文章目录
单机架构
单机架构只有一台服务器,使用一台服务器负责所有的工作
举个例子:假设有以下电商网站,商品、用户、交易等功能服务以及数据库都在一个服务器上。

而现在计算机硬件发展也是非常快的,哪怕只有一台主机,这一台主机的性能也是非常高的。可以支持高并发和非常大的数据存储。
但是,如果说业务进一步增长,用户量和数据量都水涨船高,那么,一台主机难以应付的时候,就需要再增加主机了。
为什么硬件资源会不够用呢?
因为,一台主机所包括的硬件资源主要都有(cpu、内存、硬盘等等),而服务器每次收到一个请求,都是需要消耗上述的资源的,如果同一时刻,处理的请求太多的(高并发),此时就可能导致某个硬件资源不够用了,就都会导致服务器处理请求的时间变长,甚至处理出错~~
此时,遇见这种服务器不够用的情况(高并发情况),有效的处理方式可以从两方面考虑:
- 开源 ,增加更多的硬件资源。
- 节流,针对软件上进行优化,例如sql语句优化等
如果使用开源的方式,就会出现一个问题,一个主机上面能增加的硬件资源也是有限的,所以,一台主机扩展到极限了,但是还是不够,就只能引入多台主机,一旦引入多台主机了,此时系统就可以称为"分布式系统"。
引入分布式是好是坏呢?
答:引入分布式是万不得已的,一旦引入分布式,系统的复杂程度就会大大提高,系统越复杂,出现bug的概率就越高,但是,如果出现一台主机无法处理的情况,还是要使用分布式的,所以,就需要根据具体的业务场景来指定更好的解决方案。
应用服务和存储服务分离
最简单的分布式系统就是将应用服务器和数据库服务器分离,将应用服务器放在另一台主机上,数据库服务器放在另一台主机上。
