本文主要依据
Pytorch 中LSTM官方文档
,对其中的
模型参数
、
输入
、
输出
进行详细解释。
目录
基本原理
首先我们看下面这个LSTM图, 对应于输入时间序列中每个步长的LSTM计算。
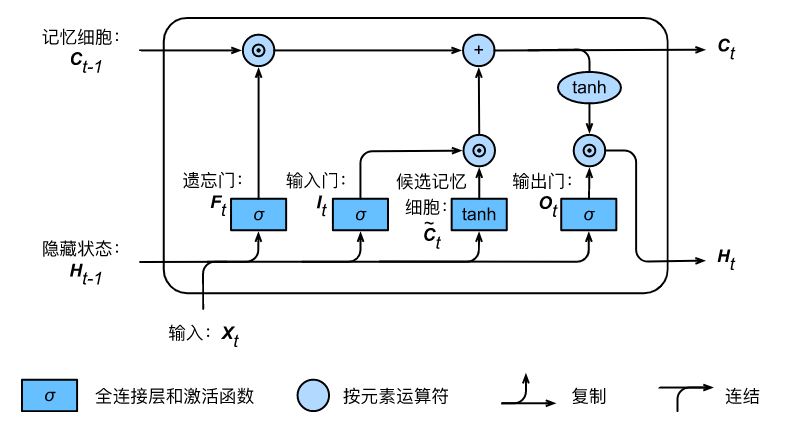
对应的公式计算公式如下:
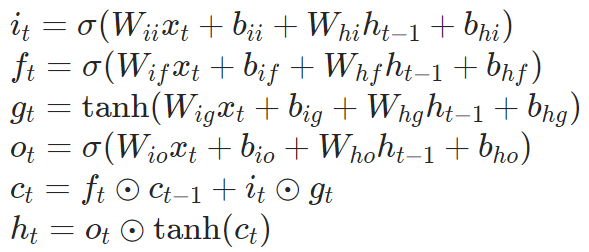
其中
表示时刻
时刻的隐含状态,
表示时刻
上的记忆细胞,
表示时刻
的输入(
对应于单个样本
),
表示隐含层在时刻
的隐含状态或者是在起始时间o的初始隐含状态,
,
,
表示对应的输入、遗忘、 输出门。σ 表示的是sigmoid 函数,⊙ 表示哈达玛积(Hadamard product)。
对于含多个隐含层的LSTM,第
层(
)的输入
则对应的是前一层的隐含状态
与丢弃dropout
的乘积,其中每一个
是Bernoulli随机变量(以参数dropout 的概率等于0)。
如果参数指定proj_size > 0,则将对LSTM使用投影。他的运作方式包括以下几步。首先,
的维度将从hidden_size 转换为proj_size (
的维度也会同时被改变)。第二,每一个层的隐含状态输出将与一个(可学习)的投影矩阵相乘:
。注意,这种投影模式同样对LSTM的输出有影响,即变成proj_size.
模型参数 Parameters
- input_size
-- 输入变量x的特征数量 - hidden_size
-- 隐含层h的特征数量(即层中隐含单元的个数) - num_layers
-- 隐含层的层数,比如说num_layers =2, 意味着这是包含两个LSTM层,默认值:1 - bias
-- 如果为False, 表示不使用偏置权重 b_ih 和 b_hh。默认值为:True - batch_first
-- 如果为True,则输入和输出的tensor维度为从(seq, batch, feature)变成 (batch, seq, feature)。 注意,这个维度变化对隐含和细胞的层并不起做用。参见下面的Inputs/Outputs 部分的说明,默认值:False - dropout
-- 如果非0,则会给除最后一个LSTM层以外的其他层引入一个Dropout层,其对应的丢弃概率为dropout,默认值:0 - bidirectional
-- 如果为True,则是一个双向的(bidirectional )的LSTM,默认值:False - proj_size
-- 如果>0, 则会使用相应投影大小的LSTM,默认值:0
输入Inputs: input, (h_0, c_0)
- input:
当batch_first = False 时形状为(
L,N,H
_in),当 batch_first = True 则为(
N, L, H
_in) ,包含批量样本的时间序列输入。该输入也可是一个可变换长度的时间序序列,参见
torch.nn.utils.rnn.pack_padded_sequence()
或者是
torch.nn.utils.rnn.pack_sequence()
了解详情。 - h_0
:形状为(
D∗num_layers, N,
H
_out),指的是包含每一个批量样本的初始隐含状态。如果模型未提供(
h_0, c_0
) ,默认为是全0矩阵。 - c_0
:形状为(
D∗num_layers, N, H
_cell), 指的是包含每一个批量样本的初始记忆细胞状态。 如果模型未提供(
h_0, c_0
) ,默认为是全0矩阵。
其中:
N
= 批量大小
L
= 序列长度
D
= 2 如果模型参数bidirectional = 2,否则为1
H
_in = 输入的特征大小(input_size)
H
_cell = 隐含单元数量(hidden_size)
H
_out = proj_size, 如果proj_size > 0, 否则的话 = 隐含单元数量(hidden_size)
输出Outputs: output, (h_n, c_n)
- output
: 当batch_first = False 形状为(
L, N, D∗H
_out) ,当batch_first = True 则为 (
N, L, D∗H
_out) ,包含LSTM最后一层每一个时间步长
的输出特征(
)。如果输入的是
torch.nn.utils.rnn.PackedSequence
,则输出同样将是一个packed sequence。 - h_n
: 形状为(
D∗num_layers, N, H
_out),包括每一个批量样本最后一个时间步的隐含状态。 - c_n
: 形状为(
D∗num_layers, N, H
_cell),包括每一个批量样本最后一个时间步的记忆细胞状态。
变量Variables
- ~LSTM.weight_ih_lk
-- 学习得到的第k层的 input-hidden 权重 (W_ii|W_if|W_ig|W_io),当k=0 时形状为 (4*hidden_size, input_size) 。 否则,形状为 (4*hidden_size, num_directions * hidden_size) - ~LSTM.weight_hh_lk
--学习得到的第k层的 hidden -hidden 权重(W_hi|W_hf|W_hg|W_ho), 想形状为 (4*hidden_size, hidden_size)。如果 Proj_size > 0,则形状为 (4*hidden_size, proj_size) - ~LSTM.bias_ih_lk
-- 学习得到的第k层的input-hidden 的偏置 (b_ii|b_if|b_ig|b_io), 形状为 (4*hidden_size) - ~LSTM.bias_hh_lk
-- 学习得到的第k层的hidden -hidden 的偏置 (b_hi|b_hf|b_hg|b_ho), 形状为 (4*hidden_size) - ~LSTM.weight_hr_lk
-- 学习得到第k层投影权重,形状为 (proj_size, hidden_size)。仅仅在 proj_size > 0 时该参数有效。
备注
- 所有的权重和偏置的初始化方法均取值于:

- 对于双向 LSTMs,前向和后向的方向分别为0 和1。当batch_first = False 时,对两个方向的输出层的提取可以使用方式:output.view(seq_len, batch, num_directions, hidden_size)。
- 具体怎么使用,可以参考本人博文
从零开始实现,LSTM模型进行单变量时间序列预测 - 关于LSTM模型的结构如果还有不清晰的可以参考这篇博客:
Pytorch实现的LSTM模型结构