OpenAI的发布会惊艳的操作,近乎实时的语音对话,让很多人向往。
但实际上Chat对话时,尚无输出音频的能力,可能还未开放。

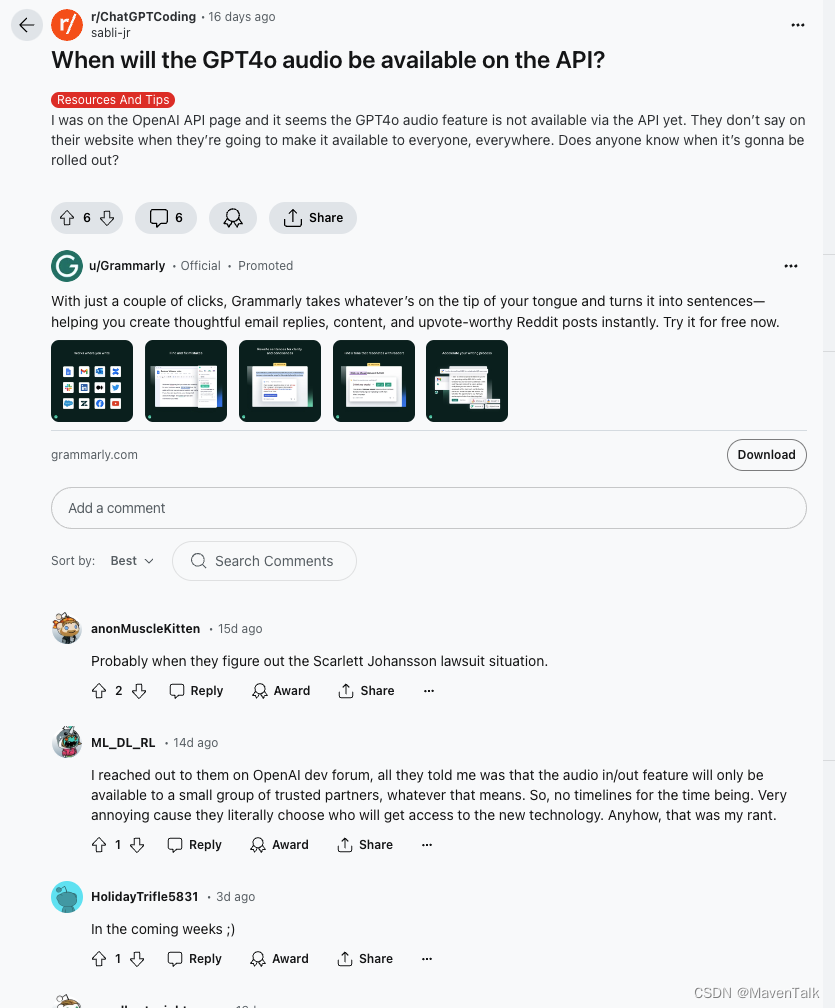
这是国外的一个开发小哥的交流帖子,可能还需要些时日才能用的上实时的音频输出。
不过当前OpenAI也开放了两个TTS模型,基于之前的开放的Whisper能力,很有可能Chat输出的音频能力是基于这两个模型完成的。

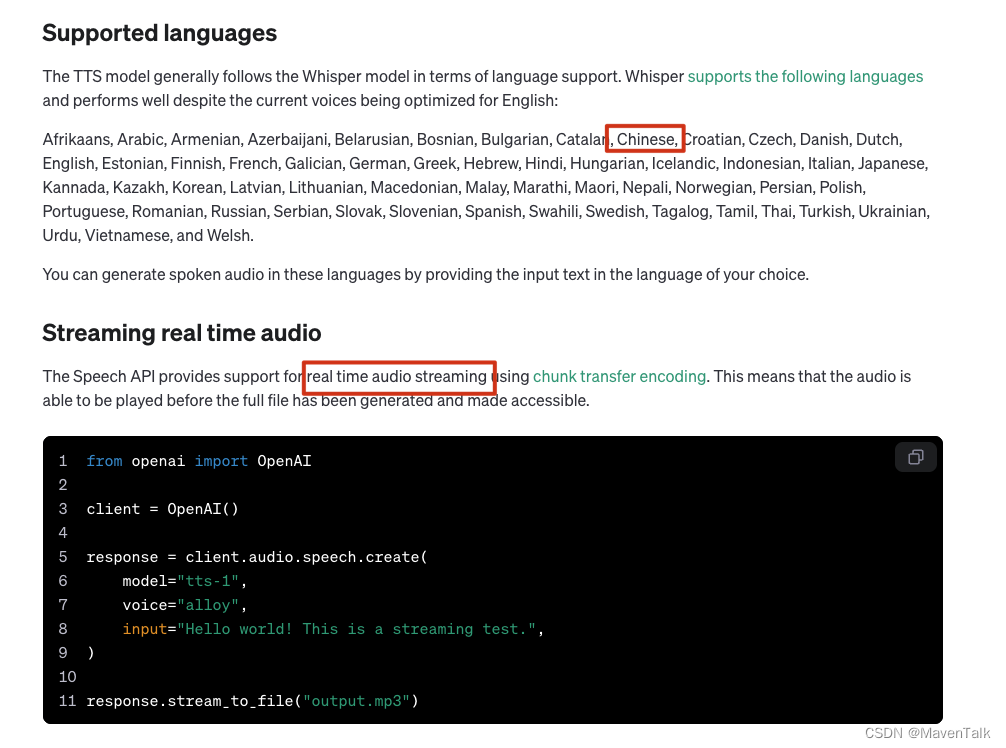
并且有实时播放能力,相比以前只能全部请求完才能播放也是一个巨大的进步,并且支持中文输出。
OpenAI的发布会惊艳的操作,近乎实时的语音对话,让很多人向往。
但实际上Chat对话时,尚无输出音频的能力,可能还未开放。
这是国外的一个开发小哥的交流帖子,可能还需要些时日才能用的上实时的音频输出。
不过当前OpenAI也开放了两个TTS模型,基于之前的开放的Whisper能力,很有可能Chat输出的音频能力是基于这两个模型完成的。
并且有实时播放能力,相比以前只能全部请求完才能播放也是一个巨大的进步,并且支持中文输出。