一、主函数
官方开源的代码提供了四个主函数,其中eval_pair.cpp和eval_top1.cpp是一组,分别用于计算两帧的相似度分数以及一帧点云在所有的51帧点云中相似度最高的25帧的相似度分数。eval_seq.cpp是在eval_top1.cpp的基础上,给了一堆序列,遍历序列中的每一帧点云并输出与之相似度足够高的25帧点云的相似度分数。eval_angle.cpp这个文件比较迷,readme里面也没有提,代码里面提到的那几个config文件开源代码也没有给出,从代码内容来看,更像是在eval_pair.cpp的基础上,计算了好多帧对的位姿变换。
主函数的具体操作基本都是类似的,先初始化config对象读取配置文件,同时利用这个配置文件初始化ssc对象,之后根据不同的需求,调用重载了许多次的ssc对象里面的getScore函数,进行相似度分数的计算。因此整个ssc算法其实都在ssc对象中实现。
二、ssc.cpp
算法的实现基本都在这个文件中,文件的结构本身不复杂,除了构造函数和析构函数,还有三个形式的读取点云函数、投影函数、计算ssc描述子的函数、两个形式的全局ICP函数、计算相似度的函数以及六个形式的计算相似度分数的函数。
getScore()
根据主函数的执行顺序,这里我们也从getScore函数开始。从重载函数的形式看,六个getScore函数传入的参数本质上都是一样的:两帧点云、两帧点云的语义以及变换矩阵,不同之处在于传入的形式,一二个函数传入的是XYZL形式的点云,这是pcl库中一个点云形式,L表示的是label,相当于直接把语义信息存储了进去,三四个函数这是传入了点云文件的路径和语义推理结果的路径,在函数内部分别读取两个文件,最后两个函数则是直接读取标记过语义的点云文件。