本内容是根据 Flink 1.18.0-Scala_2.12 版本源码梳理而来。本文主要讲述任务提交时,为 Task 分配资源的过程。
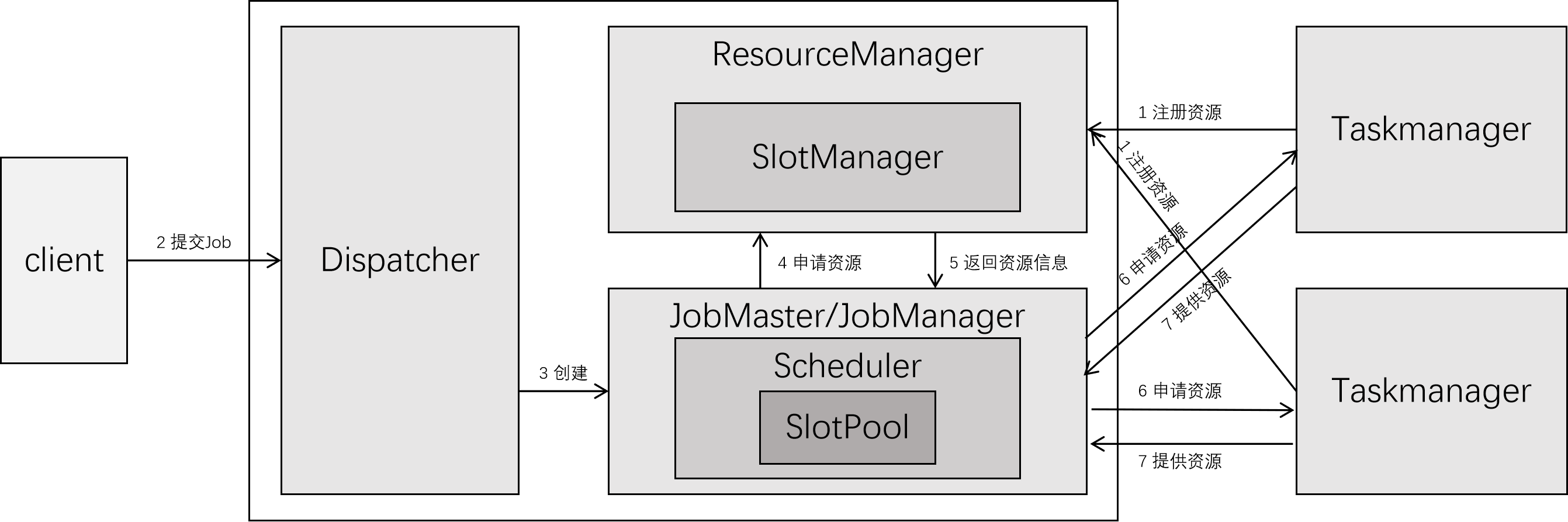
以下是具体步骤讲解:
- TaskManager 资源注册
TaskManager 在启动时,会向 ResourceManager 注册资源。ResourceManager 会将 TaskManager 的资源以 ResourceProfile 的形式记录。 - 提交 Job
再 Flink 系统启动后,会启动一个名为 Dispatcher 的组件。Flink 客户端会将用户编写的代码整理为 JobGraph,并提交至 Dispatcher。Dispatcher 会为每一个 JobGraph 创建一个 JobMaster。由 JobMaster 管理其 Job 的资源分配。
JobMaster 内部包含一个调度器(Scheduler),再 1.18 版本中,Scheduler 的实现有:DefaultScheduler、AdaptiveScheduler和AdaptiveBatchScheduler。
默认使用DefaultScheduler,其使用PipelinedRegionSchedulingStrategySchedulingStrategy作为他的调度 - JobMaster 从 SlotPool 中挑选资源分配给 Job
每个 JobMaster 有一个 SlotPool,负责管理属于它的资源。
对于PipelinedRegionSchedulingStrategySchedulingStrategy,它会使用SlotSharingStrategy和SlotSelectionStrategy来决定调度策略。
SlotSharingStrategy负责将某些 SubTask 放在同一 Slot 中,此时产生的 Slot 叫做 SharedSlot。SharedSlot 只是一个逻辑概念,不是具体的物理资源。共享的策略目前只有LocalInputPreferredSlotSharingStrategy。
当作业是首次提交,且不与其他作业共享资源时,SharedSlot 是不与物理资源对应的。那么就需要SlotSelectionStrategy来为 SharedSlot 选择物理资源。为其选择的物理资源被称为 PhysicalSlot。SlotSelectionStrategy根据某种策略,从 SlotPool 中挑选 PhysicalSlot 分配给 SharedSlot。这个策略目前有DefaultLocationPreferenceSlotSelectionStrategy和EvenlySpreadOutLocationPreferenceSlotSelectionStrategy。
然后,每个 SubTask 对应的执行节点(ExecutionVertex)中会记录期望分配的资源的信息。
但是,作业首次提交时,它的 JobMaster 的 SlotPool 中是没有任何资源的,那么就需要下一步。 - JobMaster 向 ResourceManager 申请资源
JobMaster 会将 SlotPool 中缺少的资源信息以 ResourceProfile 的形式发送给 ResourceManager 来申请资源。具体是 SlotPoolService 向 SlotManager 来申请资源。
SlotManager 的具体实现目前有:DeclarativeSlotManager和FineGrainedSlotManager。DeclarativeSlotManager支持作业级动态调度,FineGrainedSlotManager支持任务级动态调度。早期版本还有SlotManagerImpl,其只支持静态调度,已被抛弃。
SlotManager 接收到 JobMaster 所需的资源后,会与已注册的资源以某种策略进行匹配,匹配成功后,会将资源发送给 JobMaster。 - JobMaster 向 TaskManager 申请资源
JobMaster 从 ResourceManager 得到可用的资源的信息后,会向每个资源对应的 TaskManager 发送资源信息。TaskManager 在收到资源信息后,会从它的资源中划分出相应的资源,并创建 Slot,然后激活 Slot。之后 TaskManager 会将已激活的 Slot 资源信息返回给 JobMaster。
JobMaster 将发送给 TaskManager 的资源信息与TaskManager 返回的资源信息进行对比,若对比无误,则将 Slot 资源存储至 SlotPool。 - 部署 Task
经过上面几步,Slot 已准备完毕。接下来,就是期望的资源信息会与已准备的资源进行匹配,若匹配成功,则部署。