作为VLM系列的第一篇文章,打算以LLaVA入手,毕竟是VLM领域较为经典的工作。
1. 核心贡献
- 多模态指令跟随数据:包括PT、SFT数据的构造流程;
- 大型多模态模型:一种新的框架,结构较为简单高效;
- 评估数据集;
2. 模型架构与重建目标
2.1 模型架构
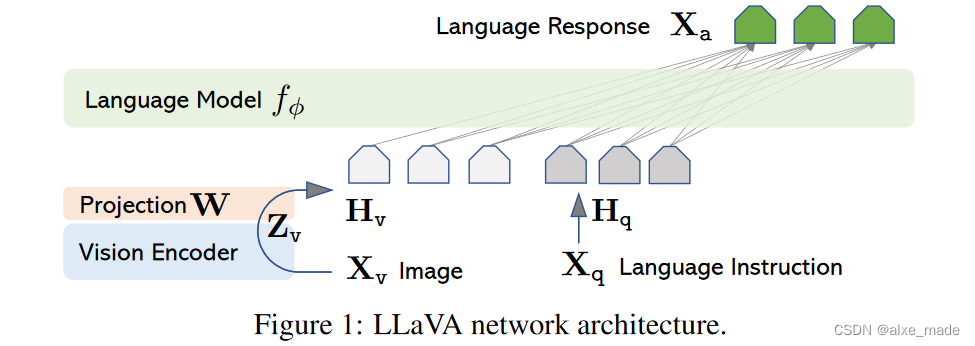
核心思想就是将视觉特征嵌入到LLM中,作为LLM的prefix(前缀),LLM作为建模的主体。
- 首先输入的
Xv经过一个vision encoder,比如open-clip等, siglip-so400m-patch14-384,抽取图像特征; - 得到
Zv经过一个ProjectW,这个是将视觉特征和LLM进行特征对齐,当然这里的对齐是比较简单,后续的工作包括一些Lora方式(CogView)等; - 经过project得到的
Hv转换特征和来自Xq经过embedding得到的Hq进行拼接,一起送到LLM中,比如Vicuna;
2.2 训练流程
- PT阶段:仅训练Projecter,视觉和LLM固定;
- SFT阶段: 训练Projecter和LLM,视觉固定;
当然你会想为什么这么设计,为什么是需要两阶段?一阶段不行吗? 以及视觉为什么不训练? 当然这些实验后续的工作也进行设计,我们后面的一些文章应该会涉及到;
2.3 重建目标
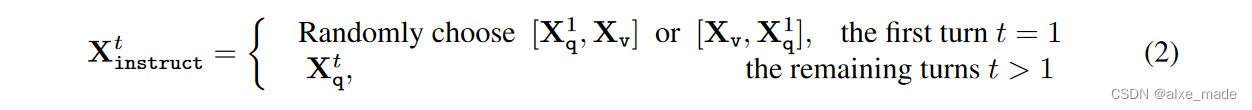
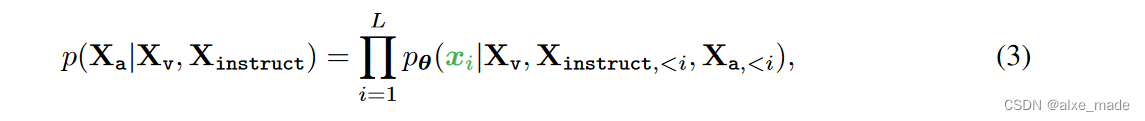

在第一次看这些公式以及重建的目标的时候,自己理解其实是不深刻的,为什么要这么设计,特别是看到仅绿色的序列或者token参与Loss计算的时候,还是有点懵的,自回归的Loss到底是什么了?