从执行的路径来看,最后面四个函数都是在调整文件格式之后,转而调用了前面两个函数,所以这里我们主要看第一个形式的getScore函数。
project()
进入函数后首先对位姿变化的量进行初始化,同时利用project函数对标记过语义的点云进行投影。与其叫做投影,其实更多地是在做格式的转换。
函数首先对场景划分了扇区,扇区只对轴向做了大小的限制,而没有对径向进行约束。从代码来看,一帧点云共计划分了360个扇区,也就是每个扇区在轴向上是一度,之后初始化一个360*1的向量,每个元素为一个32位的浮点数,初始值为0。

之后对于函数传入下采样后的点云filtered_pointcloud,遍历点云中的每个点,对类别标记为13、14、16、18、19的这五类点进行点云格式的转换。查看配置文件可以发现,选择的这五类对应的是building、fence、trunk、pole以及traffic-sign,而没有选择出现次数更多的ground等类别。对于水平距离足够远的点,算法会根据夹角信息计算其所在的扇区,之后将这个点到中心的距离、点在水平方向上的坐标以及该点的语义坐标进行存储。
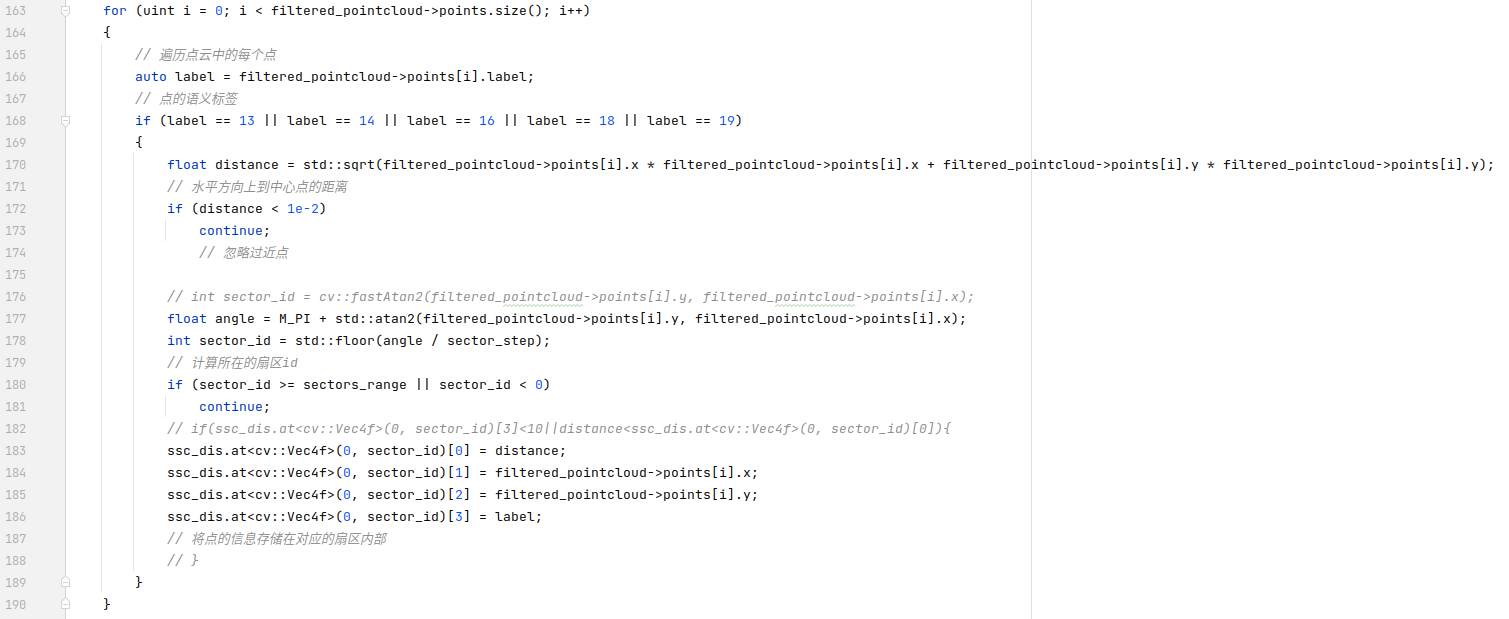
