yolo核心思想:把目标检测转变成一个回归问题。将整个图像作为网络的输入,仅仅经过一个神经网络,得到边界框的位置及其所属的类别。
YOLOv1 CVPR2016
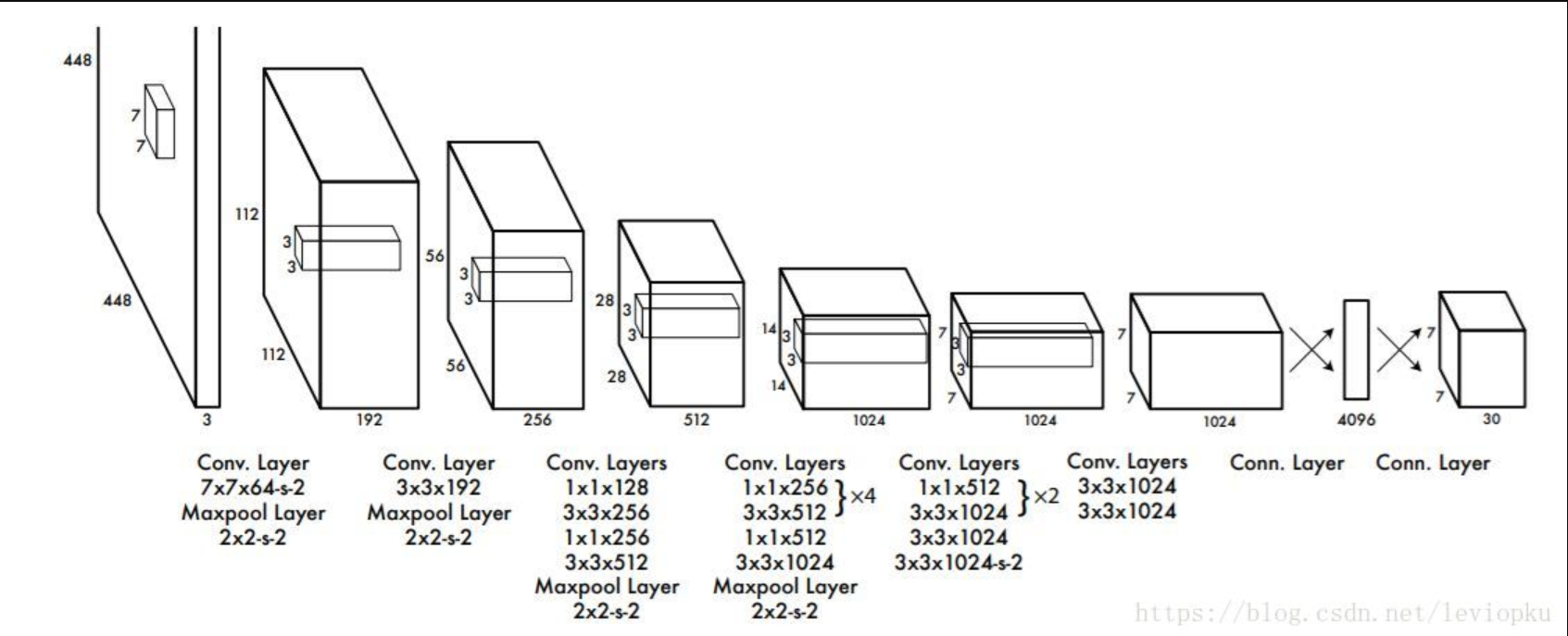
输出7×7×30的张量表示2个框的5个参数和20个种类。leaky ReLU,leaky并不会让负数直接为0,而是乘以一个很小的系数(恒定),保留负数输出,但衰减负数输出。y=x,x>0;0.1x,otherwise;分而治之;端到端训练,损失函数的传播贯穿整个网络。第一个全连接层,把输入图像的所有卷积特征整合到一起;第二个全连接层,将所有神经元得到的卷积特征进行维度转换,最后得到与目标检测网络输出维度相同的维度。
YOLOv2 CVPR2017
(1)yolov2借鉴了Faster R-CNN的思想,引入Anchor机制,并利用K-means聚类的方法在训练集中聚类计算出更好的Anchor模板,大大提高了算法的召回率;
(2)同时结合图像细粒度特征,将浅层特征与深层特征相连,有助于对小尺寸目标的检测。
特点:折中,可以自己平衡速度和准确率
改进:batch normalize(BN):加速收敛,正则化模型,可以去掉dropout,map提升2%
Convolutional with Anchor Boxs:相比于v1每张图预测98个预测框,anchor boxes可以预测1000个
