内容介绍:
模型训练一般分为四个步骤:
-
构建数据集。
-
定义神经网络模型。
-
定义超参、损失函数及优化器。
-
输入数据集进行训练与评估。
具体内容:
- 导包
python
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset
from download import download- 构建数据集
python
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
"notebook/datasets/MNIST_Data.zip"
path = download(url, "./", kind="zip", replace=True)
def datapipe(path, batch_size):
image_transforms = [
vision.Rescale(1.0 / 255.0, 0),
vision.Normalize(mean=(0.1307,), std=(0.3081,)),
vision.HWC2CHW()
]
label_transform = transforms.TypeCast(mindspore.int32)
dataset = MnistDataset(path)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
train_dataset = datapipe('MNIST_Data/train', batch_size=64)
test_dataset = datapipe('MNIST_Data/test', batch_size=64)- 定义神经网络模型
python
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_relu_sequential = nn.SequentialCell(
nn.Dense(28*28, 512),
nn.ReLU(),
nn.Dense(512, 512),
nn.ReLU(),
nn.Dense(512, 10)
)
def construct(self, x):
x = self.flatten(x)
logits = self.dense_relu_sequential(x)
return logits
model = Network()- 定义超参、损失函数和优化器
超参(Hyperparameters)是可以调整的参数,可以控制模型训练优化的过程,不同的超参数值可能会影响模型训练和收敛速度。目前深度学习模型多采用批量随机梯度下降算法进行优化。
训练轮次(epoch):训练时遍历数据集的次数。
批次大小(batch size):数据集进行分批读取训练,设定每个批次数据的大小。batch size过小,花费时间多,同时梯度震荡严重,不利于收敛;batch size过大,不同batch的梯度方向没有任何变化,容易陷入局部极小值,因此需要选择合适的batch size,可以有效提高模型精度、全局收敛。
学习率(learning rate):如果学习率偏小,会导致收敛的速度变慢,如果学习率偏大,则可能会导致训练不收敛等不可预测的结果。梯度下降法被广泛应用在最小化模型误差的参数优化算法上。梯度下降法通过多次迭代,并在每一步中最小化损失函数来预估模型的参数。学习率就是在迭代过程中,会控制模型的学习进度。
python
epochs = 3
batch_size = 64
learning_rate = 1e-2损失函数(loss function)用于评估模型的预测值(logits)和目标值(targets)之间的误差。训练模型时,随机初始化的神经网络模型开始时会预测出错误的结果。损失函数会评估预测结果与目标值的相异程度,模型训练的目标即为降低损失函数求得的误差。
常见的损失函数包括用于回归任务的`nn.MSELoss`(均方误差)和用于分类的`nn.NLLLoss`(负对数似然)等。 `nn.CrossEntropyLoss` 结合了`nn.LogSoftmax`和`nn.NLLLoss`,可以对logits 进行归一化并计算预测误差。
python
loss_fn = nn.CrossEntropyLoss()模型优化(Optimization)是在每个训练步骤中调整模型参数以减少模型误差的过程。MindSpore提供多种优化算法的实现,称之为优化器(Optimizer)。优化器内部定义了模型的参数优化过程(即梯度如何更新至模型参数),所有优化逻辑都封装在优化器对象中。在这里,我们使用SGD(Stochastic Gradient Descent)优化器。
我们通过`model.trainable_params()`方法获得模型的可训练参数,并传入学习率超参来初始化优化器。
python
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)在训练过程中,通过微分函数可计算获得参数对应的梯度,将其传入优化器中即可实现参数优化,具体形态如下:
grads = grad_fn(inputs)
optimizer(grads)
- 训练与评估
设置了超参、损失函数和优化器后,我们就可以循环输入数据来训练模型。一次数据集的完整迭代循环称为一轮(epoch)。每轮执行训练时包括两个步骤:
-
训练:迭代训练数据集,并尝试收敛到最佳参数。
-
验证/测试:迭代测试数据集,以检查模型性能是否提升。
python
def forward_fn(data, label):
logits = model(data)
loss = loss_fn(logits, label)
return loss, logits
# Get gradient function
grad_fn = mindspore.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=True)
# Define function of one-step training
def train_step(data, label):
(loss, _), grads = grad_fn(data, label)
optimizer(grads)
return loss
def train_loop(model, dataset):
size = dataset.get_dataset_size()
model.set_train()
for batch, (data, label) in enumerate(dataset.create_tuple_iterator()):
loss = train_step(data, label)
if batch % 100 == 0:
loss, current = loss.asnumpy(), batch
print(f"loss: {loss:>7f} [{current:>3d}/{size:>3d}]")
python
def test_loop(model, dataset, loss_fn):
num_batches = dataset.get_dataset_size()
model.set_train(False)
total, test_loss, correct = 0, 0, 0
for data, label in dataset.create_tuple_iterator():
pred = model(data)
total += len(data)
test_loss += loss_fn(pred, label).asnumpy()
correct += (pred.argmax(1) == label).asnumpy().sum()
test_loss /= num_batches
correct /= total
print(f"Test: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
python
loss_fn = nn.CrossEntropyLoss()
optimizer = nn.SGD(model.trainable_params(), learning_rate=learning_rate)
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train_loop(model, train_dataset)
test_loop(model, test_dataset, loss_fn)
print("Done!")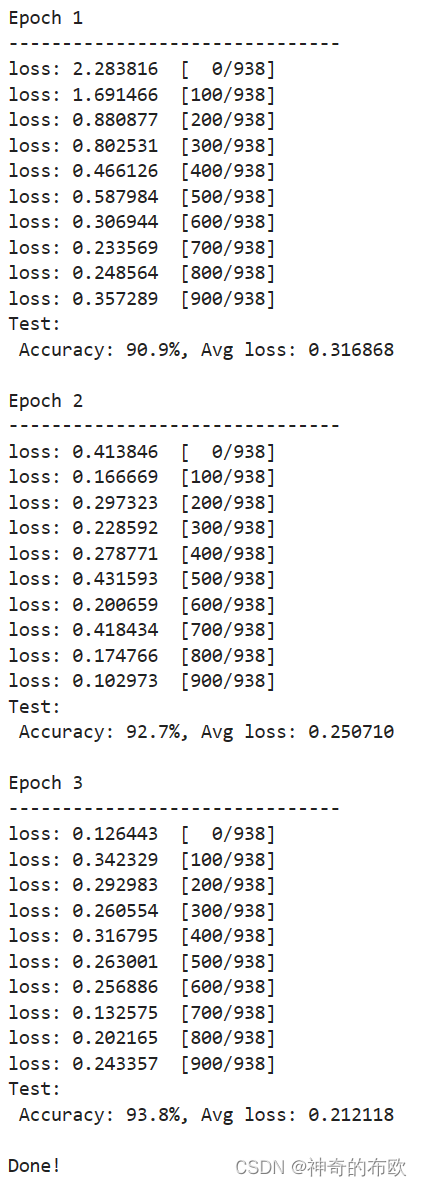
MindSpore的易用性也给我带来了很大的便利。通过简洁明了的API和丰富的文档支持,我能够快速地掌握MindSpore的使用方法,并轻松地构建自己的深度学习模型。同时,MindSpore还提供了丰富的预训练模型和示例代码,让我能够更快地入门并深入理解深度学习的应用。
在模型训练的过程中,我深刻体会到了深度学习模型的复杂性和挑战性。通过不断地调整网络结构、优化参数设置以及尝试不同的训练策略,我逐渐掌握了如何构建和训练一个性能优异的深度学习模型。这个过程让我更加明白了深度学习模型训练需要耐心、细致和持续的努力。
