一种新的2D维度的bev特征提取方案,其通过引入相机先验信息(相机内参和外参)构建了一个多视图交叉注意力机制,能够将多视图特征映射为BEV特征。
cross view attention:BEV位置编码+由根据相机标定结果(内参和外参)演算得到的相机位置编码+多视图特征做attention得到
整体上文章的网络前端使用CNN作为特征抽取网络,中端使用CNN多级特征作为输入在多视图下优化BEV特征(也就是使用了级联优化),后端使用CNN形式的解码器进行输出
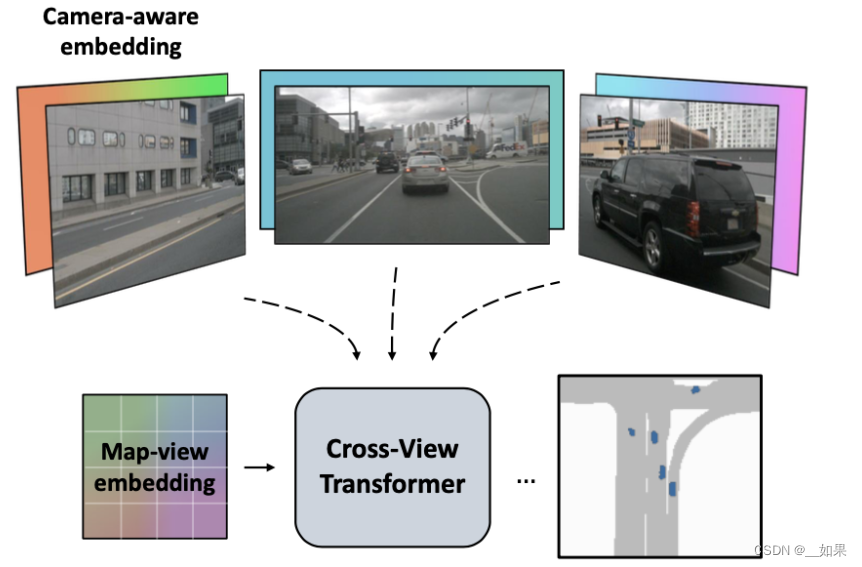
q:bev下加上map-view embedding进行refine
k:在多视图特征(由CNN网络得到)上也会添加camera-view的embedding进行refine
v:原多视图特征也会经过线型映射

为了感知道路的3D位置几何关系还对相机位置进行embedding(代码中为减去操作),并与上述的两种embedding进行关联
因为不知道实际的深度值,所以存在scale上的不确定性。与LSS不同,在这篇文章中并没有显式使用深度信息或者是隐式编码深度空间分布,而是将scale上的不确定性编码使用上述提到的camera-view embedding、map-view embedding和transformer网络进行学习和适应