Dimension Clusters:anchor遇到的第一个问题 需要动手设定模板框prior 使用k-means聚类折中取得k=5
Direct location prediction:第二个问题 box预测(x,y)位置时,模型不稳定。直接预测对于网格单元的相对位置。w和h通过bbox prior调整 。模型提高5%
Fine-Grained Features:添加passthough层,从26×26的分辨率得到特征
multi-scale training:用多种分辨率的输入图片进行训练
darknet-19:backbone使用darknet-19搭配BN加速收敛
YOLOv3结构框图
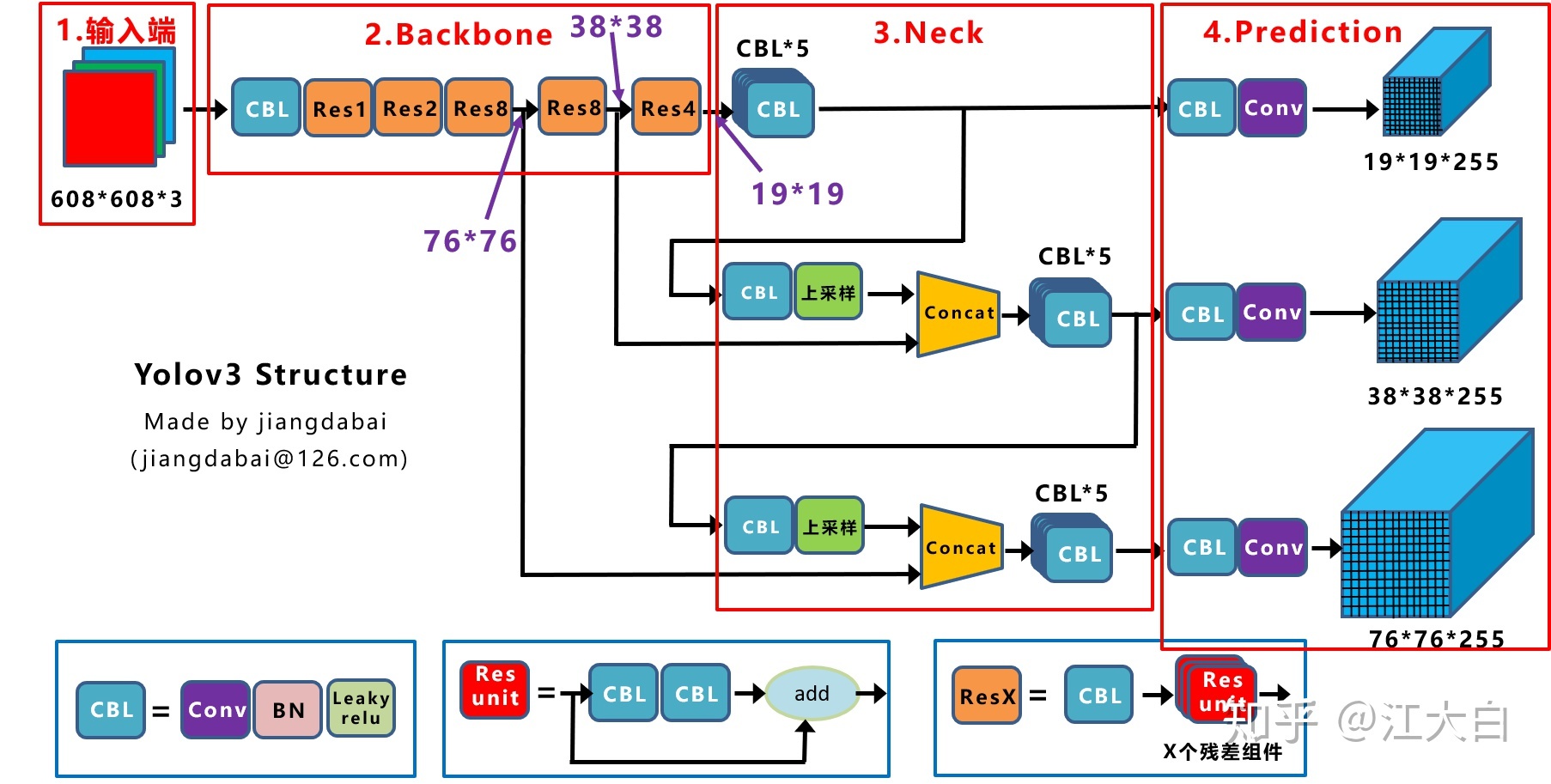
CBL:最小组件Conv+BN+Leaky Relu激活函数组成
Res unit:借鉴Resnet残差结构,网络更深
ResX:CBL+n个Res unit,CBL用来下采样 608-->304-->152-->76-->38-->19 1/32
Concat:张量拼接;
add:张量相加,纬度不变=shortcut
Backbone:每个ResX包含1+2*X个卷积层,Darknet=1+(1+2×2)+(1+2×8)+(1+2×8)+(1+2×4)+FC全连接层(不包含)=53
改进点:predictions across scales:输出三种不同尺度的 feature map。深度255原因:coco80个类别,每个单元需要3个box,每个box还需要五个位置参数,3×(5+80)=255
