k,因此被分为左右两个分支,每个分支使用平均年龄作为预测值
分别计算A、B、C、D的残差(实际值减预测值):
- A残差 = 14 − 15 = − 1 \tt =14-15=-1 =14−15=−1
- B残差 = 16 − 15 = 1 \tt =16-15=1 =16−15=1
- C残差 = 24 − 25 = − 1 \tt =24-25=-1 =24−25=−1
- D残差 = 26 − 25 = 1 \tt =26-25=1 =26−25=1
以A为例,这里A的预测值是指前面所有树预测结果的累加和,当前由于只有一棵树,所以直接是15,其他同理
2) 第二棵树:拟合前一棵树的残差-1、1、-1、1,得到的结果如图所示:
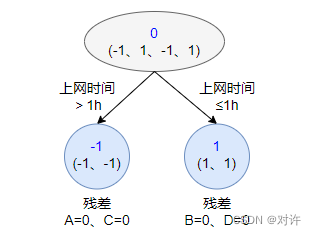
上图中,A、C的上网时间超过1h,B、D的上网时间不超过1h,因此被分为左右两个分支,每个分支使用平均残差作为预测值
分别计算A、B、C、D的残差(实际值减预测值):
- A残差 = − 1 − ( − 1 ) = 0 \tt =-1-(-1)=0 =−1−(−1)=0
- B残差 = 1 − 1 = 0 \tt =1-1=0 =1−1=0
- C残差 = − 1 − ( − 1 ) = 0 \tt =-1-(-1)=0 =−1−(−1)=0
- D残差 = 1 − 1 = 0 \tt =1-1=0 =1−1=0
第二棵树学习第一棵树的残差,在当前这个简单场景下,已经能够保证预测值与实际值(上一轮残差)相等了,此时停止迭代
3) 迭代终止后,最后就是集成,累加所有决策树的预测结果作为最终GBDT的预测结果
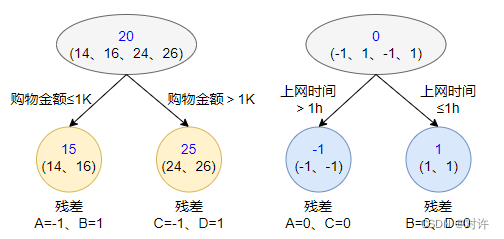
本案例中,我们最终得到GBDT的预测结果为第一棵树的预测结果加第二棵树的预测结果
- A:真实年龄14岁,预测年龄 15 + ( − 1 ) = 14 \tt 15+(-1)=14 15+(−1)=14
- B:真实年龄16岁,预测年龄 15 + 1 = 16 \tt 15+1=16 15+1=16
- C:真实年龄24岁,预测年龄 25 + ( − 1 ) = 24 \tt 25+(-1)=24 25+(−1)=24
- D:真实年龄26岁,预测年龄 25 + 1 = 26 \tt 25+1=26 25+1=26
综上所述,GBDT需要将多棵树的预测结果累加,得到最终的预测结果,且每轮迭代都是在当前树的基础上,增加一棵新树去拟合前一个树预测值与真实值之间的残差