
随着技术的发展,用户对软件的界面美观度和交互体验的要求越来越高。在这样的背景下,可视化开发UI(User Interface)成为了提升用户体验和开发效率的重要工具。
通过图形界面来设计和构建用户界面的方法,可视化开发UI可以说改变了软便开发的生态,与传统的代码编写相比,它允许开发者使用拖放等直观的操作来布局界面元素,而无需编写大量的代码,可以达到提升开发效率、加强团队协作、降低技术门槛、快速响应需求变化,增强用户体验的目的。常见的可视化开发UI工具与技术包括拖放界面构建器、模板和预设、响应式设计、交互式原型,以及代码生成等。
为了更好地满足用户需求,尽可能降低用户的使用难度,白鲸数据集成平台WhaleTunnel给用户提供了一套完善的任务开发、任务管理、任务调度、任务监控的可视化UI。
WhaleTunnel支持可视化DAG开发数据集成作业,并且数据源信息单独管理,不需要在每个作业中重复配置数据库连接地址、数据库用户名、密码等信息。
独立的数据源管理功能
 图1 创建数据来源
图1 创建数据来源
虚拟表管理功能
在WhaleTunnel中,我们统一了同步任务定义的操作规范,Source、Transform、Sink每个任务节点都会显示输入表结构和输出表结构。日常我们在处理如Kafka数据时,由于Kafka中的数据没有schema信息,为了将Kafka中的数据也当成表来处理,同时面对复杂的SaaS数据源,也可以讲SaaS数据源变成虚拟表在后续数据整合中复用并简化操作。
虚拟表管理功能的核心目标是将那些非结构的数据源,通过自定义表结构的方式,抽象成结构化数据,然后在同步任务开发时,可以像那些结构化数据源一样,对数据源中的数据进行字段过滤,字段改名,字段类型映射等操作。 在虚拟表创建时必须指定数据源名称,对于Kafka来说,我们可以在数据源中创建Kafka的数据源,填写Kafka连接地址,topic名称信息。然后创建虚拟表选择前面创建的Kafka数据源,即可针对数据源中的Topic中的数据定义表结构信息。
同步任务数据Mapping开发
WhaleTunnel的同步任务定义是可视化Mapping开发模式。
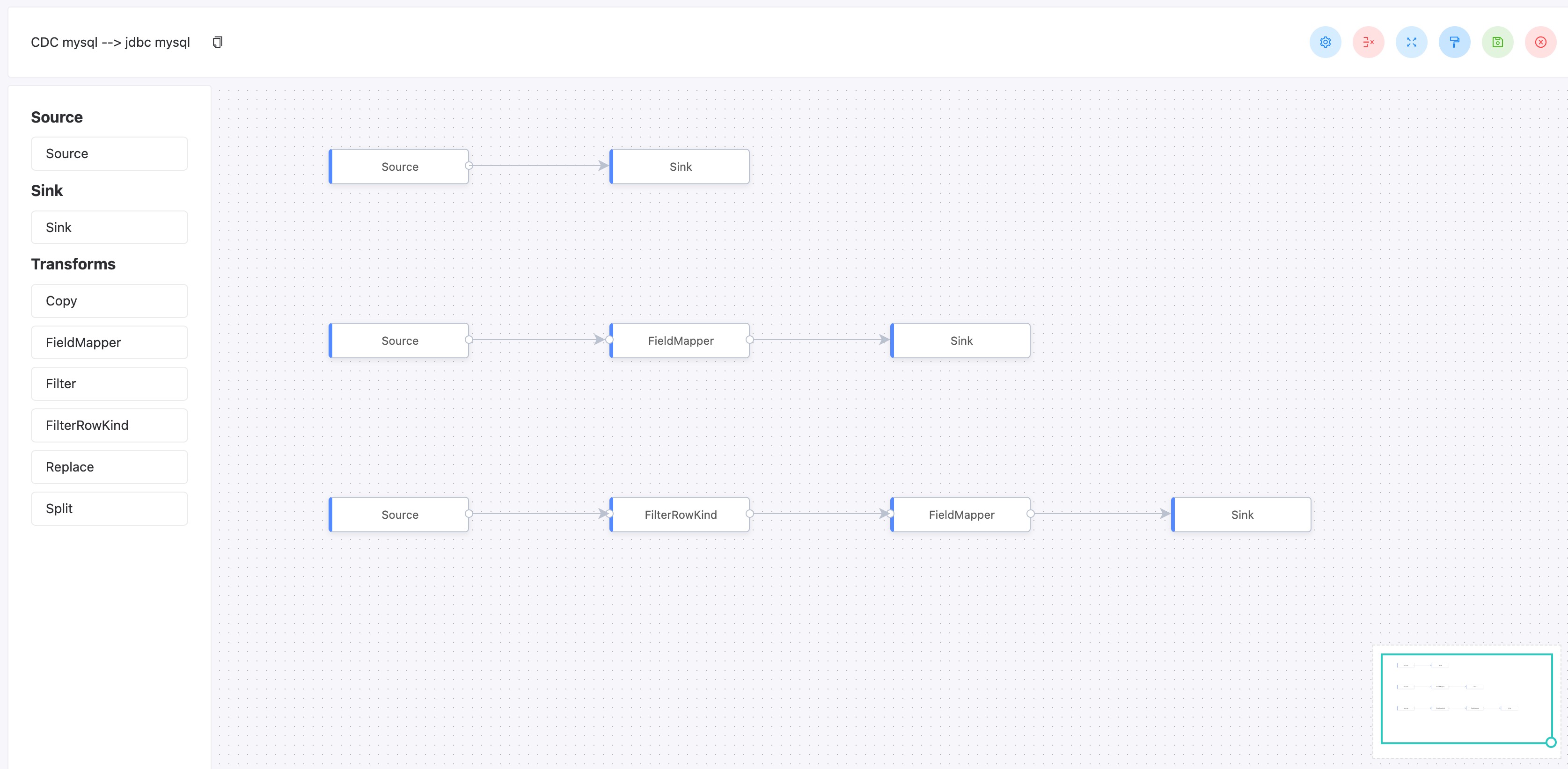 图2 Create Date Pipelines
图2 Create Date Pipelines
全链接监控
WhaleTunnel会监控同步任务的详细信息,目前我们以pipeline为粒度进行汇总并显示到同步任务实例中。通过这些监控信息,用户可以明确了解同步任务读取和写入的数据行数、处理的性能等。
随着人工智能和机器学习技术的发展,未来的可视化开发工具将更加智能,能够根据用户行为和偏好自动优化界面设计。同时,增强现实(AR)和虚拟现实(VR)技术也将为可视化开发带来新的机遇和挑战。随着技术的不断进步,我们期待WhaleTunnel可视化开发UI在未来将发挥更大的作用,为客户的软件开发带来革命性的变化。
本文由 白鲸开源科技 提供发布支持!