这里就存在一个问题,代码183行到186行对点信息的存储,是直接覆盖的,而不是添加的,这就会导致当一个扇区内同时存在13、14、16、18、19这五类点的时候扇区的描述子实际上是多次覆盖过的。查看作者的原论文,里面写的是每个扇区内部只保留距离中心最近的点,个人推测这里的这种写法是作者默认了filtered_pointcloud是从远到近的排列,因为在之前看的salsanext代码中有对点云重排列的部分,这里作者并没有调用下采样相关的内容,可能是在输入的bin文件点云中已经调整过顺序。
globalICP()
回到getScore函数,在计算出ssc_dis之后,函数进入到globalICP进行一个位姿的计算。这里对应的是原论文中的全局语义ICP的部分。由于描述子的设计具有旋转不变性,所以代码首先利用描述子径向上的距离,计算了两帧点云描述子轴向上应该旋转的量。
具体来说其实就是一个遍历的过程,对于下面的这个二层循环,第一层的i表示的是轴向上应该移动的距离,单位是扇区数量,第二层则是遍历每个扇区,之后计算旋转后两个描述子第一维也就是到中心的距离的差,差值统计在dis_count这个量里面,取最小值对应的i作为两个描述子或者两帧点云在轴向上应该旋转的值。

得到角度之后,就可以将描述子进行旋转,让两个描述子对齐,描述子一共四个维度,其中第一个和最后一个是不用换的,只有第二和第三个的坐标需要调整,也就是根据正弦和余弦进行投影。

之后进行共计100轮次的迭代计算,这一次需要计算的是xy方向上面的平移。每一次迭代首先会取出一个合法扇区,根据先前计算出的径向旋转得到投影之后的位置,在这个位置左右各10个扇区共计20个扇区范围内进行检验。指标是扇区描述子中二三维度对应的点的几何距离。
