论文链接 : https://sci-hub.se/https://dl.acm.org/doi/10.1145/2458523.2458525
PPT 讲解: https://pdfs.semanticscholar.org/c067/3245ededf856e793b052e3b8cac69ef2c5d5.pdf
0. 前置知识
- PDOM Re-convergence Model : https://sci-hub.se/https://dl.acm.org/doi/10.1145/2458523.2458525
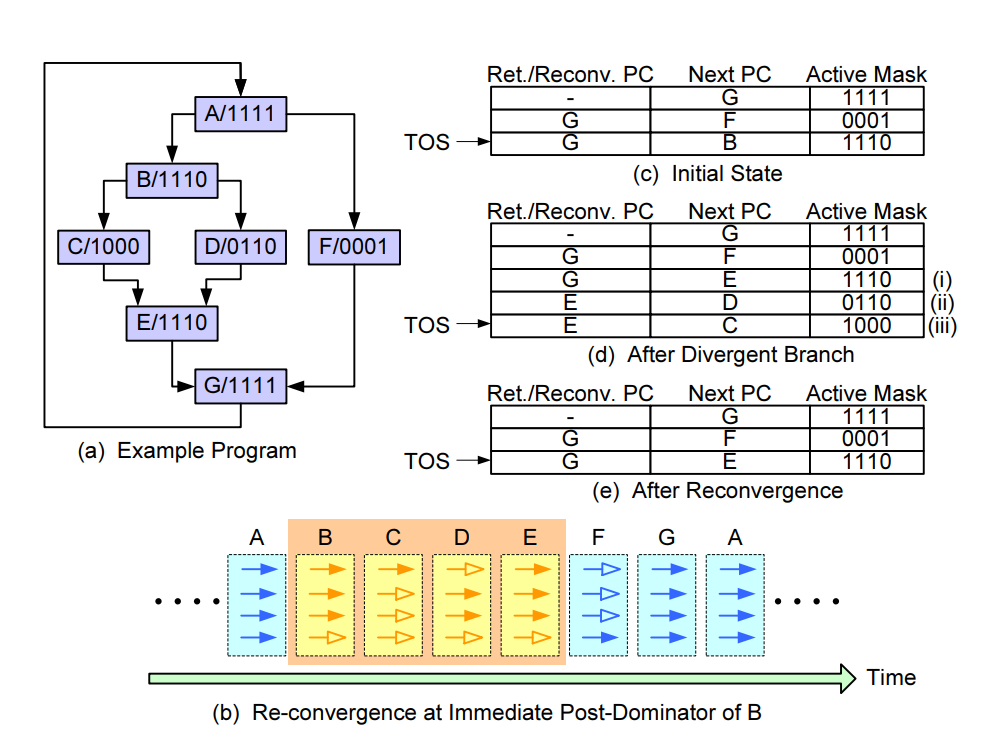
- CUDA SASS Control Manage :
- 扩展阅读:
- https://blog.csdn.net/weixin_43258309/article/details/152329756?spm=1001.2014.3001.5502
- https://www.irisa.fr/alf/downloads/collange/cours/ada2020_gpu_2.pdf

1. 一段话总结
分支发散 会给GPGPU程序带来严重性能损耗,尤其当线程束内线程的循环迭代次数(trip-count)不同时,线程需等待迭代次数最多的线程,形成"循环诱导发散"。为此,研究提出循环合并(Loop Merging, LM) 软件优化:将内层发散循环与一个或多个外层循环合并为单个循环,避免线程在每次外层循环迭代中相互等待,提升SIMD执行效率。该优化在LLVM中实现,泛化性优于传统循环合并(Loop Coalescing) (支持非完美嵌套、while循环及循环间控制流);在Fermi GPU(NVIDIA Geforce GTX 480)上的评估显示,合成基准性能提升最高达1.6× ,5个应用基准(如MCX、GPU-MCML)最高达4.3×,且在无潜在收益场景下(如MO基准)仅造成2%性能损耗,无显著性能降解。

2. 思维导图(mindmap)
- 研究背景与问题
- GPGPU定位:HPC核心平台,需针对性优化
- 性能瓶颈:①内存性能(传统焦点);②分支发散(日益突出)
- 分支发散机制:GPU处理发散的3种硬件谓词机制(分支谓词、收敛预检查、谓词栈+PDOM重收敛模型)
- 核心问题:循环诱导发散(线程束内循环迭代次数差异导致线程等待)
- 循环合并(LM)优化
- 核心思想:合并内层发散循环与外层循环,消除"外层迭代等待",紧凑SIMD调度
- 代码转换:将嵌套循环(含外层前序/后序代码、内层前序/后序/循环体)转为单循环,含"循环体"和"过渡代码"分支
- 影响因素:①内层循环迭代次数方差;②合并后循环迭代次数方差;③过渡代码发散penalty;④内存合并退化;⑤动态指令开销
- 适用性与合法性:①无显式/隐式同步;②内层循环出口不超出外层循环;不改变线程计算顺序(合法)
- 编译器实现
- 框架:LLVM中端Pass,Clang前端扩展编译器指令(
#pragma merge loop(N)) - CUDA编译流程:Clang→NVVM IR(含LM注解)→LM Pass→NVPTX后端→PTX代码→C++包装器编译
- 框架:LLVM中端Pass,Clang前端扩展编译器指令(
- 实验评估
- 实验平台:Intel Core i7-960 CPU + NVIDIA Geforce GTX 480 GPU(6GB内存),CUDA 5.0,Ubuntu 10.04
- 合成基准(SYN-LM):5个参数(OUTER_TC、INNER_TC_AVG等),结果显示LM提速受迭代次数方差、循环体大小影响(方差越高/循环体越大,提速越显著)
- 应用基准(5个):MCX(光子模拟)、GPU-MCML(2D光子传输)、MC-GPU(X射线传输)、MUMmerGPU(DNA比对)、MO(分子轨道),平均提速1.0×-4.3×
- 相关工作
