
业务场景需求
long long ago:
在项目的运维过程中有一次SEO团队提出 网页的URL 中如果可以带上关键字,那么网页在各大搜索引擎中收录和排名有非常重大的突出优势(~~SEO团队到底专不专业 ~~,此处不做置评),遂业务方决定,项目的CMS系统中增加修改页面URL的功能(不是什么大事,甲方爸爸要求了就加了)。
功能增加后,业务人员笃信此内容有效果,一天增删改好几遍,对于搜索引擎收录后的页面修改URL后要求增加301或302跳转,确保对搜索引擎友好。(虽然一天改那么多遍,到底友好在哪儿 我也不知道,不予置评)
因为项目架构涉及到多层级CDN分发,网站内容静态化管理,流量资源控制等情况,采用的是将变更URL的301映射定期存储在配置文件中进行reload的方式,为确保系统稳定,选择了每日更新的情况。
now :
外来的运维团队对实时性情况要求逐渐提升,要求立马生效,遂寻求了此解决方案。
在这个业务场景的解决问题上,我是在mac本地进行的流程验证和测试,旨为梳理思路和流程。在其他平台,也可以找到对应的方式。(官方文档和教程中都有我就不赘述了)
OpenResty = Nginx+Lua
因为web服务器一直使用的是Nginx,在项目中也有对Nginx源码的改造需求在,所以在此解决方案中选择了OpenResty。
OpenResty是通过Lua 扩展Nginx 实现的可伸缩的Web平台。可以理解为Web服务核心是Nginx,但是通过Lua的方式增加了很多的扩展功能,还是很Nice的。
Nginx 早年间推出了njs 模块,支持使用javascript的部分子集进行扩展,也是不错的方式,但是在Nginx的许多场景中NJS的扩展使用生态没有Lua的好一些,在解决问题和功能扩展上不如Lua容易,感谢社区和开源的大佬。
MacOS下安装 :
bash
brew install openresty/brew/openresty
需要注意
bash
brew install openresty #采用此命令是安装不了的,会说找不到安装后需要添加环境变量,以便Nginx 命令启动可以找到

brew安装后的地址(macOS)可以参考以下,其他的可能在/usr/local/openresty(这是默认地址)
PATH=/opt/homebrew/Cellar/openresty/1.25.3.1_1/nginx/sbin:$PATH
export PATH之后创建Web服务所需的工作区
mkdir www logs conf
创建工作区这一步是因为我在全新的环境终验证流程所需,在已有的项目中,可以依据自身的情况进行配置即可,后续的命令是在nginx-lua-redis目录下执行的,如果切换到了别的目录,注意一些命令中所需的文件路径的变更。
在conf文件夹下新建一个示例配置Nginx.conf
lua
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
server {
listen 8080;
location / {
default_type text/html;
content_by_lua_block {
ngx.say("<p>hello, world</p>")
}
}
}
}然后启动Nginx 服务:
bash
nginx -p `pwd`/ -c conf/nginx.conf如果说找不到文件,就检查一下自己所在路径是否正确。
测试:
curl http://localhost:8080/结果:
<p>hello, world</p>此时在nginx-lua-redis目录下会自动生成其他web服务所需的相关文件,可以不必理会。
此时Nginx+Lua环境就可以使用了,这里得益于OpenResty项目的集成,如果采用Nginx + Lua模块及其他扩展的安装会稍显麻烦,毕竟还有许多依赖和听都没听过得许多模块要学习和了解...... OpenResty本身已经集成了大多是扩展所需,Nice +1.
Redis 支持
为什么这个方案中用Redis?因为官网说它快......
Redis在mac上安装也是相对简单
brew install redis
brew services start redis
redis-server
Ok,Redis 的简单实例就搭好了
新开终端窗口测试链接:
redis-cli -h 127.0.0.1 -p 6379因为是流程验证和测试,不想写为Redis写什么代码,直接从官网下载了支持Mac的免费客户端 :
RedisInsight https://redis.io/insight/