v3对bbox预测时采用logistic regression可以去掉不必要anchor。
YOLOv4结构框图
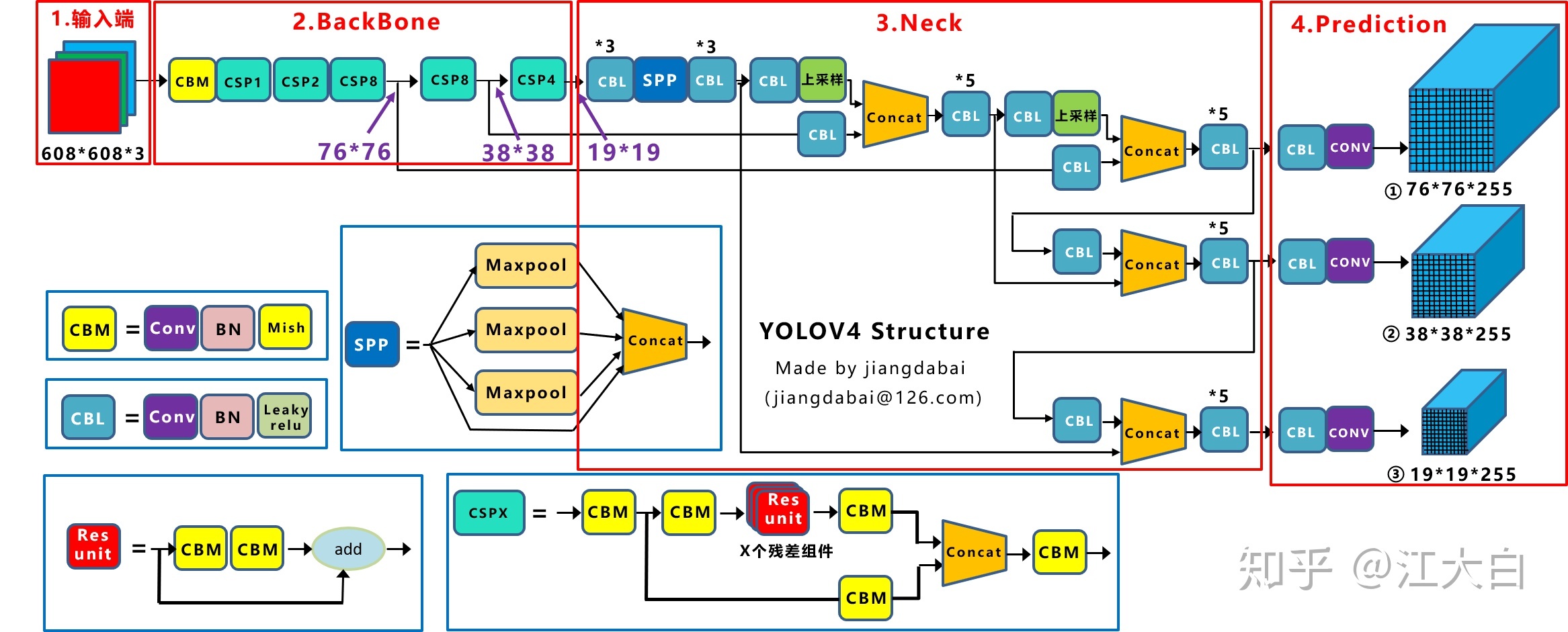
组件:
CBM:最小组件Conv+Bn+Mish激活函数
CBL:Conv+Bn+Leaky_relu
Res_unit:Resnet网络中的残差结构
CSPX:借鉴CSPNet网络,由卷积层和X个Res_unit模块Concate组成
SPP:采用1×1,5×5,9×9,13×13的最大池化方式,多尺度融合。通过最大池化将不同尺寸的输入图像变得尺寸一致,使得输入图像不再限制于固定尺寸,增大感受野。
Backbone:每个CSPX包含5+2*X个卷积层,1+(5+2×1)+(5+2×2)+(5+2×8)+(5+2×8)+(5+2×4)=72
创新点:
输入端:Mosaic数据增强、cmBN、SAT自对抗训练
BackBone主干网络:CSPDarknet53、Mish激活函数、Dropblock缓解过拟合
Neck:SPP模块(有效的增加主干特征的接收范围,显著的分离了最重要的上下文特征)、FPN+PAN结构
Prediction:训练时的损失函数CIOU_Loss、预测框筛选的nms变为DIOU_nms
