参考
经典大数据开发实战(Hadoop &HDFS&Hive&Hbase&Kafka&Flume&Storm&Elasticsearch&Spark)
概念
storm 对于保证消息处理,提供了最少一次的处理保证。最常见的问题是如果元组可以被
重发,可以用于计数吗?不会重复计数吗?
strom0.7.0 引入了事务性拓扑的概念,可以保证消息仅被严格的处理一次。因此可以以完
全精确的、可扩展的、容错的方式处理类似计数这类的情形。
跟分布式 RPC 类似,事务性拓扑也不是 storm 的新特性,而仅仅是在 storm 原语如数据
流、spout、bolt 和拓扑基础上的高层抽象。
案例
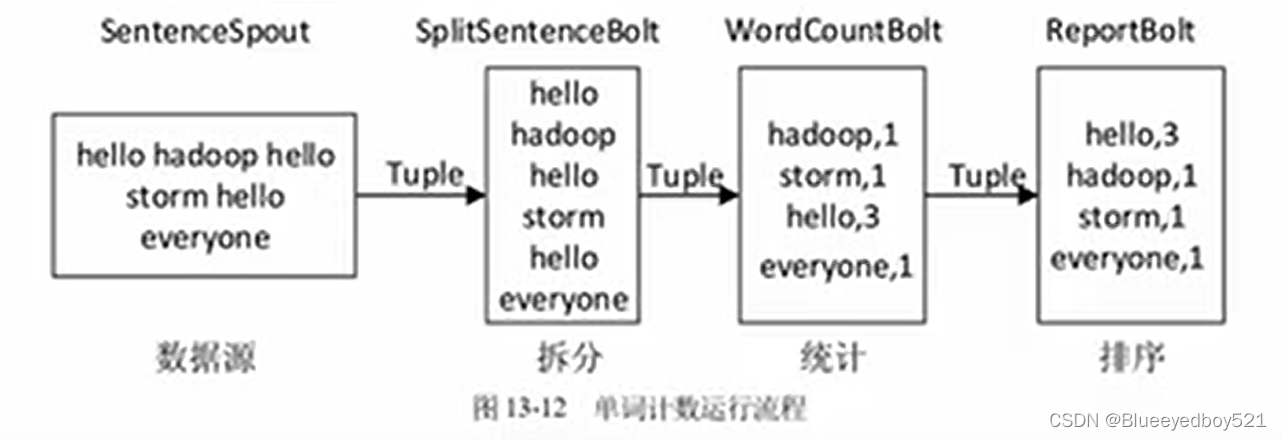
单词计数

依靠 Storm 的实时性以及大规模数据的特点,在 Spout 中随机发送内置的语句作为消息源;使用一个 Bolt 进行语句切分,将句子切分成单词发射出去;使用一个Bolt 订阅切分的单词 Tuple,并且选择使用按字段分组的策略进行单词统计,将统计结果发射出去:最后使用一个Bot订阅统计结果,词频实时排序,把前10个单词打印到log中。整个单词计数统计的流程如图13-12所示。
java实现
引入库
xml
<dependency>
<groupld>org.apache.storm</groupld>