之前也阅读了LLava的代码,可能结合代码会有着更加深刻的认识,这里简单的介绍几点。
2.3.1 Conversion
这个是llava代码中比较关键的部分,地址为:llava/conversation.py
在PT和SFT脚本中,有个关键的区别就是有个--version 字段,它在PT和SFT阶段一般是不同的。在PT阶段一般设置的是plain,这个不同的LLM可能都是这个,而SFT阶段可能设置就不一样了,有设置llava_llama_2 、mistral_instruct 等。这个设置的不同的是主要是因为不同的LLM在训练时候使用的template是不同的,因为它需要控制不同的角色,比如system , user ,assistant , 这部分内容可参考:huggingface.co/docs/transformers/main/en/chat_templating
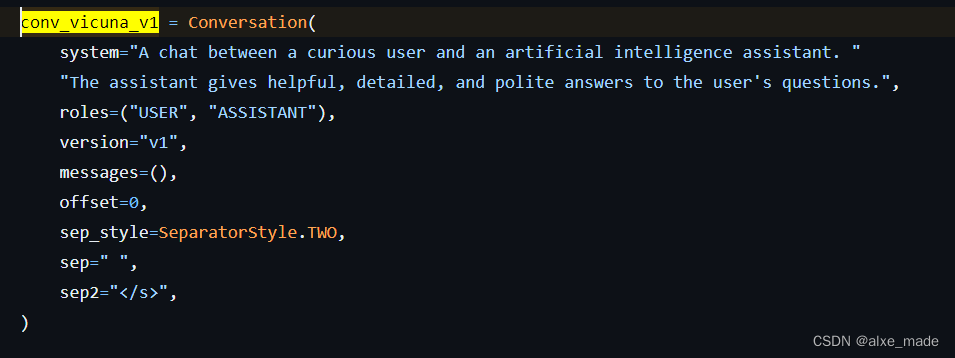
具体来看:
- 在PT阶段,使用
plain模板,最终在preprocess函数中使用preprocess_plain 本质上是直接将问题,变成<image>了, 因为PT默认使用的数据集是单轮的,经过CC3M过滤的图像描述数据集,PT阶段主要是视觉和LLM对齐;
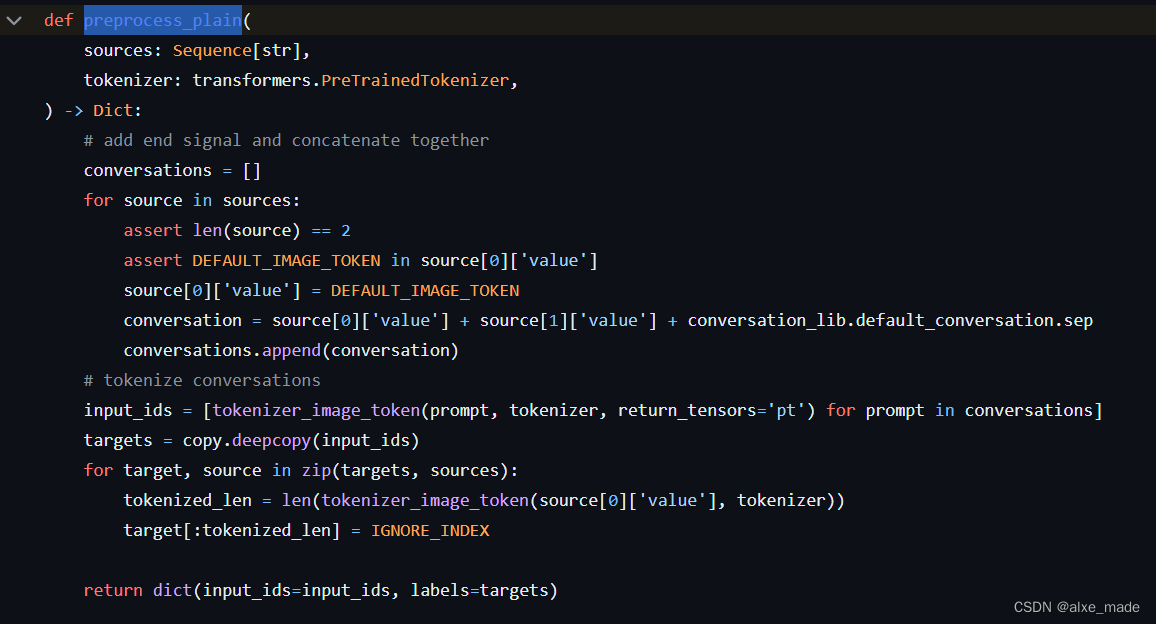
- SFT阶段:主要使用的

因为这里的情况稍微复杂一点,区分有图像和没有图像(可能只是纯文本作为SFT数据),那么有图像的话就将图像标记-200插入进去,只是在第一轮插入;最后的返回有两个,一个是input_ids一个是labels,那么label主要会有一个IGNORE_INDEX(-100),这个决定了哪些inputs_ids的数值在计算loss会被忽略。
2.3.2 LlavaMetaForCausalLM
