一.k-最近邻算法步骤
1.选择适当的k值。它表示在预测新的数据点时要考虑的邻居数量。
2.计算距离。计算未知点与其他所有点之间的距离。常用的距离计算方法主要有欧氏距离,曼哈顿距离等。
3.选择邻居。在训练集中选择与要预测的数据点距离最近的k个邻居。
4.预测响应。统计这k个邻居中各类别的数量,并将要预测的数据点预测为这k个邻居中数量最多的类别。
下面以使用K-最近邻算法预测糖尿病(不需要特征标准化)为例说明k-最近邻算法的使用。
二.导入库和数据集
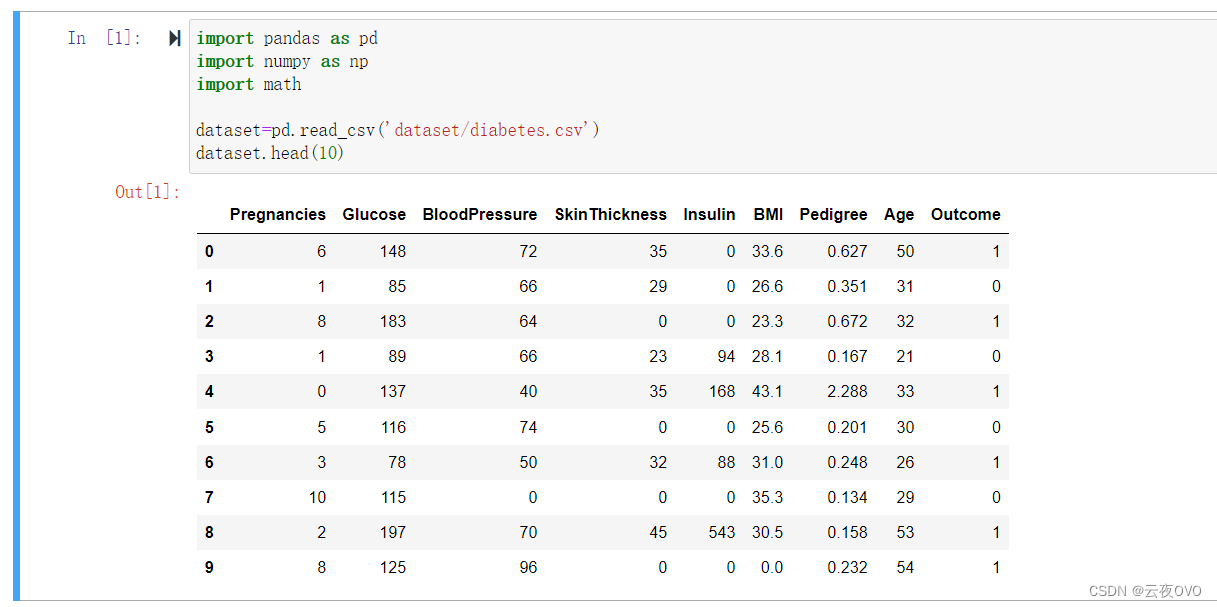
其中变量的中文含义如下:
Pregnancies:怀孕次数
Glucose:葡萄糖测试值
BloodPressure:血压
SkinThickness:皮肤厚度
Insulin:胰岛素
BMI:身体质量指数
Predigree:糖尿病遗传函数
