0.我理解的RAG
什么是RAG?
RAG的全称是"检索增强生成模型"(Retrieval-Augmented Generation)。这是一种特别聪明的大语言模型。
RAG是怎么工作的呢?
1.检索:当你问RAG一个问题时,它会先去"图书馆"里找相关的信息。这些"图书馆"里有很多知识和数据。
2.生成 :找到了相关的信息后,RAG会用这些信息来生成一个回答。
为什么RAG很厉害?
有时候,大语言模型可能会不记得所有的细节,但RAG可以通过检索来找到需要的具体信息,然后再回答你的问题。这就像是你问一个问题,RAG先去查了一下百科全书,然后再告诉你答案,所以回答会更准确。
举个例子:
问:"世界上最高的山是什么?"
RAG做了什么:
1.去"图书馆"查找关于最高山的资料。
2.找到了珠穆朗玛峰是世界上最高的山。
3.回答:"世界上最高的山是珠穆朗玛峰,高约8848米。"
这样,通过先检索再生成答案,RAG可以提供准确而有用的回答。
这其中去"图书馆"查找关于高山的资料,我们就可以通过一些方法,将自己拥有的数据进行处理,让大语言模型结合我们问的问题在我们处理后的数据中寻找答案。
1.我的RAG程序的执行流程
-
模型初始化
初始化一个大语言模型(LLM)和一个嵌入模型(embedding模型)。
-
读取文档进行数据分割
将文档交给代码进行读取,将长文档分割成较小的部分,以便处理。
-
向量处理
将分割后的文档数据通过嵌入模型进行向量化处理,生成每个文档段落的向量表示。
将向量化处理后的数据保存到数据库中。
-
检索流程
创建一个包含检索和生成步骤的处理链。
-
RAG链包括以下步骤:
-
创建检索器
从向量存储的数据库中创建检索器,在检索时使用余弦距离来衡量向量之间的相似度。 检索器用于检索与输入问题相关的文档内容。
