爬虫(Spider)是一种自动化程序,用于在互联网上获取信息。
 其工作原理主要可以分为以下几个步骤:
其工作原理主要可以分为以下几个步骤:
- 发起请求 :
- 爬虫首先需要向目标网站发起HTTP请求,以获取网页的内容。这个请求可以包含一些额外的信息,如请求头、请求参数等。
- 接收响应 :
- 目标网站在收到请求后,会返回一个HTTP响应。这个响应中包含了网页的内容以及状态码等信息。爬虫需要接收并解析这个响应。
- 解析网页 :
- 爬虫需要从网页中提取所需的数据。这通常需要使用各种解析技术,如正则表达式、XPath、CSS选择器等,来定位和提取特定的数据。
- 处理数据 :
- 爬虫获取到数据后,可以进行一些数据处理的操作,如清洗数据、转换数据格式等,以满足后续的需求。
- 存储数据 :
- 最后,爬虫将处理后的数据保存到本地文件或数据库中,以便后续的分析、展示或其他用途。
爬虫按照抓取网站对象的不同,可以分为通用爬虫 和垂直爬虫:
- 通用爬虫:类似百度、谷歌这样的爬虫,抓取对象是整个互联网,对于网页没有固定的抽取规则。对于所有网页都是一套通用的处理方法。
- 垂直爬虫:这类爬虫主要针对一些特定对象、网站,有一台指定的爬取路径、数据抽取规则。比如今日头条的目标网站就是所有的新闻类网站,而Etao比价、网易的慧慧购物助手的目标网站则是淘宝、京东、天猫等电商网站。
总的来说,爬虫通过模拟人类在浏览器中访问网页的行为,自动抓取、下载互联网上的网页,并按照一定的规则算法对这些网页进行数据抽取、索引和存储,从而实现对互联网上信息的自动化获取和处理。
流程
爬虫可以节省我们的时间,比如我要获取豆瓣电影 Top250 榜单,如果不用爬虫,我们要先在浏览器上输入豆瓣电影的 URL ,客户端(浏览器)通过解析查到豆瓣电影网页的服务器的 IP 地址,然后与它建立连接,浏览器再创造一个 HTTP 请求发送给豆瓣电影的服务器,服务器收到请求之后,把 Top250 榜单从数据库中提出,封装成一个 HTTP 响应,然后将响应结果返回给浏览器,浏览器显示响应内容,我们看到数据。我们的爬虫也是根据这个流程,只不过改成了代码形式。
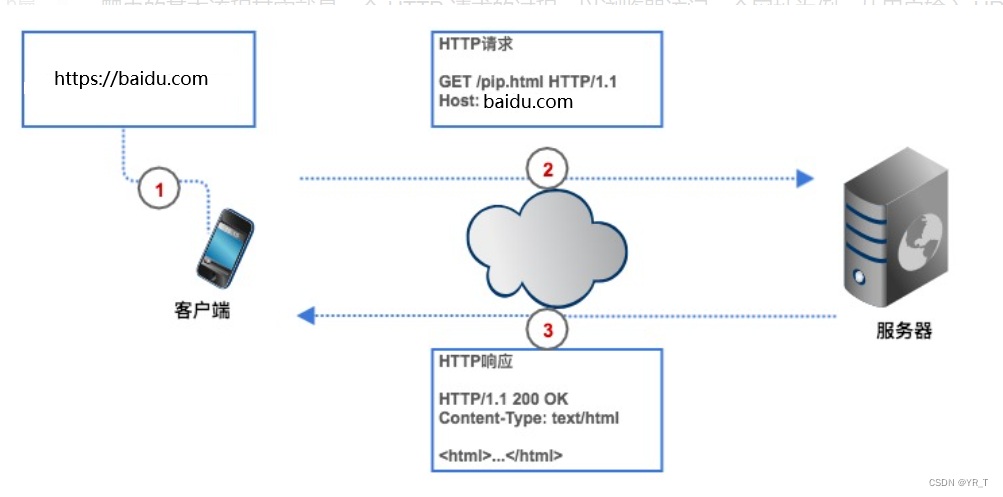
HTTP请求
HTTP 请求由请求行、请求头、空行、请求体组成。
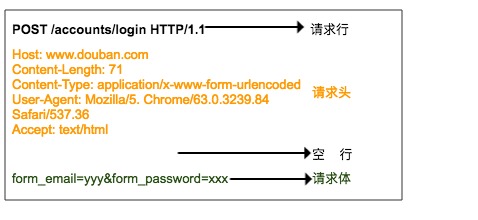
请求行由三部分组成:
1.请求方法,常见的请求方法有 GET、POST、PUT、DELETE、HEAD
2.客户端要获取的资源路径
3.是客户端使用的 HTTP 协议版本号 请求头是客户端向服务器发送请求的补充说明,比如说明访问者身份,这个下面会讲到。
请求体是客户端向服务器提交的数据,比如用户登录时需要提高的账号密码信息。请求头与请求体之间用空行隔开。请求体并不是所有的请求都有的,比如一般的GET都不会带有请求体。
上图就是浏览器登录豆瓣时向服务器发送的HTTP POST 请求,请求体中指定了用户名和密码。
HTTP 响应
HTTP 响应格式与请求的格式很相似,也是由响应行、响应头、空行、响应体组成。
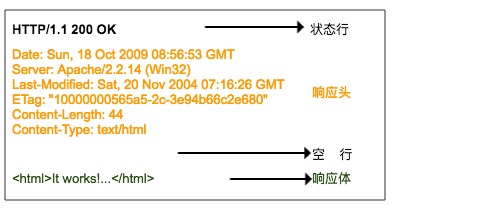
响应行也包含三部分,分别是服务端的 HTTP 版本号、响应状态码和状态说明。
这里状态码有一张表,对应了各个状态码的意思



第二部分就是响应头,响应头与请求头对应,是服务器对该响应的一些附加说明,比如响应内容的格式是什么,响应内容的长度有多少、什么时间返回给客户端的、甚至还有一些 Cookie 信息也会放在响应头里面。
第三部分是响应体,它才是真正的响应数据,这些数据其实就是网页的 HTML 源代码。
爬虫代码怎么写
爬虫可以用很多语言比如 Python、C++等等,但是我觉得Python是最简单的,
因为Python有现成可用的库,已经封装到几乎完美,
C++虽然也有现成的库,但是它的爬虫还是比较小众,仅有的库也不足以算上简单,而且代码在各个编译器上,甚至同一个编译器上不同版本的兼容性不强,所以不是特别好用。所以今天主要介绍python爬虫。