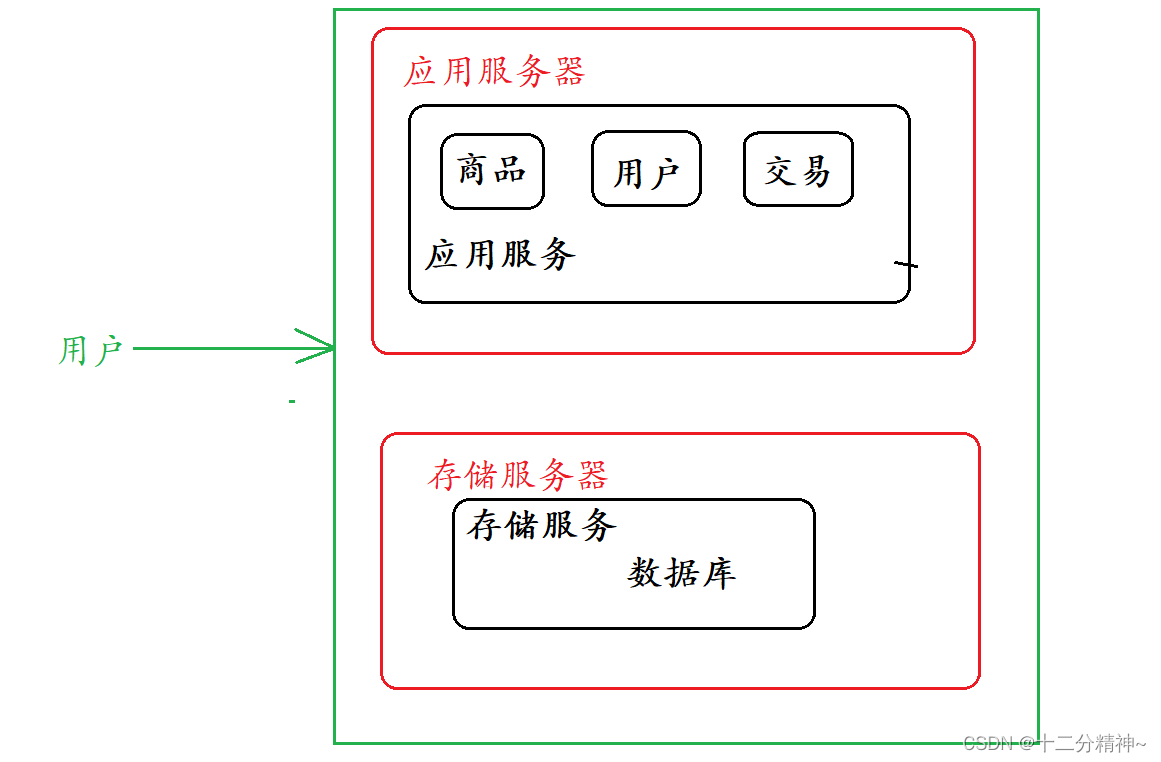
但是,随着请求量进一步增加,这时候,一台应用服务器可能就会顶不住了,此时就就可以使用集群架构,引入多个应用服务器,如下图。
应用服务集群架构
引入负载均衡器(也是一个单独的服务器)来管理多个应用服务器,意思就是,所有的用户请求都要先到负载均衡器上,然后再由负载均衡器将请求进行分发,发送到不同的应用服务器上,保证了应用服务器再高并发场景下,不会进行宕机。
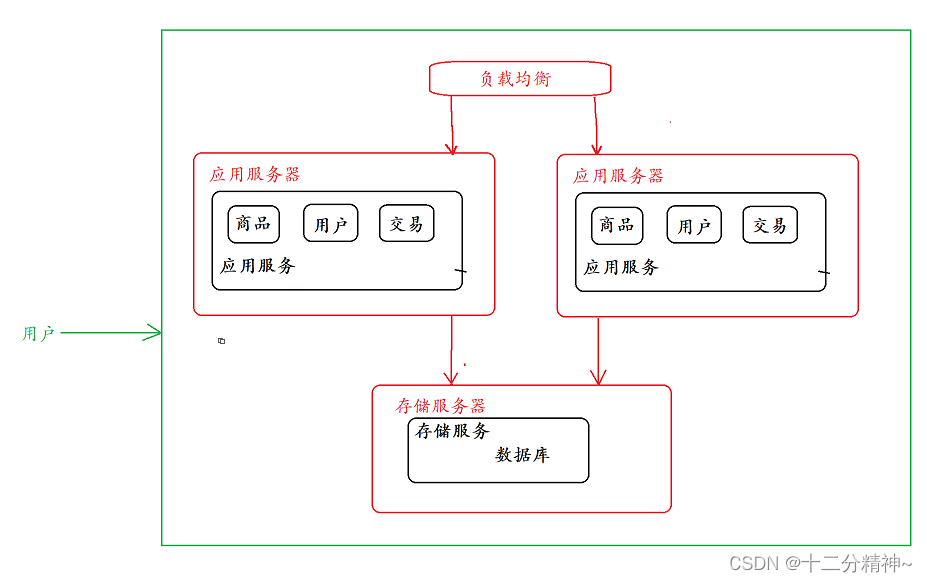
对于负载均衡器来说,也有很多的流量调度(对请求进行分发)的算法,例如:
- 轮询算法:非常公平的将请求依次发给不同的应用服务器
相关的负载均衡软件都有:Nginx、HAProxy、LVS等
还有一个问题就是:使用负载均衡器是因为请求量太大了,单个应用服务器无法承受,所以要使用负载均衡器进行分配,但是,如果并发量太高的话,负载均衡器能承受的住吗?
答案是:负载均衡器对于请求量的承担能力,要远超于应用服务器的,因为,负载均衡器它的工作主要是向不同的应用服务器上分发请求,而应用服务器的任务是处理请求,负载均衡器就好像是领导,负责分配任务,应用服务器就好像是组员,负责执行任务。分配任务肯定是要比执行任务更轻松的。
如果请求量大到了负载均衡器也扛不住了,此时,也可以引入更多的负载均衡器(引入多个机房)。
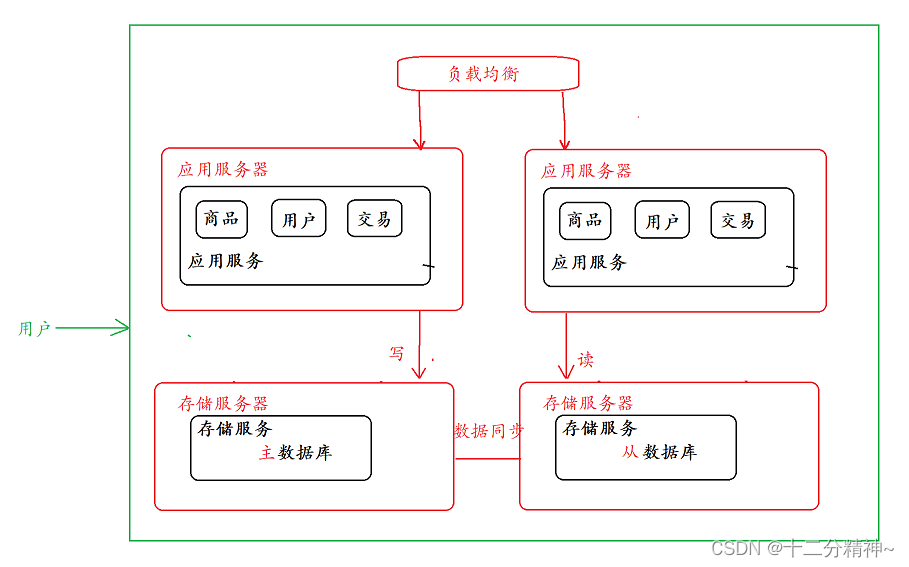
读写分离/主从分离架构