- 与Loop Coalescing对比:LM支持非完美嵌套/while循环/CFG层面,后者仅适用于完美嵌套/特定场景(如稀疏矩阵)
- 其他降发散方法:软件(迭代延迟、分支分布、循环迭代重排序);硬件(Thread Frontier、动态线程束形成DWF)
- 结论与未来方向
- 结论:LM有效减少循环诱导发散,最高提速4.3×,泛化性强,性能损耗低
- 未来方向:①自动化选择目标循环(编译时+运行时启发式);②探索运行时重收敛点调整机制
3. 详细总结
1. 研究背景与核心问题
GPGPU是HPC的核心平台,但性能需匹配其SIMD架构特性,主要瓶颈包括内存性能 (传统优化焦点)和分支发散(线程束内线程执行路径差异,日益突出)。
- 分支发散的危害:线程束(32个线程)需同步执行,发散时需遍历所有分支路径,导致核心利用率下降(如无偏分支仅50%利用率)。
- GPU处理发散的3种机制 (基于硬件谓词):
- 分支谓词(BP):then/else路径分别用谓词P/!P标记,线程遍历所有路径,效率低;
- 谓词+收敛预检查:增加
BRA.U指令跳过无线程执行的路径,减少冗余,但增加指令开销; - 谓词栈+PDOM重收敛模型:用栈存储子线程束的PC和谓词掩码,在分支的立即后支配点(IPDOM)重收敛,支持嵌套分支/循环。
- 关键问题:循环诱导发散:当线程束内线程的循环迭代次数(trip-count)不同时,所有线程需等待迭代次数最多的线程,且该问题在嵌套循环中会随外层迭代次数放大(每次外层迭代均需等待)。
2. 循环合并(Loop Merging, LM)优化设计
2.1 核心思想
将内层发散循环 与一个或多个外层循环合并为单个循环,使线程完成当前内层迭代后直接进入下一个外层迭代的内层循环(无需等待其他线程完成当前外层迭代),紧凑SIMD执行调度,减少等待间隙。
2.2 代码转换示例
| 原始嵌套循环(图3a) | 合并后循环(图5a) |
|---|---|
| 1. 外层前序代码(outer_prologue) 2. 外层循环(while <outer_cond_expr>) 2.1 内层前序代码(inner_prologue) 2.2 内层循环(while <inner_cond_expr>):执行inner_loop_body 2.3 内层后序代码(inner_epilogue) 3. 外层后序代码(outer_epilogue) | 1. 外层前序代码(outer_prologue) 2. 检查外层条件(if <outer_cond_expr>) 2.1 合并循环(do-while outer_cond) 2.1.1 若内层条件成立:执行inner_loop_body 2.1.2 若内层条件不成立:执行inner_epilogue → 检查并更新outer_cond → 执行下一轮inner_prologue 3. 外层后序代码(outer_epilogue) |
2.3 影响LM效果的5个关键因素
| 因素 | 作用机制 |
|---|---|
| 内层循环迭代次数方差 | 方差越高,原始调度的"等待间隙"越大,LM收益越显著;方差为0时LM无收益(反而有9%损耗) |
| 合并后循环迭代次数方差 | 方差越高,LM的收益上限越低(线程仍需等待总迭代次数最多的线程) |
| 过渡代码发散penalty | 与"过渡代码发散度""执行频率""代码长度/内层循环体长度比"正相关;最坏时过渡代码执行慢32倍 |
| 内存合并退化 | 若原始代码内存合并度低(如MCX仅0.8%),退化影响小;合并度高(如GPU-MCML达93%)需关注,但实验中内存事务增加≤6.7% |
| 动态指令开销 | 每合并迭代增加1个分支基本块(约3条指令),导致动态指令数增加5%,IPC略有下降 |
2.4 适用性与合法性
- 适用场景 :2个及以上嵌套自然循环,满足:①无显式/隐式同步(如
syncthreads);②内层循环出口不超出外层循环。 - 合法性:不改变单个线程的计算顺序(仅重新对齐线程间执行调度),因此始终合法。
3. 编译器实现(基于LLVM)