-
加载提示词模板
加载提示词模板,用于指导大语言模型生成回答。
-
格式化检索到的文档
将检索到的相关文档内容通过格式化函数转换为一个字符串,方便后续处理。
-
调用处理链处理输入问题
输入的问题首先通过检索器检索相关文档。
然后结合提示词模板和格式化后的文档内容,传递给大语言模型。
大语言模型生成一个准确的回答。
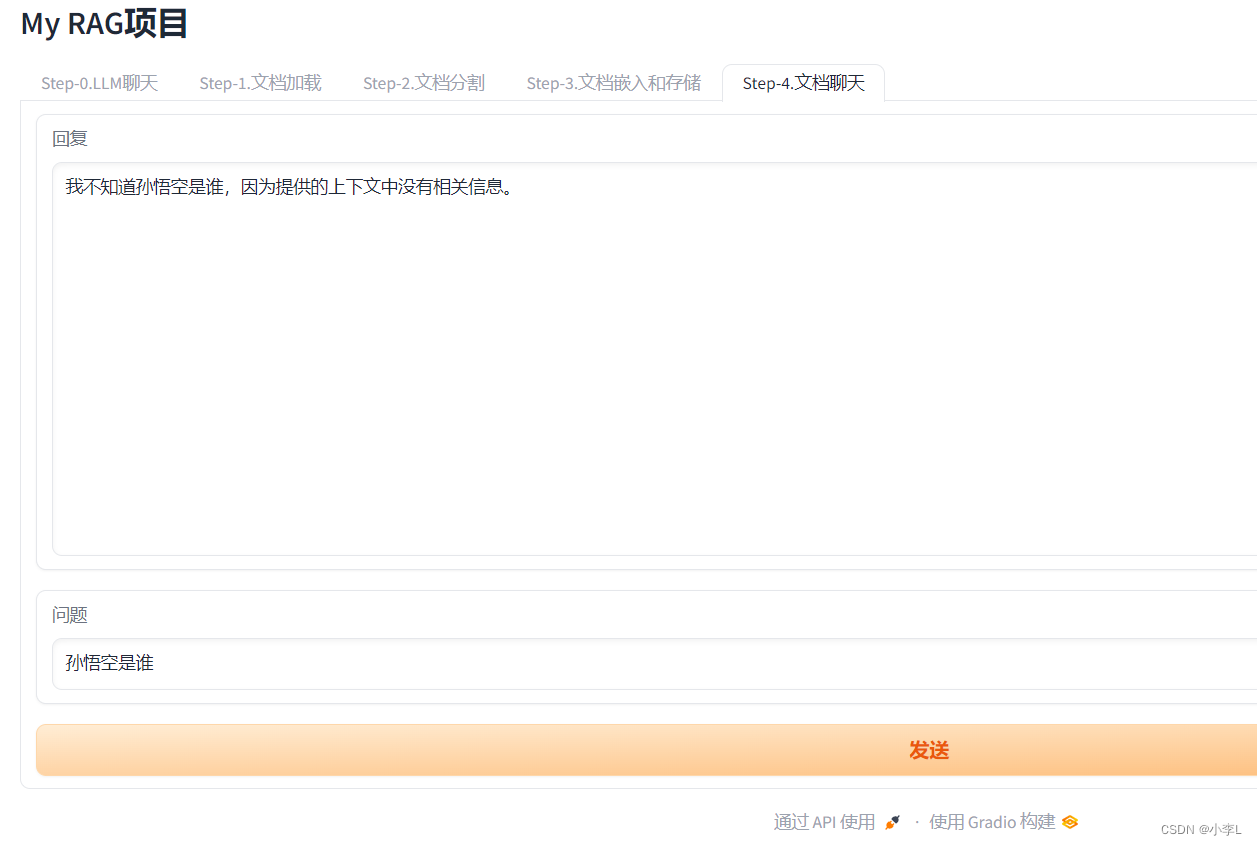
2.效果
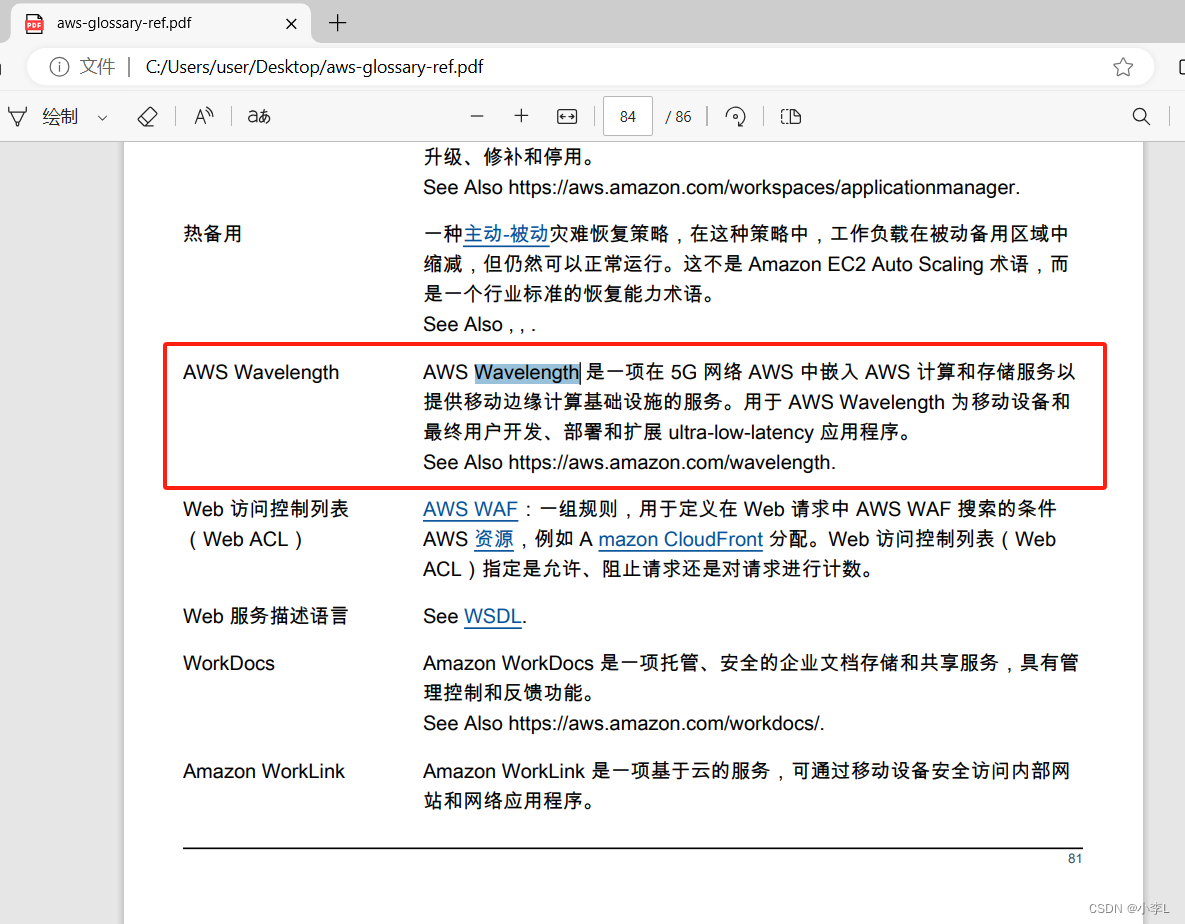
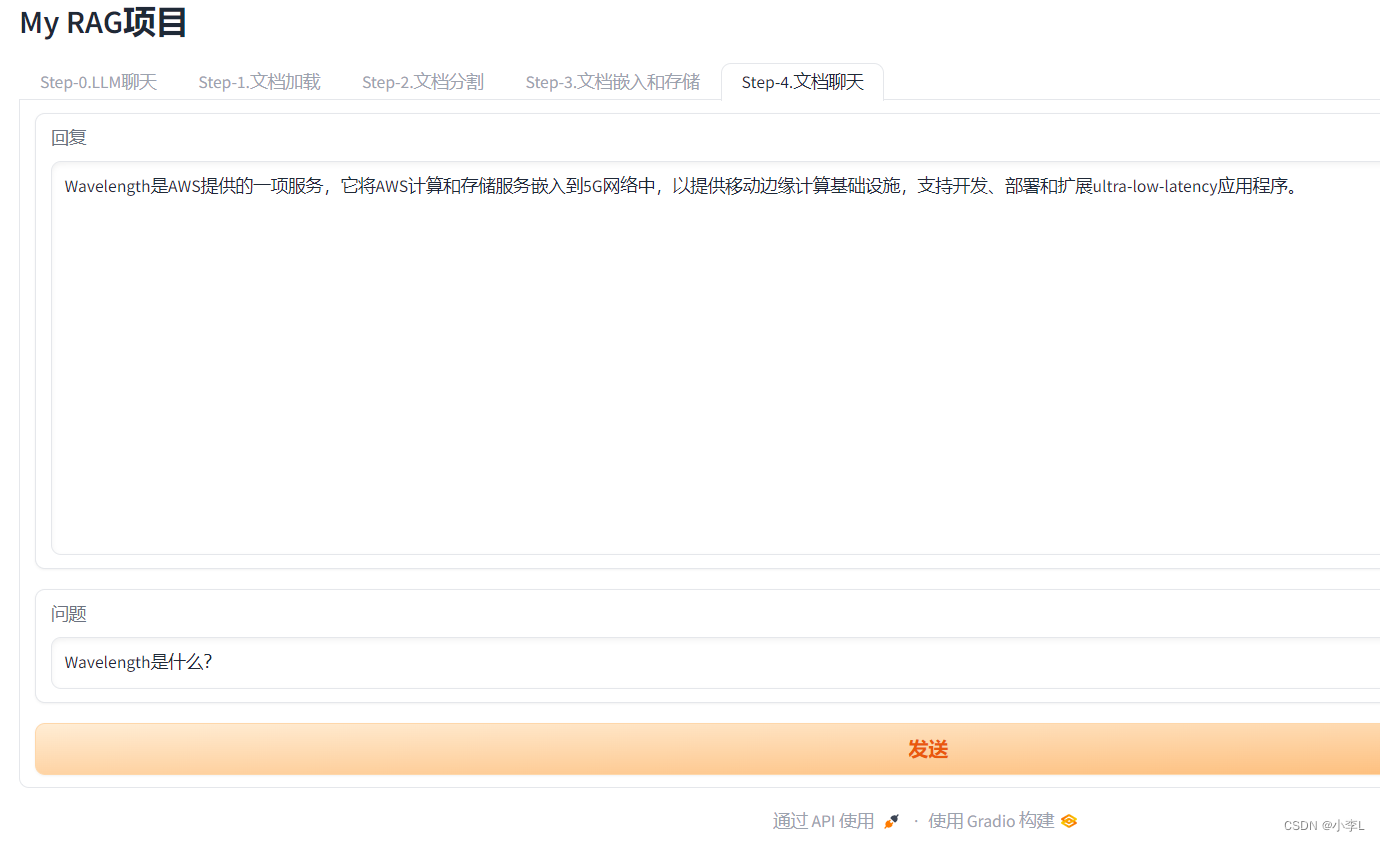 在我的提示词模板中, 说明了,如果文档中不存在的内容,只需要回答不知道就可以了。
在我的提示词模板中, 说明了,如果文档中不存在的内容,只需要回答不知道就可以了。