
2024.10
1.摘要
background
多模态大型语言模型(MLLMs)在理解和分析视频内容方面取得了显著进展。然而,处理长视频时,受限于LLM的上下文大小,仍然是一个重大挑战,导致现有方法难以有效处理和理解长时间视频,尤其是在视频内容不均匀的情况下(例如,静态与动态场景)。
innovation
为了解决这一限制,本文提出了 LongVU ,一种时空自适应压缩机制,旨在减少视频token的数量,同时保留长视频的视觉细节。其核心思想是利用跨模态查询和帧间依赖性来自适应地减少视频中的时间冗余和空间冗余。
优点 :
减少冗余 : 通过利用DINOv2特征去除高度相似的冗余帧。
选择性特征缩减 : 利用文本引导的跨模态查询进行选择性帧特征缩减,为与文本查询相关的关键帧保留完整token。
空间token缩减 : 基于时间依赖性对帧进行空间token缩减。
高效处理 : 这种自适应压缩策略能有效处理大量帧,且视觉信息损失极小,适应给定的上下文长度。
性能优越 : LongVU在各种视频理解基准测试中(特别是长达一小时的视频理解任务,如VideoMME和MLVU)始终优于现有方法。
可扩展性 : 即使是轻量级LLM,LongVU也能有效扩展,并提供最先进的视频理解性能。
对比 : 相较于均匀采样(忽略关键帧)和密集采样(容易超出上下文长度导致截断),LongVU能自适应地进行时空压缩,兼顾长视频序列并保留更多视觉细节。与利用密集重采样模块显著减少视觉token数量但导致信息丢失的方法相比,LongVU旨在最大程度地保留帧信息。
- 方法 Method
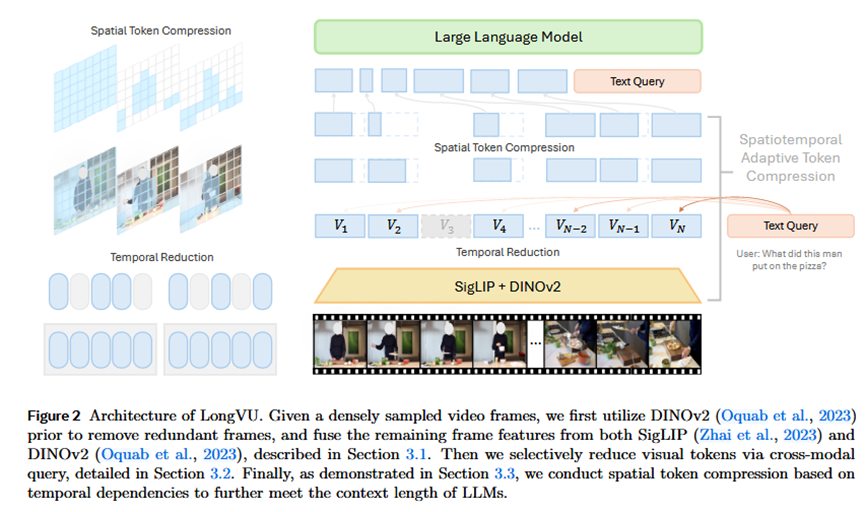
LongVU采用三步时空自适应压缩流程来有效处理长视频:
第一步:帧特征提取器和时间冗余缩减 (Section 3.1):
输入: 密集采样的视频帧序列 I = {I1, ..., IN} (1fps采样)。
过程: 首先使用DINOv2(通过自监督训练在视觉中心任务上捕获细微帧差异和低级视觉特征)从每帧提取特征 Vdino = {Vdino,1, ..., Vdino,N}。然后,在每个大小为 J=8 的不重叠窗口内计算帧之间的平均DINOv2特征相似度 sim,并移除相似度高的冗余帧。
输出: 减少后的 T 帧,大大减少了视频冗余,保留大约一半的视频帧。
补充: 接下来,使用SigLIP(通过视觉-语言对比学习在语义空间中对齐,擅长语言对齐)视觉编码器提取剩余 T 帧的特征 Vsig = {Vsig,1, ..., Vsig,T}。最后,遵循Cambrian的方法,通过空间视觉聚合器(SVA)结合这两种视觉特征,得到融合后的帧特征 V = {V1, ..., VT}。
第二步:基于跨模态查询的选择性特征缩减 (Section 3.2):
输入: 融合后的 T 帧特征 V = {V1, ..., VT} ∈ RT×(Hh×Wh)×Dv,以及文本查询 Q ∈ RLq×Dq。
问题: 如果串联后的帧特征 T × Hh × Wh 超出给定上下文长度 Lmax,则需要进一步压缩。
过程: 提出一种选择性压缩策略。利用文本查询,通过计算帧特征与文本查询之间的跨模态注意力分数,战略性地选择 Nh 帧保持原始token分辨率,而其余帧则进行空间池化以达到较低分辨率。
计算 Nh: Nh = max(0, (Lmax - Lq - THlWl) / (HhWh - HlWl)),其中 Lmax 是上下文长度,F(·) 是将视觉特征与LLM输入空间对齐的多层感知机。
输出: Nh 个保持原始分辨率的帧,以及 T - Nh 个经过空间池化到较低分辨率的帧。
第三步:空间Token压缩 (Section 3.3):
输入: 经过选择性特征缩减后的帧特征。
问题: 即使是低分辨率token的串联视觉特征仍然可能超过 Lmax。
过程: 将帧特征序列划分为大小为 K < T 的不重叠段(滑动窗口)。每个窗口中的第一帧保留其完整的token分辨率。然后计算第一帧与窗口内后续帧之间的余弦相似度。如果空间token的余弦相似度 sim(v1(h, w), vi(h, w)) 大于阈值 θ,则修剪对应的空间token。
优点: 这种方法利用时间依赖性减少空间token,特别适用于视频中静态背景等像素级冗余。选择第一帧作为比较基准,因为它简单有效,且DINOv2已有效减少帧间的视频冗余。
输出: 进一步压缩后的token,以适应LLM的上下文长度。
- 实验 Experimental Results