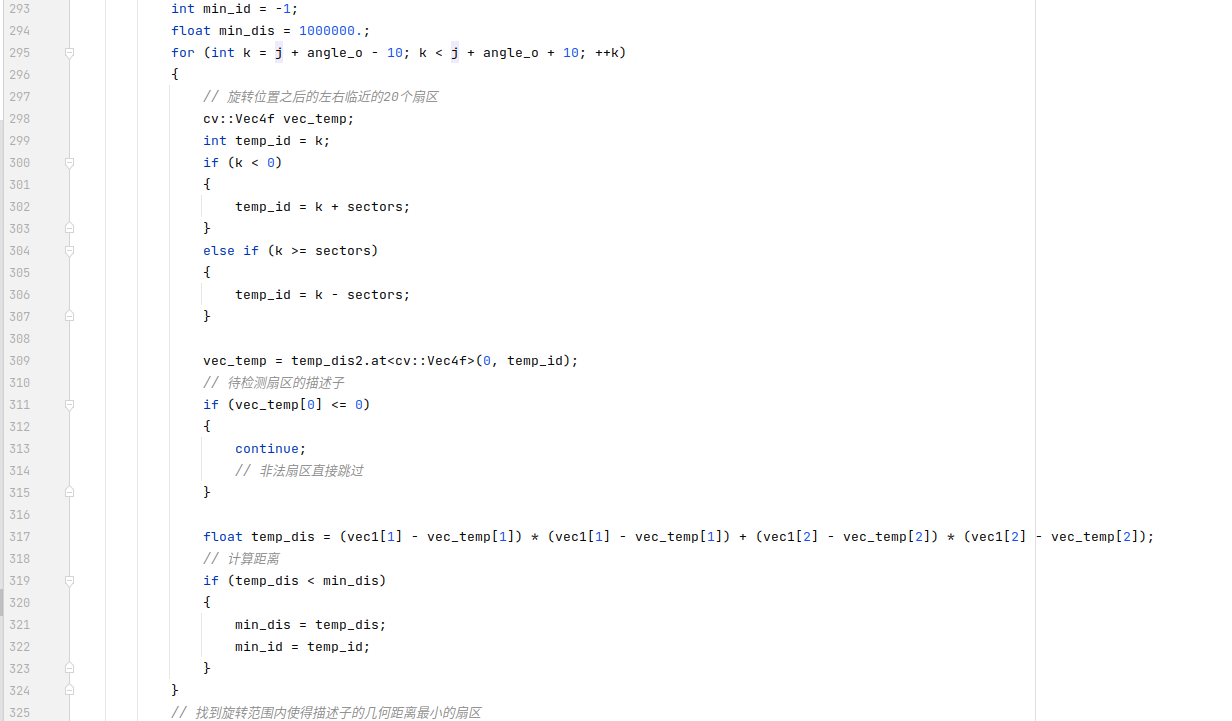
对于当前扇区找到的最近点扇区,如果坐标偏差足够小则进行统计计算,对偏移量进行累计。

遍历完所有扇区之后,对所有的偏差取平均,作为当前这一次迭代计算中的偏差值,这个偏差值表示的是xy方向上面的偏移,直接对点云描述子进行校正,同时存储所有的偏差。
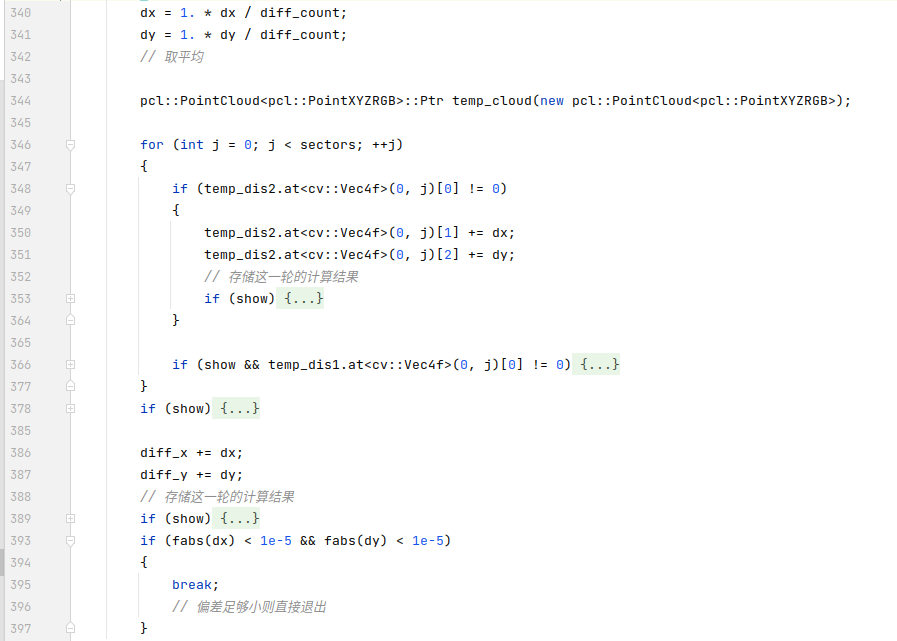
最终,diff_x、diff_y以及angle将会被作为两帧点云之间的位姿差异传递回主函数。从这整个过程来看,globalICP这个函数就是将位姿变化拆分为旋转和平移进行计算,旋转依赖的是扇区描述子的旋转不变性,通过最小化轴向距离差值来找到最优的径向旋转偏差,而平移则是依靠得到的旋转结果进行调整,在计算平移时则不利用径向距离,而是利用扇区之间点的几何距离来调优,迭代100轮以完成平移的计算。这里说一下个人感觉不足的地方,在整个的计算过程中点云被十分过分地简化,按照代码默认的配置文件,径向上划分了360个扇区,就算不考虑语义类别,一帧点云顶天也就只保留了360个点用于构建这个描述子,从数量上来看简化的有些过分。另外,在计算的过程中,旋转和平移被完全拆分开来,先只计算旋转,计算平移时则固定旋转,这种方法未必得到的就是最优的结果,平移和旋转应该作为整体共同进行调整,而没见过这种拆分固定的计算策略。