前言
经过之前几节内容,我们的架构已经变为,nginx->envoy->backend,并且envoy作用sidecar,与nginx在同一个pod中工作,但是现在有个问题,nginx将流量转发到envoy,需要修改nginx的配置文件
upstream backend_ups {
server 127.0.0.1:10000; # 原配置 backend_service:10000
}
server {
listen 80;
listen [::]:80;
server_name localhost;
location /test {
proxy_pass http://backend_ups;
}
}从两个方面来说:
- 部署层不应该依赖于业务层的配置,要将该配置解耦
- 底层转发对于业务层应该是无侵入的,不应该侵入业务层的代码或者配置,业务层不需要关心流量怎么转发
基于此,本文就来讨论一下,如何在不修改业务层nginx配置的情况下,envoy怎么劫持业务流量
原nginx配置文件:
upstream backend_ups {
server backend-service:10000;
}
server {
listen 80;
listen [::]:80;
server_name localhost;
location /test {
proxy_pass http://backend_ups;
}
}环境准备
如果之前一直跟着操练的同学,可以重置一下测试环境: envoy测试环境
修改域名映射
使用hostAliases,将本来应该指向后端服务的backend_service换成指向本地127.0.0.1的envoy即可
修改nginx的pod编排文件
...
hostAliases:
- hostnames:
- backend-service
ip: 127.0.0.1
# 注意和containers一个级别
containers:
...
...这种做法简单有效,但是有2个问题:
- 如果backend的端口和envoy的代理端口不一样,那就不能用。而在我们的这个例子中,envoy的代理端口和后端的服务端口,恰好都是10000,可以使用
- 域名映射是pod级别的,会让所有的containers生效,nginx转发的名字与envoy转发的名字不能是同一个。在我们的例子当中,nginx的upstream转发配置是
backend-service,envoy的转发配置是backend-headless-service,恰好不同,可以使用
由此可知,该方法是最简单的流量劫持,通过host映射,将流量转发至envoy,但是限制太大,一旦上述2个条件不满足,是没法使用该方法的
使用iptables
到这里,又要请出iptables了,作为老演员,iptables在前面(利用iptables记录后端ip)就出场过,现在又需要了
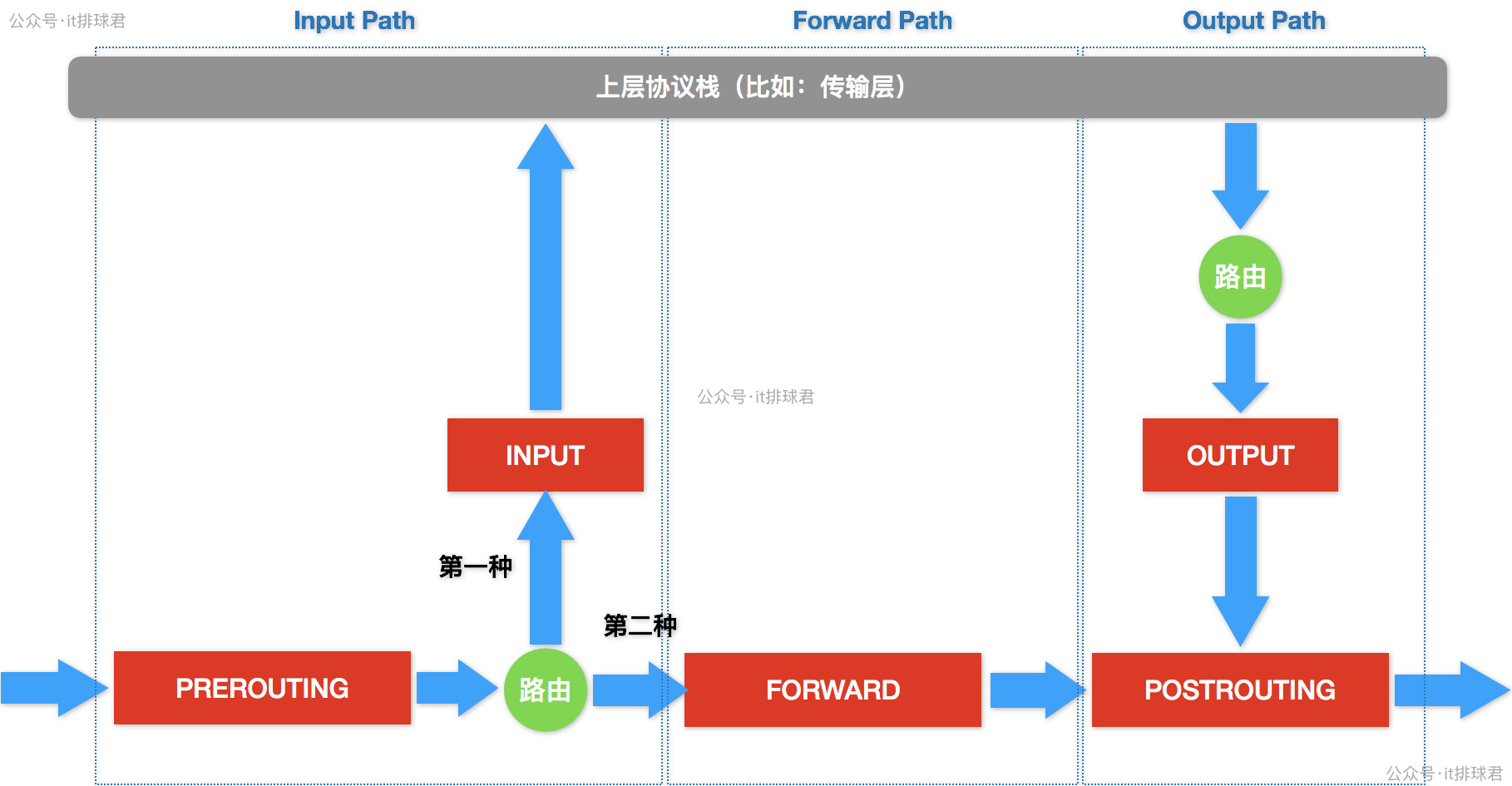
先来个高清大图镇场
劫持所有的出流量
- 要将所有从nginx发送到backend-service:10000的流量劫持到envoy中(127.0.0.1:10000),通过iptables可以完成
- 由于本文中,后端服务backend与envoy监听的都是同一个10000端口,所以需要做特殊的处理
-
目标端口为10000的端口,并且目标ip非127.0.0.1的流量,都要转发到本地的10000端口
iptables -t nat -A OUTPUT -p tcp --dport 10000 ! -d 127.0.0.1/32 -j REDIRECT --to-ports 10000 -
由于端口都是10000,所以需要拦截nginx发送的,而放行envoy发出的,否则就要打环了。通过uid来确认envoy发出的流量
▶ kubectl exec -it nginx-test-557df7457b-dr7sf -c envoy -- id envoy uid=101(envoy) gid=101(envoy) groups=101(envoy) iptables -t nat -A OUTPUT -m owner --uid-owner 101 -j RETURN
-
整理一下最终的版本(注意顺序):
iptables -t nat -A OUTPUT -m owner --uid-owner 101 -j RETURN
iptables -t nat -A OUTPUT -p tcp --dport 10000 ! -d 127.0.0.1/32 -j REDIRECT --to-ports 10000
root@wilson:/home/wilson/workspace# iptables -L -n -t nat