实验数据集:
图像-语言预训练: LLaVA-OneVision的单图像数据 (3.2M样本)。
视频-语言微调:
来自VideoChat2-IT (Li et al., 2024b) 的子集,包括TextVR (43K 样本)、Youcook2 (43K 样本)。
Kinetics-710 (1K 样本)。
NEXTQA (424K 样本)、CLEVRER (424K 样本)、EgoQA (424K 样本)、TGIF (424K 样本)、WebVidQA (424K 样本)、DiDeMo (424K 样本)。
ShareGPT4Video (85K 样本)。
MovieChat(作为长视频补充)。
每个实验的结论以及为什么要做这个实验:
定量结果 (Table 1):
结论: LongVU在EgoSchema、MVBench、VideoMME和MLVU等多个视频理解基准测试中表现优异,显著优于现有开源视频LLM模型(如VideoChat2、LongVA、LLaVA-OneVision),尤其在VideoMME长视频子集上优势明显(比LLaVA-OneVision高出12.8%)。甚至在MVBench上超越了专有模型GPT4-0。
原因: 证明了LongVU强大的视频理解能力,即使使用较小的训练数据集也能实现显著性能提升。
轻量级模型扩展 (Table 2):
结论: 将LongVU与轻量级LLM Llama3.2-3B结合,在VideoMME长视频子集上比Phi-3.5-vision-instruct高出3.4%。
原因: 验证了LongVU方法在更小规模下也具有有效性。
帧token数量的影响 (Table 3):
结论: 在均匀采样基线中,每帧144个token在VideoMME和MLVU上表现优于64个token,但在EgoSchema上表现较差。每帧144个token虽然保留更多视觉细节,但限制了总帧数(在8k上下文长度下少于60帧)。
原因: 强调了自适应token数量对于在不同视频基准测试中获得更好性能的必要性。
DINOv2 vs. SigLIP (Table 3, Figure 6):
结论: DINOv2特征在时间帧缩减方面比SigLIP特征更有效。DINOv2通过自监督训练专注于视觉中心任务,能有效捕获细微帧差异和低级视觉特征,而SigLIP则更侧重语义对齐。
原因: 验证了DINOv2作为视觉中心特征提取器在时间冗余缩减方面的有用性。
Query引导选择和空间token压缩的消融实验 (Table 3, Table 4):
结论: 引入Query引导的帧选择显著提升了所有基准测试的性能,尤其在MLVU的帧检索任务上。空间token压缩(STC)进一步提升了8k上下文长度内的性能,甚至与16k上下文长度的结果相当或略好。
原因: 证明了Query引导选择和STC在保存关键视觉特征、适应长上下文以及提升模型在复杂
不同空间token压缩策略 (Table 5):
结论: 采用滑动窗口中第一帧作为锚帧进行空间token压缩的策略(LongVU默认)表现略优于采用中间帧或基于帧变化自适应选择锚帧的策略,且压缩率相似。
原因: 验证了默认策略的简洁性和有效性。
时空压缩分析 (Figure 4):
结论: 时间冗余缩减平均保留了约45.9%的帧,空间token压缩平均减少了约40.4%的token。
原因: 直观地展示了LongVU在帧和token层面上的有效压缩能力。
上下文分析:大海捞针 (Needle-In-A-Video-Haystack) 实验 (Figure 5):
结论: LongVU的自适应token压缩机制能显著提高在长达一小时视频中定位"针头"帧的分数。在1k帧的8k上下文长度下,我们的方法能准确解决VQA问题,并随着帧数增加进一步提升VQA准确性。
原因: 证明了LongVU方法在长上下文视频理解方面的优势。
帧级位置编码 (FPE) 的影响 (Table 8, Table 9):
结论: 增加FPE对总体性能影响不大。
原因: 因此,论文决定在默认设置中不包含FPE,以保持模型的简洁性。
- 总结 Conclusion
LongVU是一个新颖的时空自适应压缩方案,能够有效解决长视频理解中LLM上下文长度的限制问题,通过跨模态查询和帧间相似性,在大幅减少视频token的同时保留了丰富的视觉细节。它在多个视频理解基准测试中表现卓越,验证了其优势,并表明即使是基于轻量级LLM(如Llama3.2-3B)也能构建高质量的视频语言理解模型。