在人工智能的演进历程中,数据和模型的整合是推动技术发展的核心动力。随着AI技术的不断进步,整合各类关键资源,构建一个高效、协同的开发环境,已成为加速创新应用发展的关键。
基于这一理念,OpenDataLab浦数 与ModelScope魔搭社区 开展深度合作,实现平台底层接口打通,支持在ModelScope平台搜索、查看、下载OpenDataLab平台7000+开源数据集,共同开启一场模型与数据的深度融合,旨在为全球开发者打造更加高效、开放的AI体验。
一、两大AI社区强强联合
OpenDataLab 浦数人工智能开放数据平台,是上海人工智能实验室在WAIC 2022科学前沿全体会议上发布"OpenXLab浦源"人工智能开源开放体系的核心项目之一。
作为人工智能数据领域的探路者和开源数据社区的倡导者,OpenDataLab围绕大模型数据开展多项前沿技术探索,构建面向大模型研发全流程的数据平台及大模型时代数据管理体系。
全新的OpenDataLab浦数人工智能开放数据平台汇聚了海量的数据资源,包括覆盖800多种任务类型的7,700多个大模型优质、开源数据集,并提供便捷检索和快速下载服务。
ModelScope魔搭作为中国最具影响力的模型开源社区,链接了国内外最优秀的开发者群体,并成为国内外大模型开源的首发平台。围绕平台上开源的5,000多个优质模型,ModelScope通过自身完整的技术体系,服务了超过500万的AI开发者。
你将获得这些新体验:
01 一站式开发体验
ModelScope社区作为领先的模型开源平台,汇聚了丰富的行业模型和大规模预训练。而OpenDatalab以其高质量、多样化的数据集闻名,此次合作将实现模型与数据的无缝对接,为开发者提供从数据获取、模型训练到部署应用的一站式解决方案,极大提升开发效率。
02 增强的创新能力
结合ModelScope社区的领先的模型和OpenDatalab的广泛数据集,开发者可以轻松尝试更多的预训练,微调等模型算法,快速验证模型的效果,以及推动模型落地千行百业,降低创新门槛,加速从想法到产品的转化过程。
二、如何在魔搭社区使用OpenDataLab数据集
01 下载和加载OpenDataLab数据集
OpenDataLab和ModelScope社区在底层数据存储和交换链路、数据集meta信息表征、数据展现、ToolKit等几个技术层面,实现了互联互通;用户可以在ModelScope社区使用git和sdk的方式,来下载从OpenDataLab迁移过来的数据;同时,对于部分大型数据集,OpenDataLab提供了数据meta信息、数据下载接口,在ModelScope平台上透出。
总的来说,用户可以通过以下三种方式来下载和使用OpenDataLab的数据集:
● 使用git来下载和管理数据集
我们以LAMM数据集为例,其数据卡片参考:*https://modelscope.cn/datasets/Shanghai_AI_Laboratory/LAMM/summary*,
使用git命令,来实现数据文件的下载和版本管理:
GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/datasets/Shanghai_AI_Laboratory/LAMM.git
git lfs pull(左右滑动,查看全部)
● 使用sdk加载数据
对于符合ModelScope数据集组织结构规范的OpenDataLab数据集,我们也可以使用ModelScope SDK的MsDataset模块来加载数据集,具体使用方式:
# Install modelscopepip install modelscope# Load & manage datasetfrom modelscope.msdatasets import MsDatasetds = MsDataset.load('Shanghai_AI_Laboratory/LAMM')此时,数据集被下载到本地缓存,数据被组织为不同的subset、split(如train、test、validation),支持对ds对象(通常为DatasetDict或Dataset格式)的遍历、filter、map等操作。
● 使用OpenDataLab原生的数据集下载工具
在此种模式下,OpenDataLab数据集的元信息、数据卡片、数据标签等内容会托管在ModelScope平台,而底层真实的数据扔存储在OpenDataLab上,此时可通过OpenXLab命令实现数据集的下载操作:
# Install openxlabpip install openxlab# Download datasetopenxlab dataset download --dataset-repo <dataset-repo>三、使用OpenDataLab数据集微调模型
当OpenDataLab数据集可以使用ModelScope sdk加载时,即可以使用ModelScope SWIFT高效微调工具来训练你的模型。以LAMM数据集为例:
● 训练环境准备
pip install modelscope -Upip install ms-swift -U这里我们使用LAMM多模态数据集来微调GLM4-V模型,即glm4v-9b-chat;微调框架为ModelScope SWIFT。以下是具体步骤:
获取代码
git clone git@github.com:modelscope/swift.git
数据准备
由于LAMM并未集成到SWIFT数据集中,这里我们走自定义形式。将LAMM数据配置加入到SWIFT dataset_info.json中:
编辑s wift/llm/data/dataset_info.json
"opendatalab-LAMM": { "dataset_id": "Shanghai_AI_Laboratory/LAMM", "hf_dataset_id": "", "subsets": ["LAMM_instruct_98k"], "split": ["train"], "conversations": { "user_role": "human", "assistant_role": "gpt", "conversations_key": "conversations", "from_key": "from", "value_key": "value", "error_strategy": "delete", "media_type": "image", "media_key": "image" }, "tags": ["multi-modal"] }● 这里subset 使用了LAMM_instruct_98k
● conversations_key 取LAMM数据集的subset LAMM_instruct_98k 中的conversations字段
配置完成后,执行 pip install -e .