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
RETURN all -- 0.0.0.0/0 0.0.0.0/0 owner UID match 101
REDIRECT tcp -- 0.0.0.0/0 !127.0.0.1 tcp dpt:10000 redir ports 10000
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination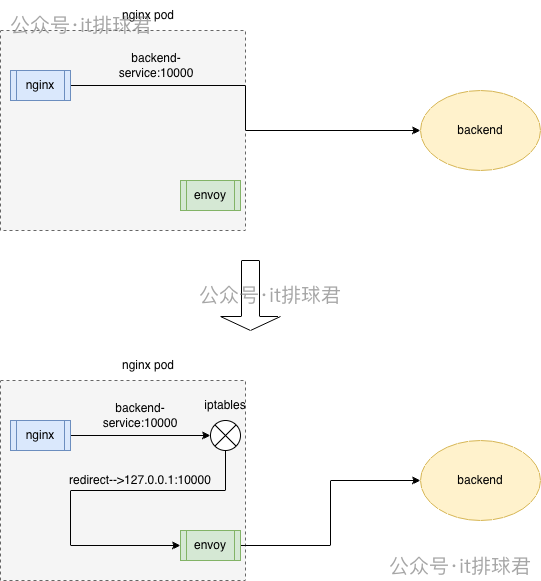
但并不是所有的容器都可以使用iptables这个命令的,所以为了调试方便,我们使用nsenter进入
利用nsenter进入container
-
找到nginx容器id
▶ sudo crictl ps | grep nginx-test 091f9a85ba53e 49b0af0078643 30 minutes ago Running envoy 0 ac7556e89b5b3 nginx-test-557df7457b-dr7sf default 6b143efde5b0f 7f553e8bbc897 30 minutes ago Running nginx-test 0 ac7556e89b5b3 nginx-test-557df7457b-dr7sf default -
找到容器对应的pid
▶ sudo crictl inspect 6b143efde5b0f | grep -i pid "pid": 1, "pid": 1569896, "type": "pid" -
进入容器
▶ sudo nsenter -n --target 1569896 -
之后开始执行iptables命令即可
验证是否能够劫持流量
执行curl 10.22.12.178:30785/test,并且查看nginx日志
10.244.0.1 - - [26/Dec/2025:02:15:43 +0000] "GET /test HTTP/1.1" 200 10.105.148.194:10000 40 "-" "curl/7.81.0" "-"确实已经有日志进入nginx,但是再查看envoy的时候,空空如也,说明流量并没有被转发至envoy
问题排查
由于环境特殊,envoy和backend都是10000端口,所以规则里面新加了一条,只要是uid为101,全部都放行,不再匹配后面的规则
RETURN all -- 0.0.0.0/0 0.0.0.0/0 owner UID match 101从目前的现象来看,所有的出流量都命中了这条规则,全部被放行了,赶紧去检查一下nginx启动用户的uid
▶ kubectl exec -it nginx-test-557df7457b-dr7sf -c nginx-test -- id nginx
uid=101(nginx) gid=101(nginx) groups=101(nginx)问题找到!由于envoy用户与nginx用户都用101作为uid,导致iptables规则全部放过了,那要解决这个问题,有几种方法:
-
最简单最直接的,用另外一个uid作为envoy的uid
name: envoy # 和container name一个级别 ... securityContext: runAsUser: 1234 -
在打docker镜像的时候指定uid,这个是最好的方案,彻底隔离开pid
由于在调试阶段,我们使用第一种方案,临时换pid
有位老哥要问了,为什么同一个pod里面可以有相同的uid呢?因为每个容器有自己的pid namespace,所以就算在容器里面,他们依然试隔离开的,当然也可以直接配置共享同一个pid namespace:shareProcessNamespace: true
最终结果
[2025-12-26T03:35:12.708Z] "GET /test HTTP/1.0" 200 40 1 856d3200-abb3-486f-8e4c-8441f20bdbb0 "curl/7.81.0" "-" 10.244.0.114:10000 app_service -
[2025-12-26T03:35:12.937Z] "GET /test HTTP/1.0" 200 40 1 271f828e-5bd0-4fa1-95dc-3f17364ba8b8 "curl/7.81.0" "-" 10.244.0.111:10000 app_service -流量终于被iptables转发至envoy,并且转发到后端的backend去了