这个函数是比较重要的,比如我们建模llava_llama 这个函数,
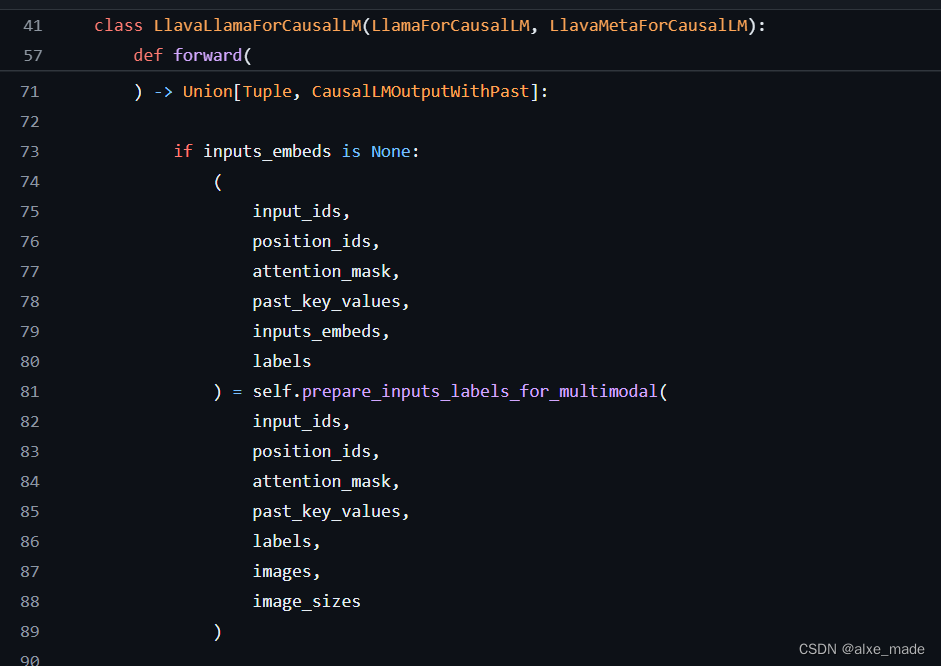
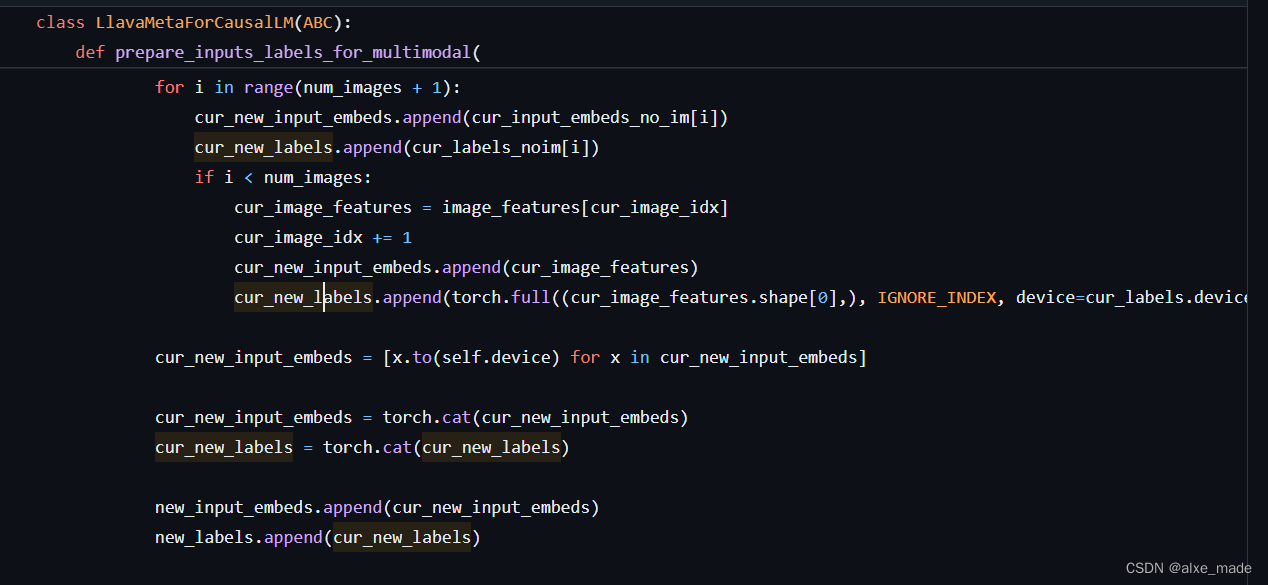
不同的LLM最后都通过多继承的方式继承LlavaMetaForCausalLM, 该类的核心就是将来自的视觉特征和LLM特征插入。因为这里不是使用input_ids,也是将其变成emdedding,然后将视觉特征进行插入。
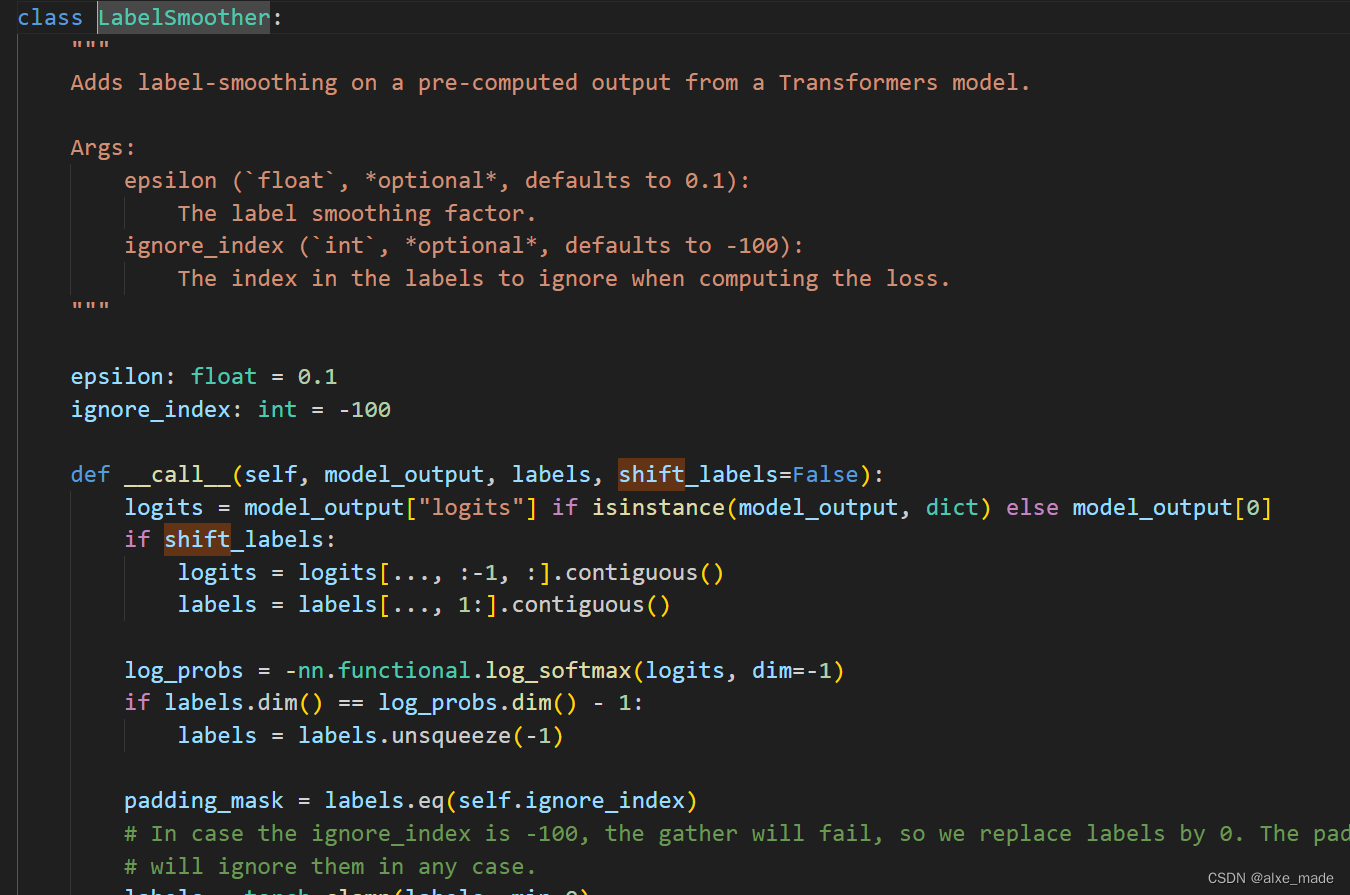
2.3.3 Loss计算
在训练代码中,其实没有显式的调用loss,它其实是用的shift loss进行计算的。-100 在这里就体现了。
3 数据构造
3.1 PT阶段
主要是在CC3M基础上进行过滤,使用Spacy 工具对名词性短语进行排序,核心的思想就是过滤出现频率太低的,同时也抑制出现频率太高的。