安装requests库
cmd运行:pip install requests ,安装 requests。
然后在 IDLE 或者编译器(个人推荐 VS Code 或者 Pycharm )上输入
import requests 运行,如果没有报错,证明安装成功。
安装大部分库的方法都是:pip install xxx(库的名字)
requests的方法
|--------------------|---------------------------------|
| requests.request() | 构造一个请求,支撑一下各方法的基本方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch( ) | 向HTML网页提交局部修改请求,对应于HTTP的PATCT |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
最常用的get方法
r = requests.get(url)
包括两个重要的对象:
构造一个向服务器请求资源的Request对象;返回一个包含服务器资源的Response对象
|---------------------|----------------------------------------------------------------|
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式(如果header中不存在charset,则认为编码为ISO-8859-1) |
| r.apparent_encoding | 从内容中分析的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
|---------------------------|-------------------------|
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器超时异常 |
| requests.Timeout | 请求URL超时,产生超时异常 |
爬虫小demo
requests是最基础的爬虫库,但是我们可以做一个简单的翻译
我先把我做的一个爬虫的小项目的项目结构放上,完整源码可以私聊我下载。
下面是翻译部分的源码
import requests
def English_Chinese():
url = "https://fanyi.baidu.com/sug"
s = input("请输入要翻译的词(中/英):")
dat = {
"kw":s
}
resp = requests.post(url,data = dat)# 发送post请求
ch = resp.json() # 将服务器返回的内容直接处理成json => dict
resp.close()
dic_lenth = len(ch['data'])
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])代码详解:
导入requests模块,设置 url为百度翻译网页的网址。
然后通过 post 方法发送请求,再把返回的结果打成一个 dic (字典),但是这个时候我们打印出来结果发现是这样的。

这是一个字典里套列表套字典的样子,大概就是这样的
{ xx:xx , xx: {xx:xx} , {xx:xx} , {xx:xx} , {xx:xx} }
我标红的地方是我们需要的信息。
假如说我标蓝色的列表里面有 n 个字典,我们可以通过 len() 函数获取 n 的数值,
并使用 for 循环遍历,得到结果。
dic_lenth = len(ch['data']
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])全套Python学习资料分享:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。