完整代码Python爬取豆瓣电影详情数据
引言
在数据科学和网络爬虫的世界里,豆瓣电影是一个丰富的数据源。在本文中,我们将探讨如何使用Python语言,结合requests和pyquery库来爬取豆瓣电影的详情页面数据。我们将通过一个具体的电影详情页面作为例子,一步步解析并提取我们感兴趣的信息。
完整代码放到最后!!!完整代码放到最后!!!完整代码放到最后!!!
环境准备
在开始之前,请确保您的环境中已安装以下Python库:
requests:用于发送HTTP请求。pyquery:使HTML文档的查询变得简单,类似于jQuery。re:Python的正则表达式库,用于文本匹配和提取。
您可以通过以下命令安装所需的库:
bash
pip install requests pyquery爬虫步骤概览
我们的爬虫任务分为三个主要步骤:
- 发送HTTP请求:获取目标网页的内容。
- 解析HTML :使用
pyquery提取页面中的数据。 - 数据提取与处理:将提取的数据转换为所需的格式。
详细代码实现
第一步:发送HTTP请求
我们首先构造一个函数getMovieInfoByUrl,它接受一个电影详情页面的URL作为参数,并发送GET请求获取页面内容。
python
import requests
from pyquery import PyQuery as pq
import re
from pprint import pprint
def getMovieInfoByUrl(detailUrl):
movieInfo = {}
headers = {
# 请求头,伪装成浏览器访问
}
response = requests.get(detailUrl, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
# ...第二步:解析HTML
使用pyquery解析响应文本,提取页面中的元素。
python
doc = pq(response.text)
# ...第三步:数据提取与处理
根据页面结构,提取电影的年份、描述、主要信息等,并进行适当的处理。
python
movieInfo['release_year'] = re.findall(r'\d+', doc("#content h1 .year").text())[0]
movieInfo['movie_desc'] = doc("#link-report-intra .all").text()
# ...正则表达式的应用
在提取信息时,我们使用正则表达式来匹配和分割文本。例如,我们使用正则表达式来分割<br/>标签,并提取关键的电影信息。
python
content_list = re.split(r'<br/>', info_items_html_content)
regex_pattern = re.compile(r'(.*?):\s(.*?)(?:\n|$)')
for content in content_list:
# ...映射中文键到英文键
为了方便后续处理,我们将中文键映射到英文键。
python
key_mapping = {
# 中文键到英文键的映射
}
for key, value in extracted_info.items():
if key in key_mapping:
movieInfo[key_mapping[key]] = value结果展示
最后,我们打印出提取的电影信息。
python
pprint(movieInfo)
return movieInfo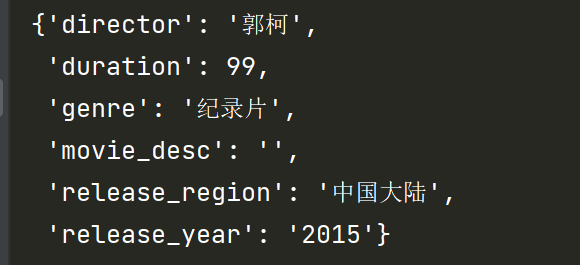
总结
在本文中,我们学习了如何使用Python爬取豆瓣电影详情页面的数据。我们通过分析网页结构,使用requests和pyquery提取了页面中的关键信息,并使用正则表达式对信息进行了处理和格式化。希望这篇文章能帮助您入门网络爬虫,并激发您探索更多数据获取和处理的方法。
完整代码
python
# 豆瓣电影详情也爬数据
import requests
from pyquery import PyQuery as pq
import re
from pprint import pprint
import time
# 第一步,请求详情页面拿到响应
# 第二步, 根据响应 + pyquery 解析dom拿到对应节点文本
# 第三步,处理文本为想要的数据形式。
def getMovieInfoByUrl(detailUrl):
movieInfo = {}
# 定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
# 其他需要的请求头...
}
# 发送 GET 请求并获取响应内容
response = requests.get(detailUrl, headers=headers)
# 确保请求成功
if response.status_code == 200:
doc = pq(response.text)
movieInfo['release_year'] = re.findall(r'\d+', doc("#content h1 .year").text())[0]
movieInfo['movie_desc'] = doc("#link-report-intra .all").text()
#======处理 info 标签信息
info_items_doc = doc("#content #info")
info_items_html_content = info_items_doc.html()
# 根据<br>标签划分内容
content_list = re.split(r'<br/>', info_items_html_content)
extracted_info = {}
# 定义正则表达式模式
regex_pattern = re.compile(r'(.*?):\s(.*?)(?:\n|$)')
# 输出划分后的内容
for content in content_list:
info_item_doc = pq(f'<div>{content}<div>')
info_item_text = info_item_doc.text()
match = regex_pattern.match(info_item_text)
if match:
extracted_info[match.group(1)] = match.group(2)
# print("extracted_info",extracted_info)
# 映射中文键到英文键
key_mapping = {
'主演': 'leading_actor',
'制片国家/地区': 'release_region',
'导演': 'director',
'片长': 'duration',
'类型': 'genre',
}
for key,value in extracted_info.items():
if key in key_mapping:
movieInfo[key_mapping[key]] = value
movieInfo['duration'] = int(movieInfo['duration'].split('分钟')[0])
#======处理 info 标签信息
pprint(movieInfo)
else:
print(f"请求失败,状态码:{response.status_code}")
return movieInfo