<artifactId>storm-core</artifactId>
<version>2.3.0</version>
<scope>provided</scope>
</dependency>核心代码WordCountTopology
java
public class WordCountTopology {
2
3 private static final Logger log = LoggerFactory.getLogger(WordCountTopology.class);
4
5 //各个组件名字的唯一标识
6 private final static String SENTENCE_SPOUT_ID = "sentence-spout";
7 private final static String SPLIT_SENTENCE_BOLT_ID = "split-bolt";
8 private final static String WORD_COUNT_BOLT_ID = "count-bolt";
9 private final static String REPORT_BOLT_ID = "report-bolt";
10
11 //拓扑名称
12 private final static String TOPOLOGY_NAME = "word-count-topology";
13
14 public static void main(String[] args) {
15
16 log.info(".........begining.......");
17 //各个组件的实例
18 SentenceSpout sentenceSpout = new SentenceSpout();
19 SplitSentenceBolt splitSentenceBolt = new SplitSentenceBolt();
20 WordCountBolt wordCountBolt = new WordCountBolt();
21 ReportBolt reportBolt = new ReportBolt();
22
23 //构建一个拓扑Builder
24 TopologyBuilder topologyBuilder = new TopologyBuilder();
25
26 //配置第一个组件sentenceSpout
27 topologyBuilder.setSpout(SENTENCE_SPOUT_ID, sentenceSpout, 2);
28
29 //配置第二个组件splitSentenceBolt,上游为sentenceSpout,tuple分组方式为随机分组shuffleGrouping