完全傻瓜化的操作,而且界面也很好看
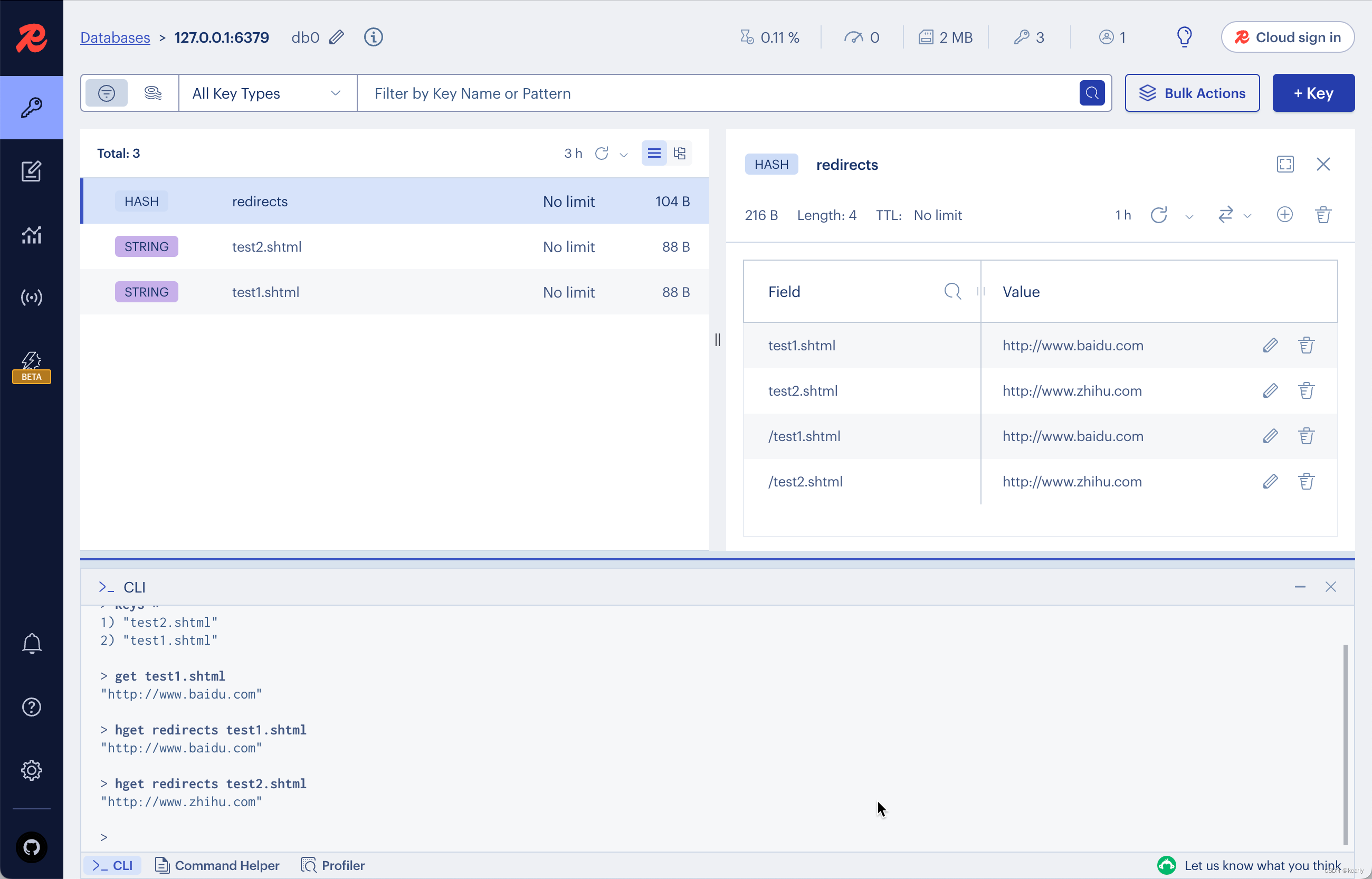
在这里我尝试创建了两组页面跳转的实例,最终选择了HASH的模式.在自带的终端中创建了百度和知乎的跳转键值对用作后续的测试。
Redis中不同的数据类型操作方式不同,选择不同的数据类型在Lua脚本调用时需要进行调整。
Lua调用Redis中数据匹配跳转规则时,传入的URL数据是从
"/"开始的,这也是为什么截图中有两组数据的原因(第一组我忘记这个事儿了,所以失败了,然后才想起来😭)
配置文件案例
Nginx + Lua脚本的实现是比较轻松地,只要了解了语法写起来就很轻松。这个实例的核心就是Nginx 在 匹配的URL 规则时,通过Lua脚本 调用后端Redis 中存储的301跳转规则,而不是之前写在配置文件中固定规则。通过对Redis的操作,来实时进行规则内容的更新。
lua
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
lua_shared_dict redirects_cache 3m; # 分配1MB共享内存用于缓存
server {
listen 8080;
location / {
access_by_lua_block {
local redis = require "resty.redis"
local red = redis:new()
red:set_timeout(1000) -- 设置超时时间
local ok, err = red:connect("127.0.0.1", 6379)
if not ok then
ngx.log(ngx.ERR, "failed to connect to redis: ", err)
return ngx.exit(ngx.HTTP_INTERNAL_SERVER_ERROR)
end
-- 尝试从缓存中获取跳转规则
local cached_redirect = ngx.shared.redirects_cache:get(ngx.var.uri)
if cached_redirect then
ngx.redirect(cached_redirect, 301)
return
end
-- 查询Redis
local new_url = red:hget("redirects", ngx.var.uri)
if type(new_url)=="string" then
-- 缓存结果以加速后续请求
ngx.shared.redirects_cache:set(ngx.var.uri, new_url, 600) -- 缓存600秒
red:close() -- 关闭连接
ngx.redirect(new_url, 301)
return
end
red:close()
}
default_type text/html;
content_by_lua_block {
ngx.say("<p>hello, world. nginx-lua-Redis</p>")
}
}
}
}redirects_cache:设置一个缓存区,毕竟每次都去查Redis也是要消耗的,缓存之后消耗会少一些,缓存多大要看项目中需要的301规则有多少。
通过访问预设的地址都可以正常跳转
localhost:8080/test1.shtml -> 正确的去了百度
localhost:8080/test2.shtml -> 正确的去了知乎在对Redis 中数据进行更新后,跳转效果也可以实时生效。
后记:
关于Nginx 热加载 reload:
Nginx本身是提供热加载的 :
nginx -s reload这也是我们之前自动化所采用的方式。在实际使用中,大流量或者长链接保持情况下,reload的方式式经常会出现一些意外情况,比如服务中断,reload失败等等。所以在早期的方案中我们实际是高可用集群切换来保障自动更新的效果。但是目前业务方热衷于频繁修改URL跳转规则,并要求在短时间内立马生效。采用 Reload的方式对 平台业务服务的稳定性增加了较多隐患,可能这次集群Reload还没结束,下次又开始了,对于系统消耗和稳定性的考虑才决定尝试验证Nginx+Lua+Redis的方案。
方案的局限性 :
这个方案的产生和测试,都是基于在手的一个项目业务情况和环境需求所产生的,并不是说这是一个非常完善或者普适性的方案,它只解决我所处情况的问题,这里做的总结只是做一个思路梳理和验证,实际的项目中要依据自身情况进行。如有更好的方法和意见,欢迎批评指正。