**IOU_Loss:**主要考虑检测框和目标框重叠面积。
**GIOU_Loss:**在IOU的基础上,解决边界框不重合时的问题。
**DIOU_Loss:**在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
**CIOU_Loss:**YOLOv4采用CIOU_Loss,在DIOU的基础上,考虑边界框宽高比的尺度信息。
Mosaic数剧增强:随机缩放、随机裁剪、随机排布的方式进行拼接。均衡小中大三类目标
BackBone:608->304->152->76->38->19 CSPNet将基础层的特征映射划分为两部分,通过跨阶段层次结构将其合并,减少计算量保证准确率。
FPN层自顶向下传达强语义特征 ,而特征金字塔则自底向上传达强定位特征,
深度学习backbone汇总
非轻量化:
LeNet5:(1998)
AlexNet:(2012)
VGG:(2014)
GoogLeNet(InceptionNet)系列:Inception-v1(GoogleNet): (2015)、Inception-v2 (2015,BN-inception)、Inception-v3 (2015)、Inception-v4: (2017)、Inception-resnet-v2: (2017)
Resnet: (2016)
ResNet变种:ResNeXt (2016)、ResNeSt(2020)、Res2Net(2019)、DenseNet (2017)
DPNet:(2017)
NasNet:(2018)
SENet及其变体SKNet:SENet(2017)、SKNet(2019)