30 topologyBuilder.setBolt(SPLIT_SENTENCE_BOLT_ID, splitSentenceBolt).shuffleGrouping(SENTENCE_SPOUT_ID);
31
32 //配置第三个组件wordCountBolt,上游为splitSentenceBolt,tuple分组方式为fieldsGrouping,同一个单词将进入同一个task中(bolt实例)
33 topologyBuilder.setBolt(WORD_COUNT_BOLT_ID, wordCountBolt).fieldsGrouping(SPLIT_SENTENCE_BOLT_ID, new Fields("word"));
34
35 //配置最后一个组件reportBolt,上游为wordCountBolt,tuple分组方式为globalGrouping,即所有的tuple都进入这一个task中
36 topologyBuilder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(WORD_COUNT_BOLT_ID);
37
38 Config config = new Config();
39
40 //建立本地集群,利用LocalCluster,storm在程序启动时会在本地自动建立一个集群,不需要用户自己再搭建,方便本地开发和debug
41 LocalCluster cluster = new LocalCluster();
42
43 //创建拓扑实例,并提交到本地集群进行运行
44 cluster.submitTopology(TOPOLOGY_NAME, config, topologyBuilder.createTopology());
45 }
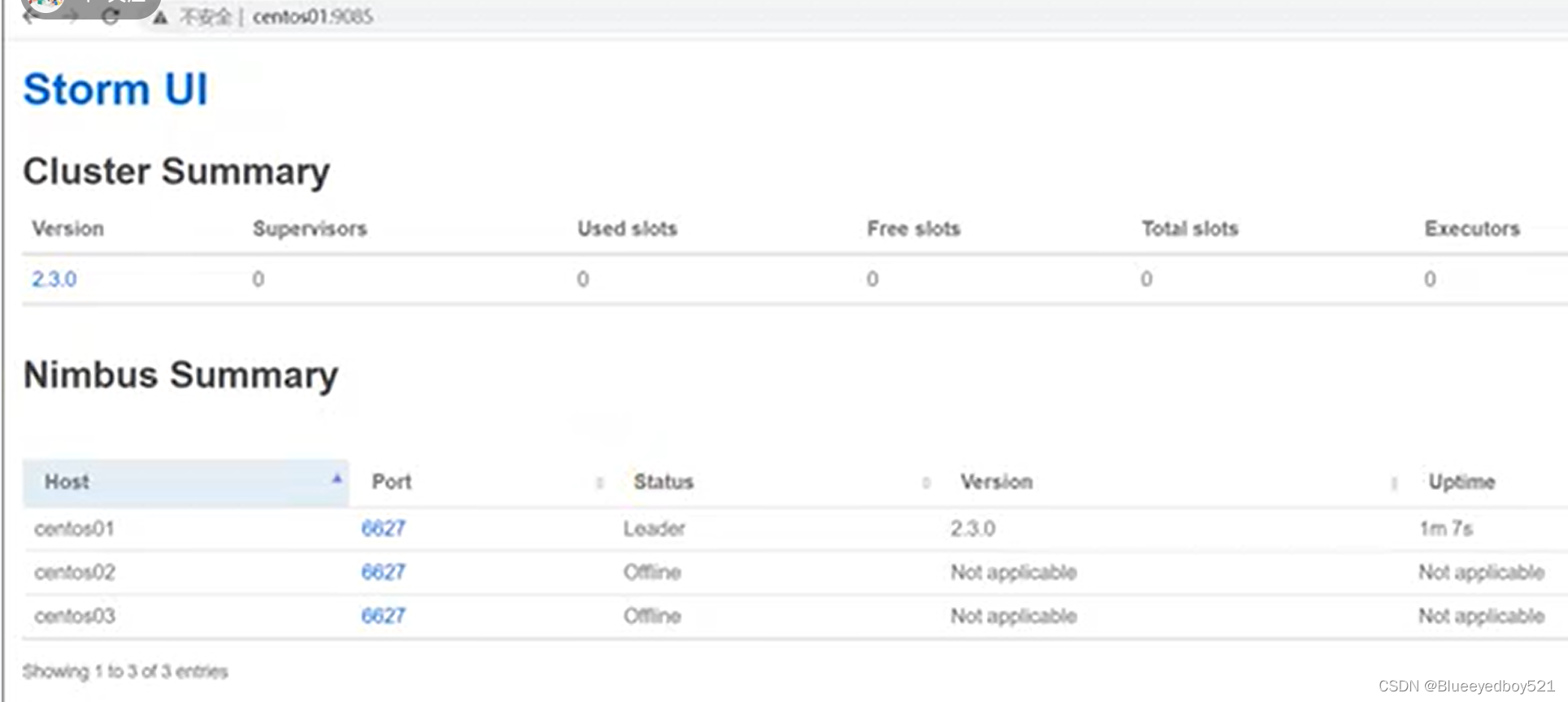
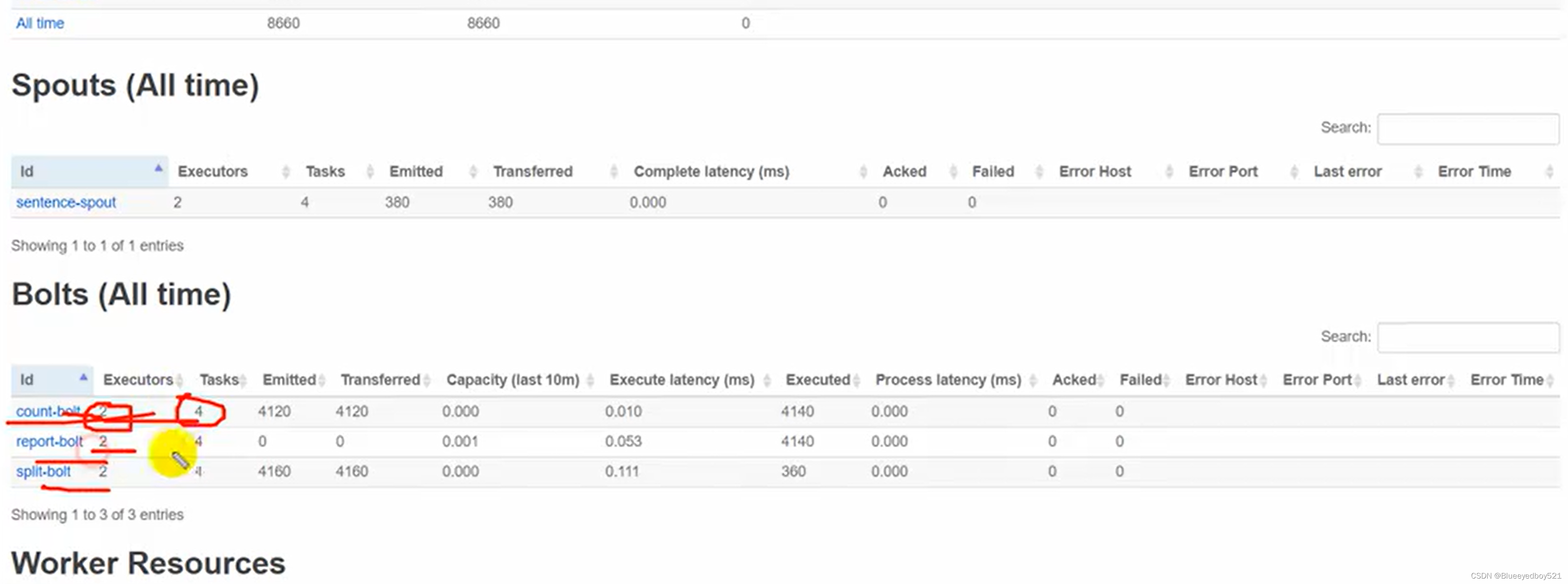
46 }运行情况
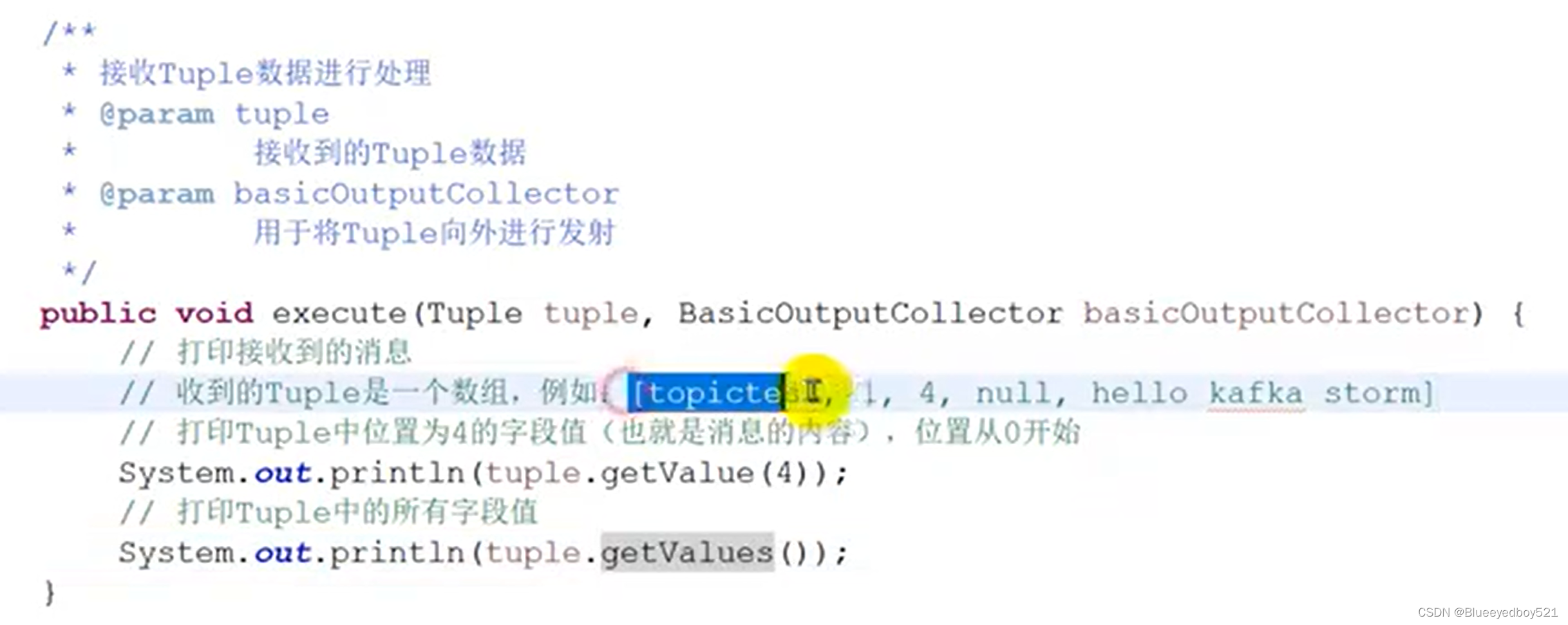
与Kafka整合
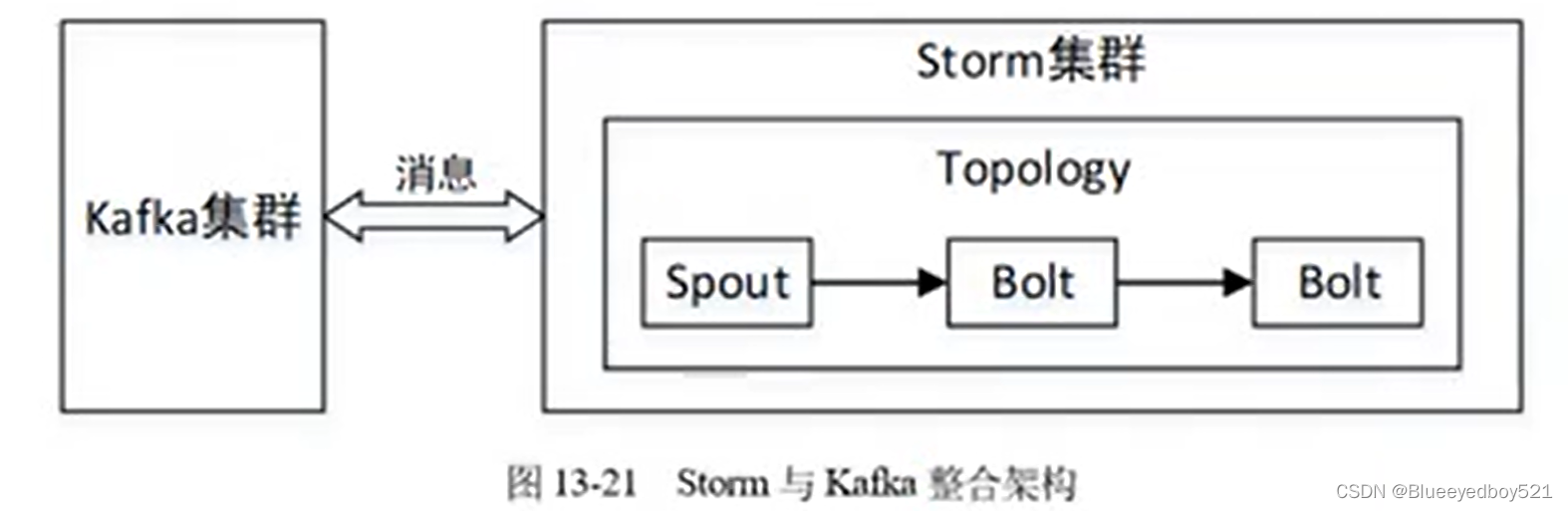
Stom主要用于实时流式计算,而Kafka是一个消息队列。在实际开发中经常将两者结合使用,用 Kafka 缓存消息,并将不均匀的消息转换成均匀的数据流提供给 Stom 进行消费,这样才可以实
现稳定的流式计算。Stom 可以作为Kafka 的生产者,将 Stom 中的每条记录作为消息发送到 Kafka 消息队列中,也可以将 Stom 作为消费者,消费Kafka队列中的消息。Storm与Kafka 整合的架构如图 13-21所不
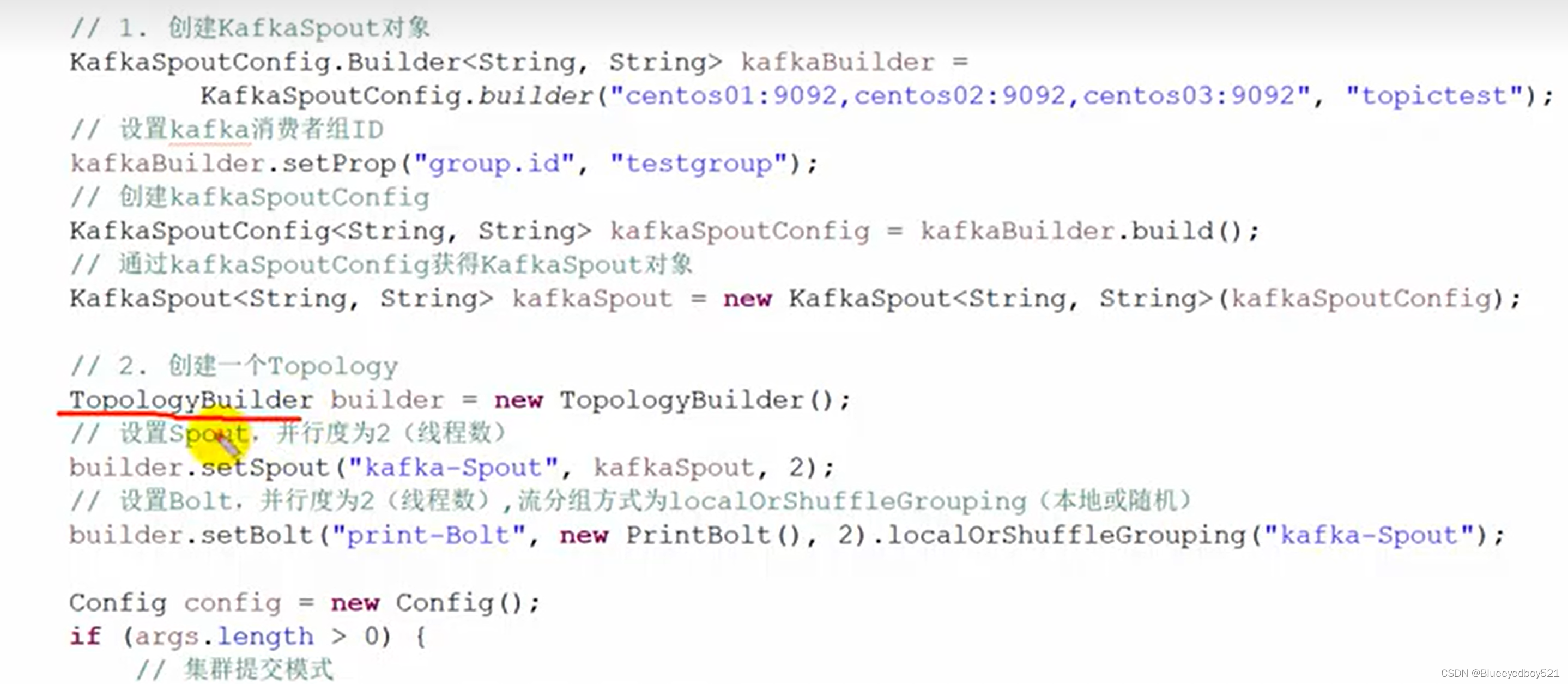

PrintBolt.java