最后,扇区的划分很大程度上会影响结果的准确性,由于选择扇区的点的时候只考虑了到中心点的距离这一个指标,而在径向上完全不做考虑,这就有可能导致一个扇区对应的1度范围内,0.0001度的点和0.9999度的点进行了对齐,有可能导致径向上1度的偏差,而在固定旋转调整平移的过程中更有可能错上加错,所以这一策略或者是开源的代码本身其实是有较大的不足的。
calculateSSC()
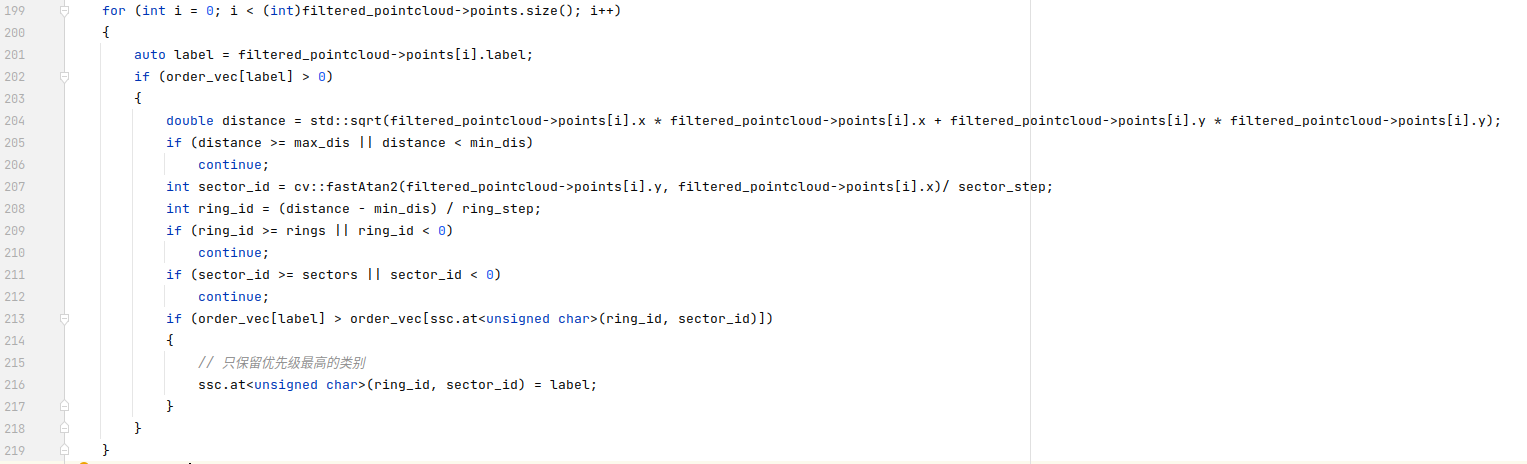
回到getScore函数,globalICP计算出的位姿变化会被存储在diff_x、diff_y以及angle中,利用这个变化关系将点云进行投影,之后调用calculateSSC函数进行ssc描述子的计算。这个函数要简单的多,首先初始化径向和轴向的步长,得到一个二维的矩阵用于存放描述子,矩阵的每个位置存放的都是一个8位无符号数。

之后遍历点云内的每个点,对于需要统计的类别的点,确定其在二维矩阵中的位置。原论文提到了写在描述子中的类别是根据优先级选择的,从代码来看,这个优先级就是提前写死在order_vec里面了。在确定好的位置中,如果已经写入了,就根据优先级进行判断,选择覆盖或者保持不变。
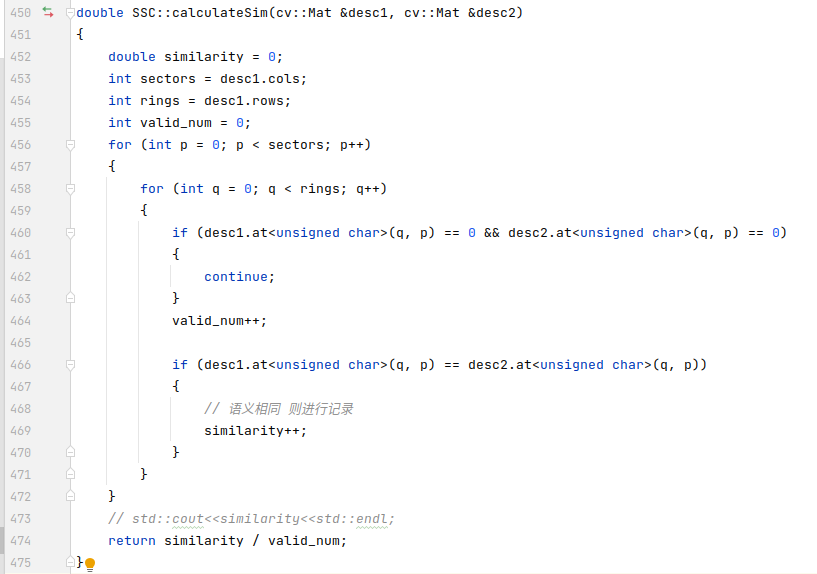
calculateSim()
完成ssc描述子的计算后,就会调用calculateSim函数计算相似度,相似度的计算也很简单,就是比较相同位置上的语义是否相同,最终统计相同的占总合法位置中的比例,这个比例会作为相似度分数返回给主函数。