- 实现位置:LLVM中端Pass,直接操作控制流图(CFG),适配LM的CFG转换需求。
- 编译器指令 :扩展Clang前端,支持
#pragma merge loop(N)(N为需合并的外层循环数量,标注于内层循环前)。 - CUDA编译流程 :
- 带LM注解的CUDA内核 → Clang → NVVM IR(含LM注解);
- LM Pass处理NVVM IR,完成循环合并;
- NVPTX后端生成PTX代码;
- 自动生成C++内核包装器,与主机代码一起编译。
4. 实验评估
4.1 实验平台
| 组件 | 配置 |
|---|---|
| CPU | Intel Core i7-960 |
| GPU | NVIDIA Geforce GTX 480(Fermi架构) |
| 内存 | 6GB主存 |
| 软件 | CUDA 5.0,Ubuntu 10.04,LLVM+NVPTX后端 |
| 性能指标 | 内核加速比(无LM执行时间 / 有LM执行时间) |
4.2 合成基准(SYN-LM)
-
参数设计 (控制影响LM的关键特性):
参数 描述 OUTER_TC 外层循环迭代次数(线程间恒定) INNER_TC_AVG 内层循环迭代次数平均值 INNER_TC_VAR 内层循环迭代次数方差(0-10,控制发散程度) INNER_SIZE 内层循环体指令数(FMA操作) EP_SIZE 内层后序代码(epilogue)指令数 -
关键结果 :
- 当INNER_TC_VAR>0时,提速随方差线性增加(OUTER_TC=1000时,方差10对应提速1.5×);
- 提速随INNER_TC_AVG增加而提升(边际效益递减,因过渡代码执行频率降低);
- INNER_SIZE越大,提速越显著(相比INNER_TC_AVG,无循环开销放大,峰值提速高10%);
- INNER_TC_VAR=0时,LM造成9%损耗(指令开销+IPC下降)。
4.3 应用基准(5个,覆盖不同场景)
-
基准特性与LM效果 :
基准 应用场景 内层循环体大小 过渡代码大小 内层迭代次数标准差 内存加载效率 LM加速比(平均-最高) MCX 3D光子散射模拟 800 30 269 0.8% 1.8×-4.3× GPU-MCML 2D光子传输模拟 300 20 975 93% 1.5×-3.8× MC-GPU X射线传输模拟 2700 860 11 3.8% 1.0×-1.4× MUMmerGPU DNA序列比对 120 40 1.2 2.3% 1.0×-1.24× MO 分子轨道计算 160 20 0 100% 0.98×(仅2%损耗) -
关键结论:LM在"高发散度+大循环体/过渡代码比"场景(如MCX、GPU-MCML)收益最高;无循环诱导发散时(MO)损耗极小。
5. 相关工作对比
| 技术 | 核心特点 | 与LM的区别 |
|---|---|---|
| Loop Coalescing(传统循环合并) | 仅支持完美嵌套循环、显式索引变量,用于提升并行性/减少同步 | LM支持非完美嵌套、while循环、循环间控制流,可在CFG层面应用,适用范围更广(5个应用基准均不支持传统方法) |
| 软件优化(迭代延迟、分支分布) | 针对分支发散,不处理循环诱导发散 | LM专门针对循环迭代次数差异导致的发散 |
| 硬件优化(Thread Frontier、DWF) | 需GPU硬件扩展,支持更早重收敛/动态线程束重组 | LM是纯软件优化,无需硬件改动,兼容性强 |
6. 结论与未来方向
- 结论:LM是高效的纯软件优化,可减少GPGPU循环诱导发散,最高提速4.3×,泛化性优于传统方法,性能损耗可控。
- 未来方向:①开发编译时+运行时启发式,自动选择LM的目标循环;②探索运行时动态调整重收敛点的机制。
4. 关键问题
问题1:循环合并(LM)与传统的Loop Coalescing(循环合并)在适用场景和能力上的核心差异是什么?该差异为何使LM能应用于文档中的5个应用基准,而Loop Coalescing不能?