EfficientNet 系列:EfficientNet-V1(2019)、EfficientNet-V2(2021)
Darknet系列:Darknet-19 (2016, YOLO v2 的 backbone)、Darknet-53 (2018, YOLOv3的 backbone)
DLA (2018, Deep Layer Aggregation)
轻量化:
SqueezeNet:(2016)
MobileNet-v1:(2017)
XCeption:(2017, 极致的 Inception)
MobileNet V2:(2018)
ShuffleNet-v1:(2018)
ShuffleNet-v2:(2018)
MnasNet:(2019)
MobileNet V3 (2019)
CondenseNet(2017)
ESPNet系列:ESPNet (2018)、ESPNetv2 (2018)
ChannelNets
PeleeNet
IGC系列:IGCV1、IGCV2、IGCV3
FBNet系列:FBNet、FBNetV2、FBNetV3
GhostNet
WeightNet
MicroNet
ViT(Vision Transformer )Backbone结构
ViT-H/14 和 ViT-L/16(2020)(Vision Transformer,ViT)
Swin Transformer(2021)
PVT(2021, Pyramid Vision Transformer)
MPViT (CVPR 2022,Multi-path Vision Transformer, 多路径 Vision Transformer)
EdgeViTs (CVPR 2022,轻量级视觉Transformer)
(CNNs+Transformer / Attention)Backbone结构
CoAtNet(2021)
BoTNet(2021)
YOLOv5结构框图
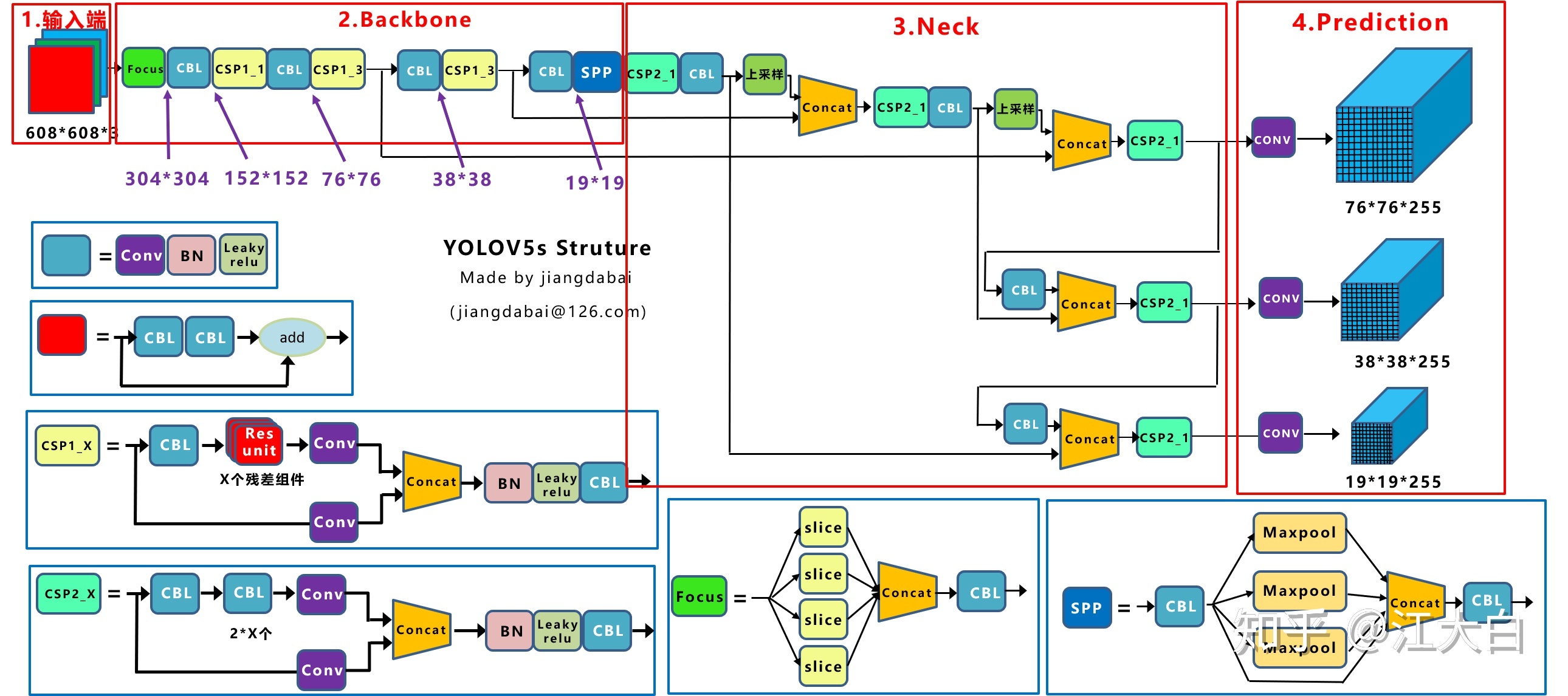
输入端 :Mosaic数据增强(随机缩放 、随机裁剪 、随机排布 的方式进行拼接)、自适应锚框计算(初始设定长宽的锚框)、自适应图片缩放 trick(datasets.py的letterbox函数)对原始图像添加最少的黑边减少冗余 结果显著,训练未采用,预测采用
Backbone:Focus结构:切片操作,将608×608×3-->304×304×12
CSP结构:YOLOv4借鉴CSPNet网络,YOLOv5的CSP2应用在Neck上加强网络特征融合能力
CSP是由n和gd控制的,n = n_ = max(round(n * gd), 1) if n > 1 else n
Neck:FPN+PAN结构
Prediction:GIOU_Loss DIOU_nms对重叠框有所改进
YOLOv7
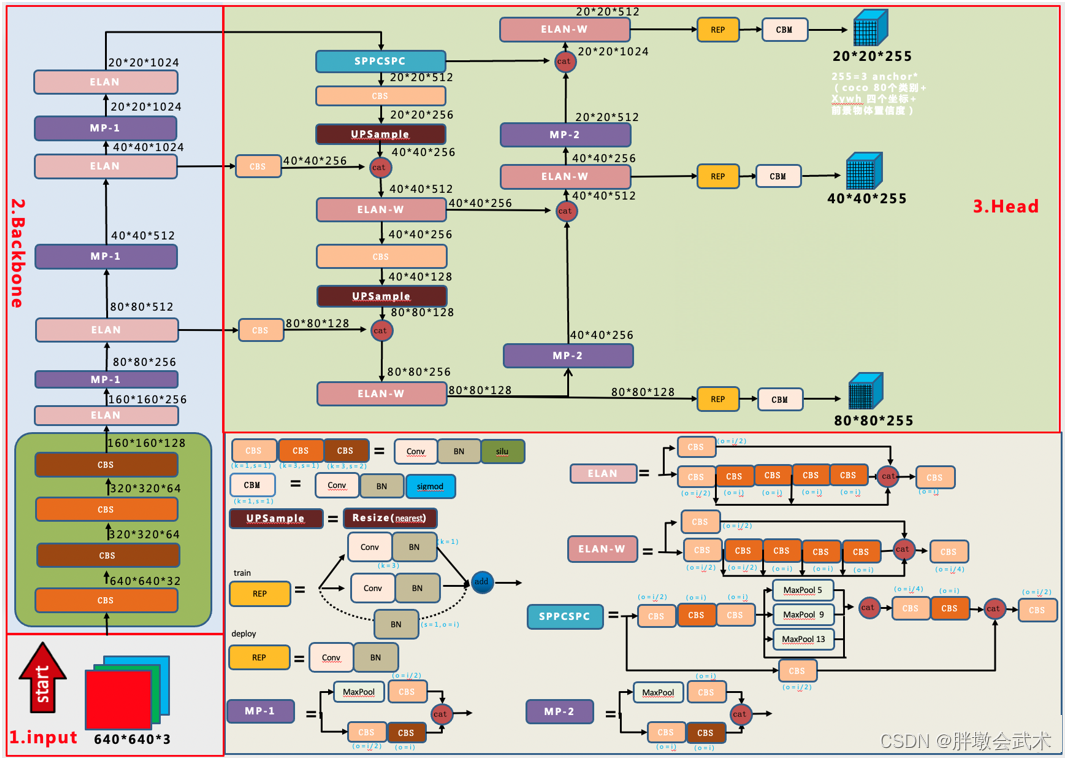
改进点:
RepVGG(2021):RepVGG无论是在精度还是速度上都已经超过了 ResNet、EffcientNet 以及 ResNeXt 等网络。采用结构重参数化,(1)训练时,使用ResNet-style的多分支模型(特点:增加模型的表征能力)(2)测试时,转化成VGG-style的单线路模型(特点:速度更快、更省内存并且更加的灵活)
将BN和3x3卷积进行融合,转换成3x3卷积:将BN公式拆解为 一元二次方程(y1 = k1* x1 + b1);然后与损失函数(y2 = k2* x2 + b2)进行合并得到新的方程(y3 = k3* x3 + b3)。
多分支融合:将1x1卷积 + BN全部转换为3x3卷积,然后与3x3卷积进行合并,得到一个3x3卷积。
YOLOv8
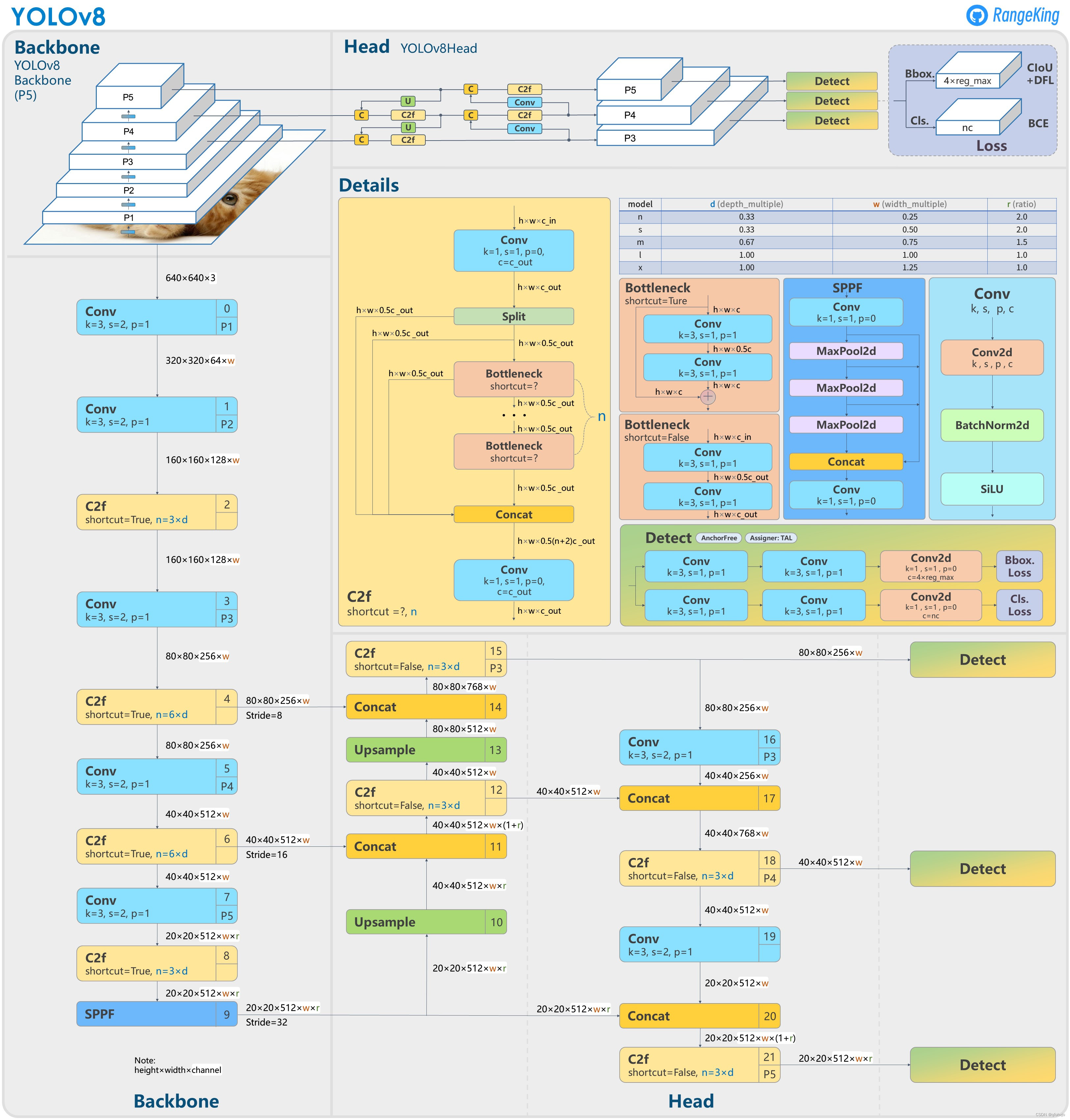
Backbone:轻量化C2f替换了C3
PAN-FPN:删除YOLOv5上采样阶段中的卷积结构,C2f替换了C3
Decoupled---Head
Anchor-Free
损失函数:VFL Loss作为分类损失,DFL Loss+CIOU Loss
样本匹配:Task-Aligned Assigner
Backbone:轻量化C2f替换了C3
PAN-FPN:删除YOLOv5上采样阶段中的卷积结构,C2f替换了C3
Decoupled---Head
Anchor-Free
损失函数:VFL Loss作为分类损失,DFL Loss+CIOU Loss
样本匹配:Task-Aligned Assigner