Age:年龄
Outcome:糖尿病标签(即预测结果)
三.数据清洗
可以看到在上一步中某些列均出现了异常值0,此时需要进行数据清洗把异常值先替换为NaN,然后用该列的平均值填充。
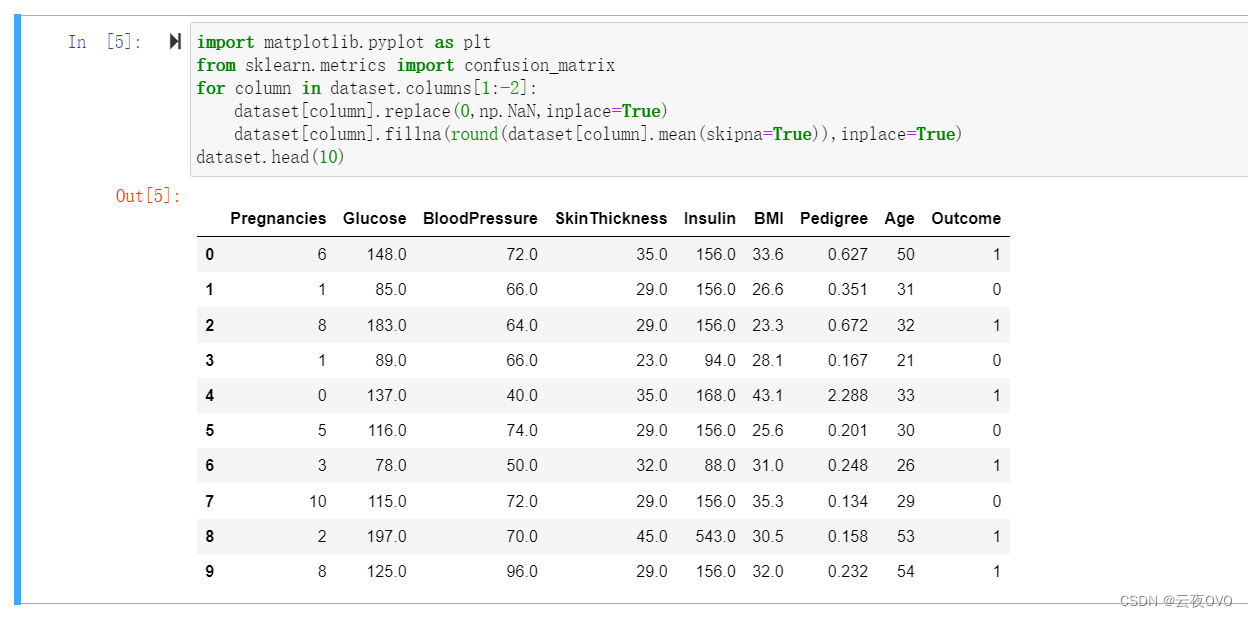
四.划分测试集和训练集
先获取x,y如下。
然后进行训练集和测试集的划分,依旧是训练集占80%,测试集占20%。打印x的测试集如下。
五.模型训练
由于本数据集的自变量之间的数量级差别不是很大,故不需要使用特征标准化。
先导入k-最近邻分类器,再开始在训练集上训练模型

六.预测结果并输出混淆矩阵

混淆矩阵可视化如下:
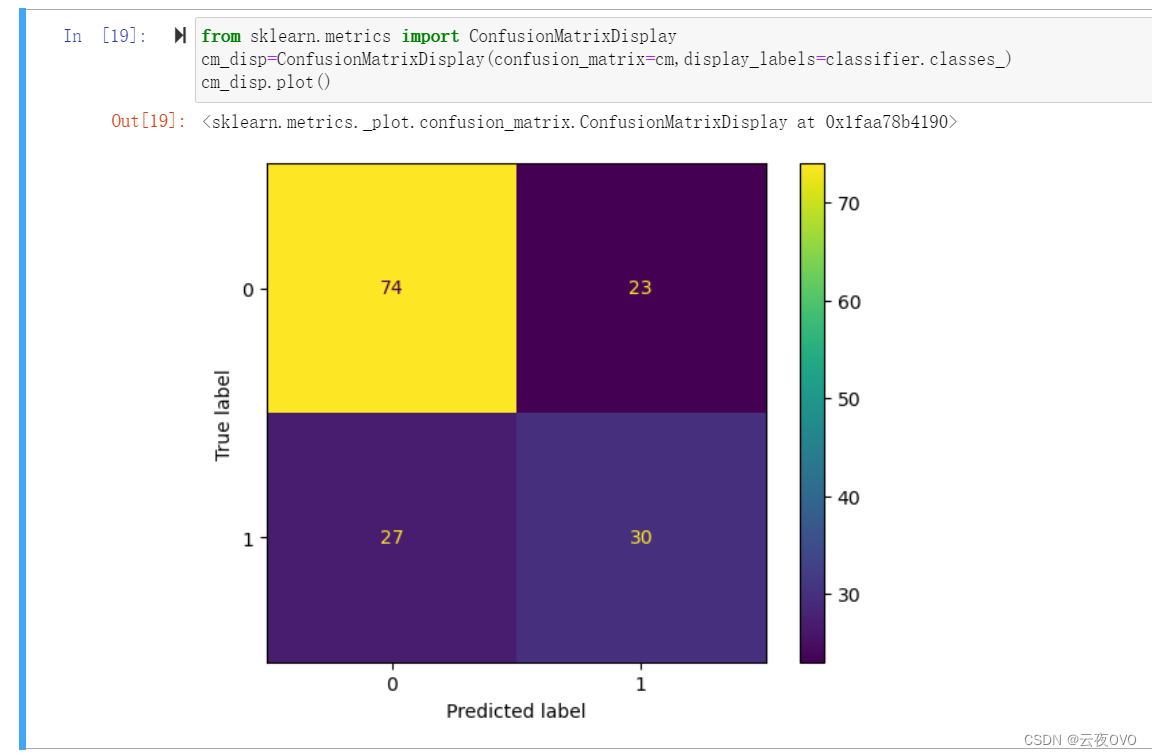
采用准确率(Accurancy),精确率(precision),召回率(Recall),F1分数(F1 score)来评估模型。