答案 :二者核心差异体现在3个方面:①循环结构支持 :LM支持非完美嵌套循环(允许内层前序/后序代码)、while循环(无显式索引变量)及循环间控制流;Loop Coalescing仅支持完美嵌套的DO循环(无循环间代码),且依赖显式索引变量。②应用层面 :LM可在控制流图(CFG)层面实现,适配复杂控制流(如嵌套分支、早期退出);Loop Coalescing多在源码层面应用,限于规则循环(如稀疏矩阵的三角循环)。③适用场景 :LM针对"循环诱导发散"(线程迭代次数差异),无需循环边界提前可知;Loop Coalescing最初用于减少并行同步开销,后来扩展到内存合并优化,需循环边界可静态分析。
文档中5个应用基准(如MCX、MUMmerGPU)均包含非完美嵌套(如MCX的外层光子迭代+内层模拟步骤循环,含前序随机数生成)、while循环(如MUMmerGPU的后缀树遍历循环)或循环间控制流,不符合Loop Coalescing的完美嵌套/显式索引要求,因此无法应用;而LM的泛化设计使其可适配这些场景。
问题2:影响循环合并(LM)优化效果的最关键因素是什么?结合合成基准(SYN-LM)和应用基准(如MCX、MO)的实验结果,说明该因素如何决定LM的收益上限?
答案 :影响LM效果的最关键因素是内层循环迭代次数的方差(即线程束内线程的内层迭代次数差异程度),它直接决定原始调度中"线程等待间隙"的大小,进而影响LM的收益空间。
- 合成基准(SYN-LM)结果显示:当INNER_TC_VAR=0(无迭代次数差异)时,LM无收益且造成9%性能损耗(指令开销);当INNER_TC_VAR从1增至10时,提速随方差线性增加(OUTER_TC=1000时,方差10对应提速1.5×),因方差越大,原始调度中线程等待时间越长,LM消除等待的收益越显著。
- 应用基准结果印证:MCX(内层迭代次数标准差269)和GPU-MCML(标准差975)的LM加速比最高(分别达4.3×、3.8×),因高方差导致原始调度效率极低;而MO基准(内层迭代次数标准差0,无循环诱导发散)的LM仅造成2%损耗,无收益;MC-GPU(标准差11,低方差)的加速比仅1.0×-1.4×,收益有限。
该因素决定LM的收益上限:若内层迭代次数方差低(或为0),LM无收益空间;若方差高,还需结合"循环体/过渡代码长度比""外层迭代次数"等因素进一步放大收益,但方差是基础前提。
问题3:文档中提到LM是"纯软件优化",无需硬件改动,这一特性在实际GPGPU部署中有何优势?与硬件级降发散技术(如Thread Frontier、DWF)相比,LM在兼容性和实用性上有何特点?
答案 :LM作为纯软件优化的核心优势是兼容性广 和部署成本低,具体特点如下:
- 兼容性优势:LM基于LLVM编译器实现,通过标准CUDA编译流程生成PTX代码,可运行于现有GPU架构(如文档中的Fermi,也可扩展至AMD、Intel SIMD架构),无需修改GPU硬件或依赖特定硬件特性(如谓词栈外的额外硬件模块);而硬件级技术(如Thread Frontier需新增重收敛检测硬件,DWF需动态线程束重组模块)仅支持特定架构(如Thread Frontier针对新型GPU),旧架构(如Fermi)无法兼容。
- 实用性优势 :①部署成本低 :用户仅需在代码中添加
#pragma merge loop(N)指令,无需更换硬件或升级驱动;硬件技术需厂商推出新GPU产品,用户需硬件迭代成本。②适配复杂场景 :LM可处理含早期退出、嵌套分支的复杂循环(如MUMmerGPU的后缀树遍历循环),硬件技术(如DWF)虽能动态重组线程束,但对"循环诱导发散"的针对性不足(需线程路径可动态分组,而迭代次数差异导致的等待难以通过分组消除)。③性能损耗可控 :在无收益场景(如MO基准),LM仅造成2%损耗,而硬件技术若未命中优化场景(如无发散代码),可能因硬件模块 overhead 导致性能下降,且无法通过软件开关关闭。
综上,LM在现有GPU生态中更易落地,尤其适合无法升级硬件的场景(如数据中心旧GPU集群),而硬件技术需长期架构迭代才能普及。