上面使用了负载均衡器来给不同的应用服务器分配请求,但是,现在有一个问题,就是不管扩充多少个应用服务器,这些请求最终都是要到数据库中读写数据,那所有的压力不都给到了数据库服务器吗,所以,针对这样的情况,就可以设置一些数据库为主数据库 ,一些数据库为 从数据库,从库所有的数据都来自主库,经过同步后,从库中的数据和主库保持一致,而为了分担数据库的压力,可以将写数据请求全部交给主库处理,读数据请求分散到各个从库中,因为,一个程序中读操作要比写操作更多,这样也就缓解了数据库的压力,当然,这个数据同步的过程也是有时间成本的。
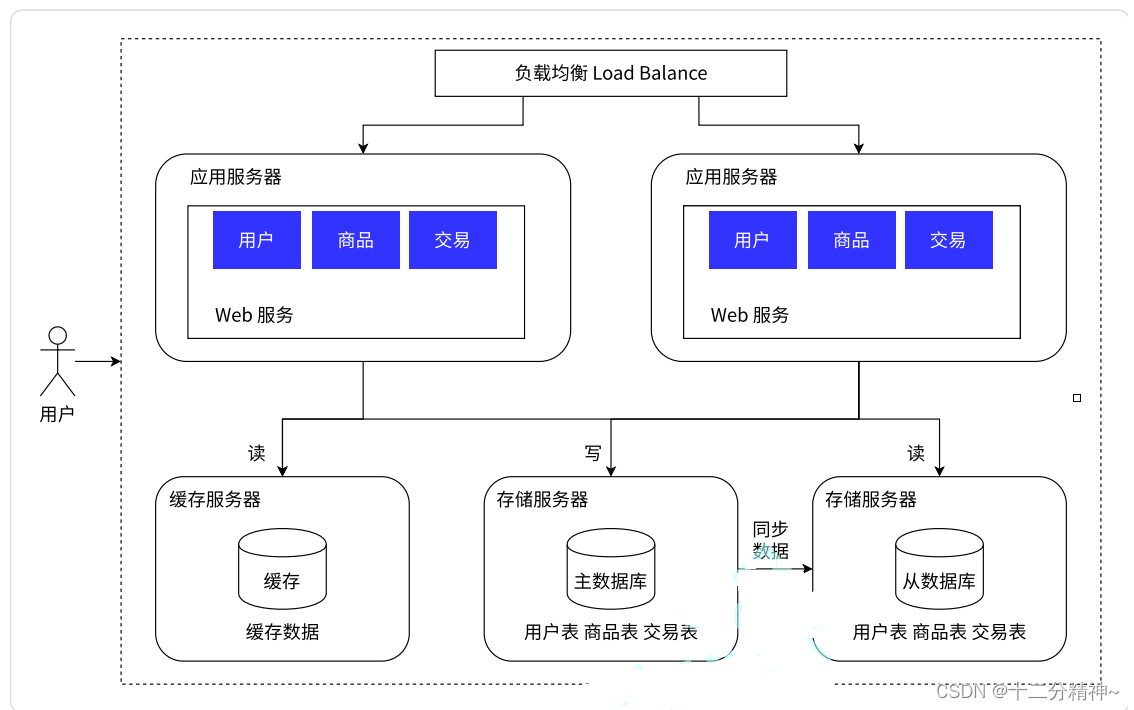
冷热分离架构--引入缓存
上面虽然通过主从架构缓解了数据库的压力,但是,我们知道,数据库中的数据都是在硬盘中存储的,读硬盘就会很慢,为了能够提高获取数据的速度,就可以把数据区分"冷热",热点数据放到缓存中,缓存的访问速度要比硬盘快很多,因为,缓存中的数据是在内存中保存着的,所以,redis主要的用途就是用来管理缓存服务器中的数据,如下图:
分库分表
上述都是针对请求量太大时所做的解决策略,但是,引入分布式系统,不光要能够去应对更高的请求量,同时也要能应对更大的数据量,当数据太多时,也可能会存在一台主机存不下的情况,可以使用多台主机存储,针对数据库进行进一步的拆分,本来一个数据库服务器上有多个数据库,现在引入多个数据库服务器,每个数据库服务器存储一个或多个数据库,如果某个表特别大,大到一台主机存不下,也可以针对表进行拆分,拆分成多个表分布在不同的主机上。
,每个数据库服务器存储一个或多个数据库,如果某个表特别大,大到一台主机存不下,也可以针对表进行拆分,拆分成多个表分布在不同的主机上。