执行训练
# Experimental environment: A100
# 40GB GPU memory
# limit 10000
CUDA_VISIBLE_DEVICES=0 swift sft --model_type glm4v-9b-chat --dataset opendatalab-LAMM#10000train loss
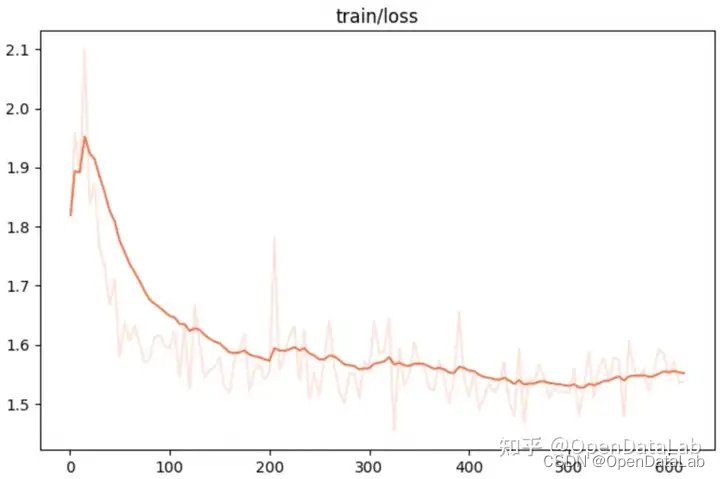
eval acc
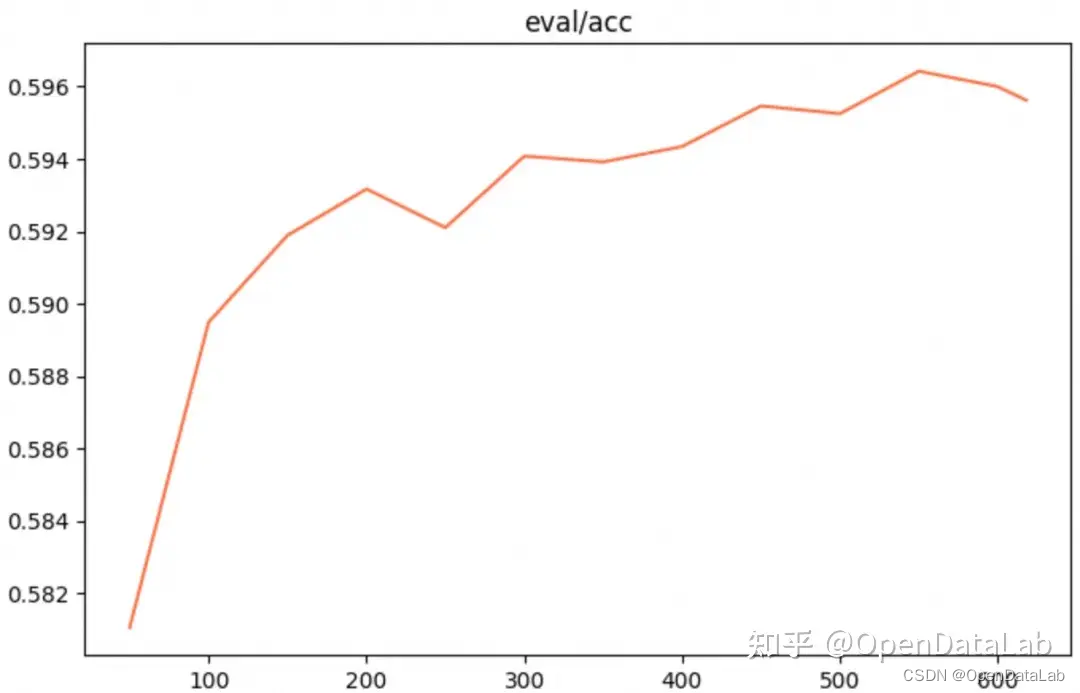
补充说明
OpenDataLab多模态数据集LAMM介绍

LAMM数据集是上海人工智能实验室开源的一个多模态数据集,包括一个包含 186,098 个图像语言指令-响应对的图像指令调整数据集和一个包含 10,262 个点云语言指令-响应对的点云指令调整数据集。 该数据集从公开可用的数据集中收集图像和点云,并使用 GPT API 和自我指导方法根据这些数据集中的原始标签生成指令和响应。 该数据有以下特性:
● 添加了更多视觉信息,例如视觉关系和细粒度类别作为 GPT API 的输入
● 观察到现有的 MLLM 可能难以理解视觉任务指令。 为了解决这个问题,设计了一种将视觉任务注释转换为指令-响应对的方法,从而增强了 MLLM 对视觉任务指令的理解和泛化
● LAMM-Dataset 还包括用于常识性知识问答的数据对,方法是结合来自 Bamboo 数据集的分层知识图标签系统和相应的维基百科描述。
欢迎大家使用 ,你还有哪些需求或更好的建议,快来OpenDataLab github主页给我们提issue吧