使用initContainers配置
上面已经验证了,通过iptables可以劫持相关流量,而业务层不需要做改变即可完成。现在需要将这一套方法变成实际可行的工程方案,并且自动执行,不可能每次都人工修改
使用initContainers,让每一个pod启动都优先处理iptables配置
initContainers:
- args:
- |
apk add --no-cache iptables
iptables -t nat -A OUTPUT -m owner --uid-owner 1234 -j RETURN
iptables -t nat -A OUTPUT -p tcp --dport 10000 ! -d 127.0.0.1/32 -j REDIRECT --to-ports 10000
command:
- /bin/sh
- -c
image: alpine:3.23
imagePullPolicy: Always
name: iptables-init
resources: {}
securityContext:
privileged: true这里不太优雅的是该容器每次都要先安装iptables,可以自己打一个镜像,预装好iptables
拦截入口流量
上述描述的是离开nginx的流量,使用iptables output链完成。比如有个需求是需要拦截如的流量,那也很简单,只需要在prerouting链上编写规则即可。掌握iptables之后,就能融会贯通了
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 10000
iptables -t nat -A OUTPUT -m owner --uid-owner 1234 -j RETURN第一条规则就是所有来访问80端口的请求都会重定向到127.0.0.1:10000去。而第二条规则保证了,从envoy发出的请求不会被任何劫持,还是避免打环
小结
本文详细描述了怎么使用iptables来劫持流量,让业务层无感的方式将流量转发到envoy,这已经将部署层与业务层解耦,业务完全不需要关心底层运行逻辑。Istio的底层正是使用iptables来实现流量拦截和重定向的。离手搓istio又近了一步,当然是开玩笑,本系列的重点还是一步一步去理解服务治理要解决的问题以及选择对应的方案来匹配自己的系统
但是这里又提出一个问题,这要反复折腾,让流量不断的从kernel space 与user space中来回穿梭
业务层nginx --> iptables --> envoy(User space) --> iptables
消耗了大量系统资源,在一个高并发的系统当中,这是非常浪费资源的情况,那这种情况该怎么办呢?这是很后后后面的东西了,我们先把其他简单的问题解决再来讨论这种优化的问题
后记
关于不同的uid的问题,nginx为101,envoy也是101,如果在这种情况下强行配置shareProcessNamespace: true,会发生什么事情?
containers: # 注意是containers级别的
...
shareProcessNamespace: true登录进去看看
▶ kubectl exec -it nginx-test-54f5b78d57-x4kmj -c envoy bash
root@nginx-test-54f5b78d57-x4kmj:/# ps -ef
UID PID PPID C STIME TTY TIME CMD
65535 1 0 0 03:09 ? 00:00:00 /pause
root 7 0 0 03:09 ? 00:00:00 nginx: master process nginx -g daemon off;
envoy 27 0 0 03:09 ? 00:00:00 envoy -c /etc/envoy/envoy.yaml
envoy 33 7 0 03:09 ? 00:00:00 nginx: worker process
envoy 34 7 0 03:09 ? 00:00:00 nginx: worker process可以看到,所有的用户都在一个pid namespace下面,并且101用户既启动了nginx,又启动了envoy,由于我登录的envoy container,所以看到了用envoy启动了nginx,如果使用nginx登录,那肯定是用nginx启动了envoy
这样做了感觉降低了namespace的隔离性,并且信号处理混乱,因为容器的1号进程往往可以接收到k8s的各种信号量,如果全部堆在一个namespace,需要做好信号量传递,更是增加了复杂度
所以共享pid namespace,是需要做好评估的