模型的准确率、精确率、召回率和 F1 分数都在 50% 到 70% 之间,说明模型有一定的预测能力,但效果并不是特别好。
因此,我们尝试改进模型。
七.尝试优化
试着采用改变K值的方法。
 把k值设置为6,运行。得到混淆矩阵如下。
把k值设置为6,运行。得到混淆矩阵如下。

可视化如下:
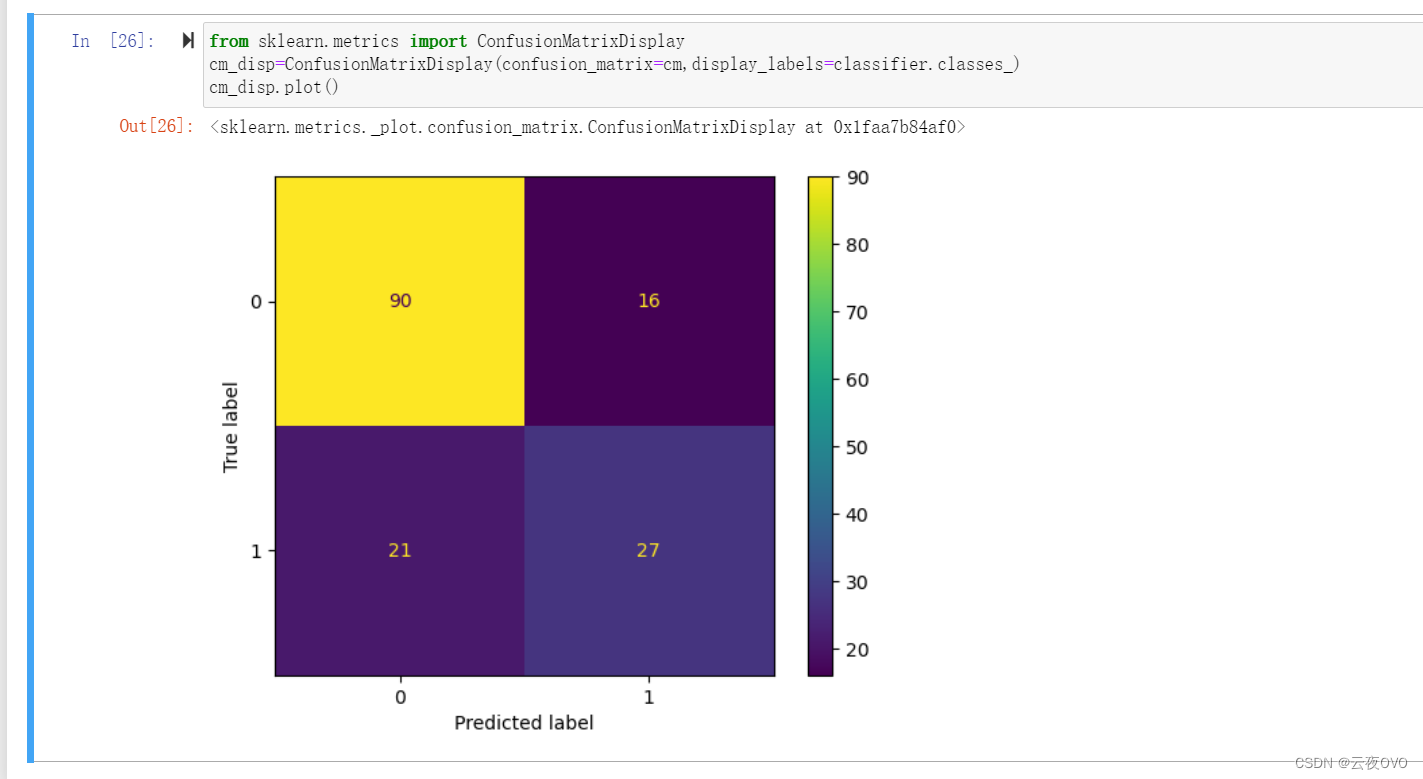
接下来计算指标值。
 模型的准确率、精确率、召回率和 F1 分数都在 50% 到 80% 之间,说明模型有较好的预测能力,但仍有改进空间。
模型的准确率、精确率、召回率和 F1 分数都在 50% 到 80% 之间,说明模型有较好的预测能力,但仍有改进空间。
至于后续的优化,可能就需要继续调整k值或者采用其他的分类算法了,在这里不做过多讨论。
欢迎各位大佬批评指正,别忘了点赞加关注喔~