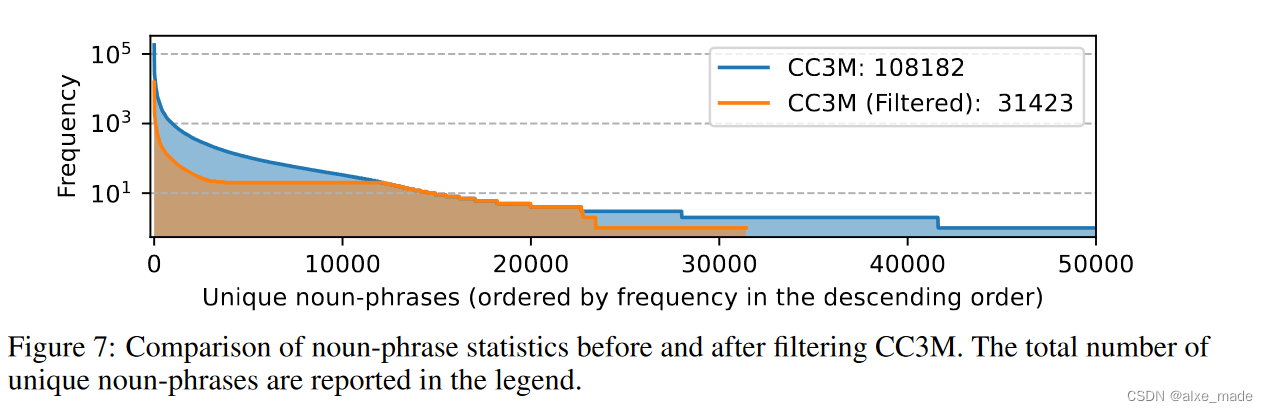
3.2 SFT阶段
主要是借助GPT-4(text-only)进行ICL学习构造样本。

- Conversation:对话数据,共 58K 个样本
- Detailed description:对图像丰富而全面的描述,共 23K 个样本
- Complex reasoning:复杂推理数据,数据的回复通常需要遵循严格的逻辑逐步推理,共 77K 个样本
Conversation 数据的构造思路如下:
- 给出一个 system prompt,要求 GPT4 根据提供的图片描生成多轮对话
- 提供几个示例,便于 GPT4 理解以及生成类似的多轮对话
- 将上面的内容输入给 GPT4,GPT4 返回多轮对话
这部分详细可参考:LLaVA(五)构造多模态数据 感觉讲的挺好,这里不在赘述了。
4 结果
结果还算可以。
